在执行像K-means这样的聚类分析时,有没有办法让SPSS Modeler输出关联规则?我想要一套规则,将任何观察结果与某个聚类相关联(例如Var1 <0和Var2 = 1然后聚类= A,依此类推),这样我就可以使用它而与SPSS无关。 我在SPSS在线教程中寻找了它,但没有成功。我知道它会输出决策树节点的规则,因此在我看来,它对于K-means等也同样适用。
答案 0 :(得分:0)
您可以使用该逻辑创建一个派生节点(如果Var1 <0且Var2 = 1则簇= 1否则0 endif),然后使用该新变量作为K-Means模型节点中的输入。我在“异常”节点中使用了一些类似的变量,并且对我来说效果很好。只需记住在K-Means节点的前面使用Type节点并将该变量设置为输入即可。
希望对您有所帮助!
答案 1 :(得分:0)
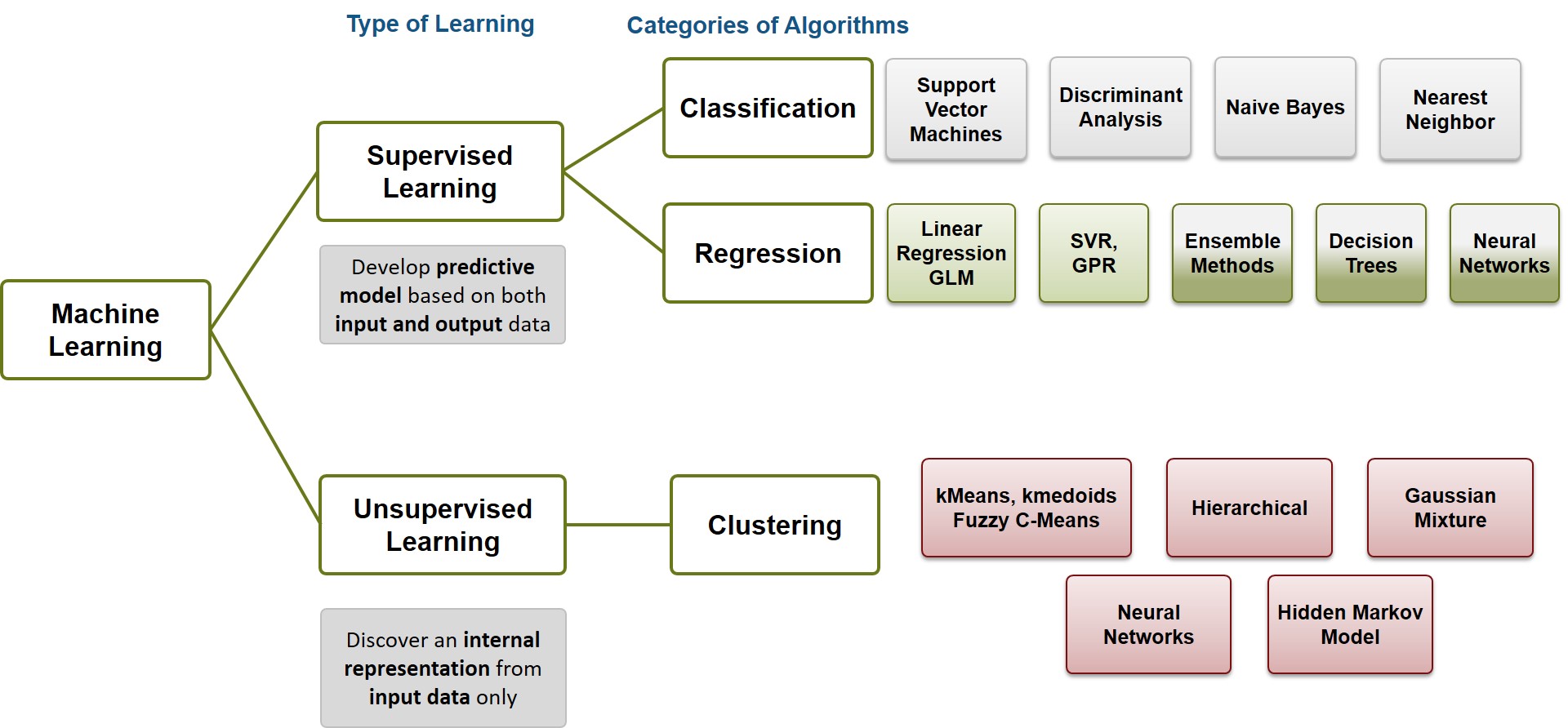
这是两种不同类型的分析,我很想问:您真正想要实现什么? 聚类意味着您将观察分组。 如果观察结果做出了多个活动或选择,并且您想查看下一个最可能的选择,则关联规则(推荐引擎)将很适合您。 但是您描述的内容对我来说更像是一个分类任务,例如不同的方法,因为您描述了规则集,而这正是某些分类模型返回的内容。 http://share.opsy.st/56e7090e92b6c-MathWorks_Figure+1_Machine+Learning+Types.jpg
{kind=link}