如何在广度优先搜索中跟踪路径?
如何跟踪广度优先搜索的路径,例如在以下示例中:
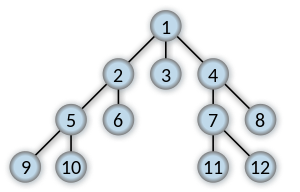
如果要搜索密钥11,请返回连接1到11的最短列表。
[1, 4, 7, 11]
6 个答案:
答案 0 :(得分:157)
您应该首先查看http://en.wikipedia.org/wiki/Breadth-first_search。
下面是一个快速实现,其中我使用列表列表来表示路径队列。
# graph is in adjacent list representation
graph = {
'1': ['2', '3', '4'],
'2': ['5', '6'],
'5': ['9', '10'],
'4': ['7', '8'],
'7': ['11', '12']
}
def bfs(graph, start, end):
# maintain a queue of paths
queue = []
# push the first path into the queue
queue.append([start])
while queue:
# get the first path from the queue
path = queue.pop(0)
# get the last node from the path
node = path[-1]
# path found
if node == end:
return path
# enumerate all adjacent nodes, construct a new path and push it into the queue
for adjacent in graph.get(node, []):
new_path = list(path)
new_path.append(adjacent)
queue.append(new_path)
print bfs(graph, '1', '11')
另一种方法是维护从每个节点到其父节点的映射,并在检查相邻节点时记录其父节点。搜索完成后,只需根据父映射进行回溯。
graph = {
'1': ['2', '3', '4'],
'2': ['5', '6'],
'5': ['9', '10'],
'4': ['7', '8'],
'7': ['11', '12']
}
def backtrace(parent, start, end):
path = [end]
while path[-1] != start:
path.append(parent[path[-1]])
path.reverse()
return path
def bfs(graph, start, end):
parent = {}
queue = []
queue.append(start)
while queue:
node = queue.pop(0)
if node == end:
return backtrace(parent, start, end)
for adjacent in graph.get(node, []):
if node not in queue :
parent[adjacent] = node # <<<<< record its parent
queue.append(adjacent)
print bfs(graph, '1', '11')
以上代码基于没有周期的假设。
答案 1 :(得分:20)
我非常喜欢乔的第一个答案!
这里唯一缺少的是将顶点标记为已访问。
为什么我们需要这样做?
让我们想象从节点11连接另一个节点号13.现在我们的目标是找到节点13
经过一段时间后,队列将如下所示:
[[1, 2, 6], [1, 3, 10], [1, 4, 7], [1, 4, 8], [1, 2, 5, 9], [1, 2, 5, 10]]
请注意,末尾有两个节点号为10的路径
这意味着将检查节点号10的路径两次。在这种情况下,它看起来并不那么糟糕,因为节点号10没有任何子节点..但它可能非常糟糕(即使在这里我们将无缘无故地检查该节点两次..)
节点号13不在那些路径中,因此程序在到达末端节点号为10的第二条路径之前不会返回。我们将重新检查它。
我们所缺少的是一个标记已访问节点的集合,而不是再次检查它们。
这是修改后的qiao代码:
graph = {
1: [2, 3, 4],
2: [5, 6],
3: [10],
4: [7, 8],
5: [9, 10],
7: [11, 12],
11: [13]
}
def bfs(graph_to_search, start, end):
queue = [[start]]
visited = set()
while queue:
# Gets the first path in the queue
path = queue.pop(0)
# Gets the last node in the path
vertex = path[-1]
# Checks if we got to the end
if vertex == end:
return path
# We check if the current node is already in the visited nodes set in order not to recheck it
elif vertex not in visited:
# enumerate all adjacent nodes, construct a new path and push it into the queue
for current_neighbour in graph_to_search.get(vertex, []):
new_path = list(path)
new_path.append(current_neighbour)
queue.append(new_path)
# Mark the vertex as visited
visited.add(vertex)
print bfs(graph, 1, 13)
该计划的输出将是:
[1, 4, 7, 11, 13]
没有不必要的重新检查..
答案 2 :(得分:8)
我以为我会尝试编写这个以获取乐趣:
graph = {
'1': ['2', '3', '4'],
'2': ['5', '6'],
'5': ['9', '10'],
'4': ['7', '8'],
'7': ['11', '12']
}
def bfs(graph, forefront, end):
# assumes no cycles
next_forefront = [(node, path + ',' + node) for i, path in forefront if i in graph for node in graph[i]]
for node,path in next_forefront:
if node==end:
return path
else:
return bfs(graph,next_forefront,end)
print bfs(graph,[('1','1')],'11')
# >>>
# 1, 4, 7, 11
如果您想要循环,可以添加:
for i, j in for_front: # allow cycles, add this code
if i in graph:
del graph[i]
答案 3 :(得分:6)
非常简单的代码。每次发现节点时都会继续附加路径。
graph = {
'A': set(['B', 'C']),
'B': set(['A', 'D', 'E']),
'C': set(['A', 'F']),
'D': set(['B']),
'E': set(['B', 'F']),
'F': set(['C', 'E'])
}
def retunShortestPath(graph, start, end):
queue = [(start,[start])]
visited = set()
while queue:
vertex, path = queue.pop(0)
visited.add(vertex)
for node in graph[vertex]:
if node == end:
return path + [end]
else:
if node not in visited:
visited.add(node)
queue.append((node, path + [node]))
答案 4 :(得分:0)
我喜欢@Qiao的第一个回答和@ Or的补充。为了减少处理,我想补充一下Or的答案。
在@或者回答中,跟踪被访问节点是很好的。我们也可以让程序尽快退出。在for循环中的某个时刻,current_neighbour必须是end,一旦发生,就会找到最短路径并且程序可以返回。
我会修改方法如下,密切关注for循环
graph = {
1: [2, 3, 4],
2: [5, 6],
3: [10],
4: [7, 8],
5: [9, 10],
7: [11, 12],
11: [13]
}
def bfs(graph_to_search, start, end):
queue = [[start]]
visited = set()
while queue:
# Gets the first path in the queue
path = queue.pop(0)
# Gets the last node in the path
vertex = path[-1]
# Checks if we got to the end
if vertex == end:
return path
# We check if the current node is already in the visited nodes set in order not to recheck it
elif vertex not in visited:
# enumerate all adjacent nodes, construct a new path and push it into the queue
for current_neighbour in graph_to_search.get(vertex, []):
new_path = list(path)
new_path.append(current_neighbour)
queue.append(new_path)
#No need to visit other neighbour. Return at once
if current_neighbour == end
return new_path;
# Mark the vertex as visited
visited.add(vertex)
print bfs(graph, 1, 13)
输出和其他一切都是一样的。但是,代码将花费更少的时间来处理。这在较大的图形上特别有用。我希望这有助于将来的某个人。
答案 5 :(得分:0)
如果图表中包含循环,这样的效果会不会更好?
from collections import deque
graph = {
1: [2, 3, 4],
2: [5, 6, 3],
3: [10],
4: [7, 8],
5: [9, 10],
7: [11, 12],
11: [13]
}
def bfs1(graph_to_search, start, end):
queue = deque([start])
visited = {start}
trace = {}
while queue:
# Gets the first path in the queue
vertex = queue.popleft()
# Checks if we got to the end
if vertex == end:
break
for neighbour in graph_to_search.get(vertex, []):
# We check if the current neighbour is already in the visited nodes set in order not to re-add it
if neighbour not in visited:
# Mark the vertex as visited
visited.add(neighbour)
trace[neighbour] = vertex
queue.append(neighbour)
path = [end]
while path[-1] != start:
last_node = path[-1]
next_node = trace[last_node]
path.append(next_node)
return path[::-1]
print(bfs1(graph,1, 13))
这样只会访问新节点,而且避免循环。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?