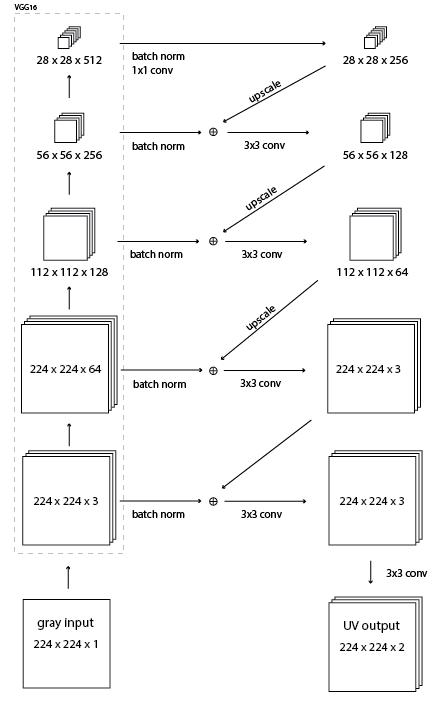
我正在尝试制作this image的模型。以下是相关代码:
Action: Set
Set: user-agent
Value: $(request.headers.user-agent)
我在目录中有一堆彩色图像。输入图像应该是图像堆叠三次(224x224x3)的灰度,base_model = VGG16(weights='imagenet')
conv4_3, conv3_3, conv2_2, conv1_2 = base_model.get_layer('block4_conv3').output,
base_model.get_layer('block3_conv3').output,
base_model.get_layer('block2_conv2').output,
base_model.get_layer('block1_conv2').output
# Use the output of the layers of VGG16 on x in the model
conv1 = Convolution2D(256, 1, 1, border_mode='same')(BatchNormalization()(conv4_3))
conv1_scaled = resize(conv1, 56)
.
.
.
conv5 = Convolution2D(3, 3, 3, border_mode='same')(merge([ip_img, conv4], mode='sum'))
op = Convolution2D(2, 3, 3, border_mode='same')(conv5)
for layer in base_model.layers:
layer.trainable = False
model = Model(input=base_model.input, output=op)
model.compile(optimizer='sgd', loss=custom_loss_fn)
应该是图像的UV平面(224x224x2),我可以将其添加到灰度(224x224x1)以获取YUV图像。自定义损失函数适用于原始图像的UV和预测的UV。
我该如何训练?
{kind=link}