我有一个顶点ID列表。我希望在它们中找到所有可能的边缘。
我理解像filter这样的方法在哪里可以提供帮助,但由于我使用gremlin-python,它们的实现必须不同。
我试过了:
a = [0,2,4,6,8,10]
g.V(a).outE().inV().hasId(a).toList()
# This gives me []
g.V(a).bothE().filter(otherV().hasId(a)).toSet()
# Traceback otherV is not defined
g.V(a).bothE().otherV().hasId(a).toList()
# This gives me []
# Some information on edges :
g.E().toList()
# [e[16][0-Likes->8], e[17][8-Likes->0], e[18][4-Likes->8], e[19][2-Likes->6], e[20][6-Likes->2], e[21][12-Likes->10], e[22][10-Likes->12], e[23][10-Likes->14], e[24][14-Likes->8], e[25][6-Likes->4]]
我怎样才能做到这一点?这似乎是一个简单的问题,但我仍然坚持它。
答案 0 :(得分:3)
有很多方法可以做到这一点 - 这个怎么样?
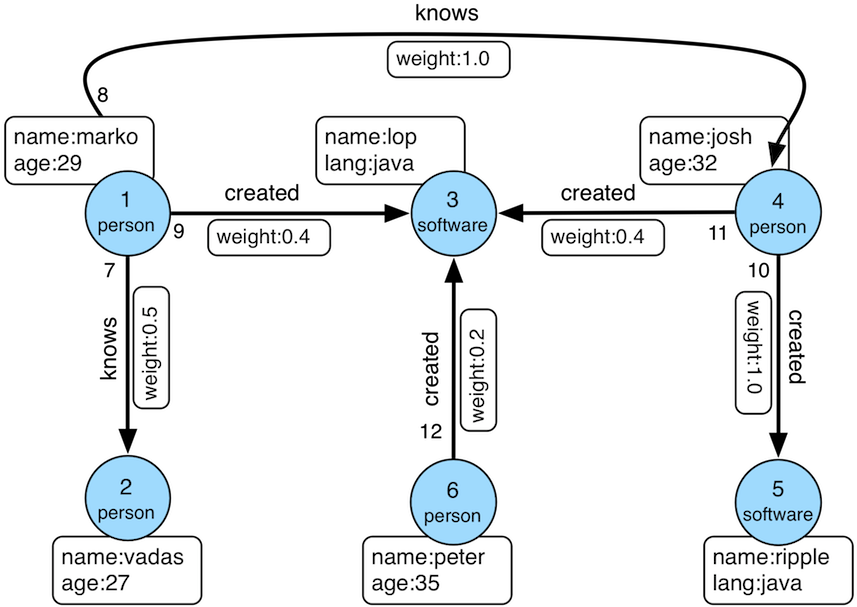
gremlin> a = ['marko','josh','lop']
==>marko
==>josh
==>lop
gremlin> g.V().has('name',within(a)).
......1> aggregate('a').
......2> outE().
......3> filter(inV().where(within('a')))
==>e[9][1-created->3]
==>e[8][1-knows->4]
==>e[11][4-created->3]
这使用modern TinkerPop玩具图作为示例。首先,我们找到那些起始顶点并将它们聚合到名为" a"的列表副作用中。然后,我们遍历每个的传出边缘并过滤它们以便与" a"中的那些顶点匹配。
{kind=link}