转换为状态机的正则表达式的简短示例?
在Stack Overflow播客#36(http://blog.stackoverflow.com/2009/01/podcast-36/)中,有人表达了这样的意见: 一旦你理解了设置状态机是多么容易,你就再也不会尝试不恰当地使用正则表达式了。
我做了很多搜索。我发现了一些学术论文和其他复杂的例子,但我想找一个简单的例子来帮助我理解这个过程。我使用了很多正则表达式,我想确保我再也不会“不恰当地”使用它。
6 个答案:
答案 0 :(得分:23)
当然,尽管您需要更复杂的示例来真正了解RE的工作原理。考虑以下RE:
^[A-Za-z][A-Za-z0-9_]*$
这是一个典型的标识符(必须以alpha开头,后面可以包含任意数量的字母数字和非字符字符,包括无字符)。以下伪代码显示了如何使用有限状态机完成此操作:
state = FIRSTCHAR
for char in all_chars_in(string):
if state == FIRSTCHAR:
if char is not in the set "A-Z" or "a-z":
error "Invalid first character"
state = SUBSEQUENTCHARS
next char
if state == SUBSEQUENTCHARS:
if char is not in the set "A-Z" or "a-z" or "0-9" or "_":
error "Invalid subsequent character"
state = SUBSEQUENTCHARS
next char
现在,正如我所说,这是一个非常简单的例子。它没有说明如何进行贪婪/不一致的匹配,回溯,一行(而不是整行)的匹配以及RE语法容易处理的状态机的其他更深奥的功能。
这就是RE如此强大的原因。执行单线程RE可以执行的实际有限状态机代码通常非常长且复杂。
您可以做的最好的事情是获取一些特定简单语言的lex / yacc(或等效)代码的副本,并查看它生成的代码。它不漂亮(它不一定是因为它不应该被人类阅读,它们应该是在查看lex / yacc代码),但它可以让你更好地了解它们是如何工作的。 / p>
答案 1 :(得分:21)
一种相当方便的方法来帮助我们看看这个在任何模式上使用python鲜为人知的re.DEBUG标志:
>>> re.compile(r'<([A-Z][A-Z0-9]*)\b[^>]*>(.*?)</\1>', re.DEBUG)
literal 60
subpattern 1
in
range (65, 90)
max_repeat 0 65535
in
range (65, 90)
range (48, 57)
at at_boundary
max_repeat 0 65535
not_literal 62
literal 62
subpattern 2
min_repeat 0 65535
any None
literal 60
literal 47
groupref 1
literal 62
'literal'和'range'之后的数字是指它们应该匹配的ascii字符的整数值。
答案 2 :(得分:19)
动态制作你自己!
http://osteele.com/tools/reanimator/???
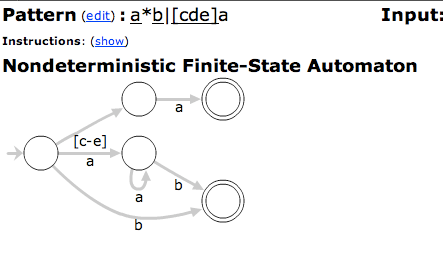
这是一个非常好的拼凑工具,它将正则表达式可视化为FSM。它不支持你在现实世界的正则表达式引擎中找到的一些语法,但肯定能够准确理解正在发生的事情。
答案 3 :(得分:4)
问题是“如何选择状态和转换条件?”或“如何在Foo中实现我的抽象状态机?”
如何选择状态和转换条件?
我通常使用FSM来解决相当简单的问题并直观地选择它们。在my answer to another question about regular expressions中,我只是将解析问题视为 Inside 或 outside 一个标记对,并写了从那里开始转换(具有开始和结束状态以保持实现清洁)。
如何在Foo中实现我的抽象状态机?
如果您的实现语言支持c的{{1}}语句之类的结构,那么您可以打开当前状态并处理输入,以查看接下来执行的操作和/或转换。
没有switch - 类似的结构,或者如果它们在某种程度上存在缺陷,你switch样式分支。 呃。
全部写在if的一个地方我链接的例子看起来像这样:
c这是非常混乱的,所以我通常会将token_t token;
state_t state=BEGIN_STATE;
do {
switch ( state.getValue() ) {
case BEGIN_STATE;
state=OUT_STATE;
break;
case OUT_STATE:
switch ( token.getValue() ) {
case CODE_TOKEN:
state = IN_STATE;
output(token.string());
break;
case NEWLINE_TOKEN;
output("<break>");
output(token.string());
break;
...
}
break;
...
}
} while (state != END_STATE);
个案例分解为单独的函数。
答案 4 :(得分:2)
我确定有人会有更好的例子,但是你可以check this post by Phil Haack,它有一个正则表达式的例子和一个状态机做同样的事情(之前的帖子里面还有一些正则表达式的例子)我认为..)
检查该页面上的“HenriFormatter”。
答案 5 :(得分:1)
我不知道你已经阅读过哪些学术论文,但理解如何实现有限状态机真的并不难。有一些有趣的数学,但想法实际上是非常微不足道的理解。理解FSM的最简单方法是通过输入和输出(实际上,这包括大部分正式定义,我将在此处不再描述)。 “状态”基本上只是描述已经发生并且可以从某一点发生的一组输入和输出。
通过图表最容易理解有限状态机。例如:
alt text http://img6.imageshack.us/img6/7571/mathfinitestatemachinedco3.gif
{kind=link}
所有这一切都在说,如果你开始处于某种状态q0(旁边有一个开始符号的状态),你可以转到其他状态。每个州都是一个圆圈。每个箭头代表一个输入或输出(取决于你如何看待它)。另一种考虑有限状态机的方法是“有效”或“可接受”输入。某些输出字符串不可能是某些有限状态机;这将允许你“匹配”表达式。
现在假设你从q0开始。现在,如果您输入0,您将进入状态q1。但是,如果您输入1,您将进入状态q2。您可以通过输入/输出箭头上方的符号看到这一点。
假设您从q0开始并获得此输入
0,1,0,1,1,1
这意味着你已经完成了状态(没有输入q0,你只是从那里开始):
q0 - &gt; q1 - &gt; q0 - &gt; q1 - &gt; q0 - &gt; q2 - &gt; q3 - &gt; Q3
如果没有意义,用手指追踪图片。请注意,对于输入0和1,q3都会返回自身。
说出这一切的另一种方式是“如果你处于状态q0并且你看到0转到q1,但如果你看到1转到q2。”如果您为每个州制定了这些条件,那么您几乎完成了定义状态机的工作。你所要做的就是有一个状态变量,然后是一个输入输入的方法,基本上就是那里。
好的,为什么这对乔尔的陈述很重要?好吧,建立“一切正常的表达以统治所有”可能非常困难,也很难维持修改甚至其他人回来理解。此外,在某些情况下,它更有效。
当然,状态机还有很多其他用途。希望这会有所帮助。注意,我没有理会进入理论,但有一些关于FSM的有趣证据。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?