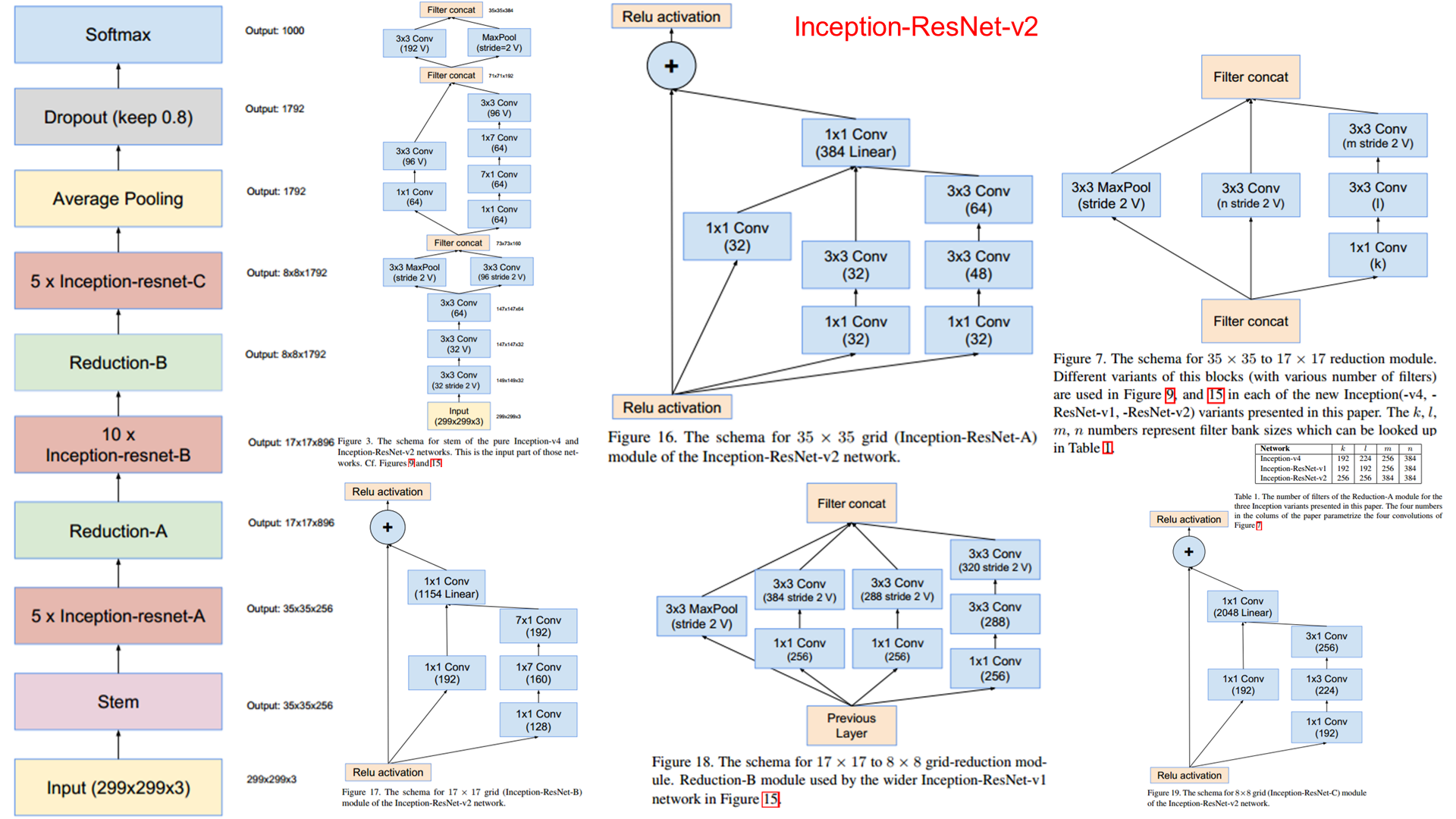
Inception-ResNet-v2模型由多少层组成?我认为他们是96但我不确定。请确认我
https://pic2.zhimg.com/v2-04824ca7ee62de1a91a2989f324b61ec_r.jpg
我的训练和测试数据也分别包含600和62张图像。我使用的是三种型号:ResNet-152,Inception-ResNet和DenseNet-161,它们有以下参数:
RESNET-152: 总参数:58,450,754 可训练的参数:58,299,330 不可训练的参数:151,424
DenseNet-161: 总参数:26,696,354 可训练的参数:26,476,418 不可训练的参数:219,936
启-RESNET: 总参数:54,339,810 可训练的参数:54,279,266 不可训练的参数:60,544
模型的数据是否太稀缺?此外,ResNet模型验证/测试曲线是最平滑的,然后是DenseNet曲线和Inception-ResNet模型是最颠簸的。为什么会这样?
答案 0 :(得分:3)
基于Inception ResNet V2作为https://github.com/titu1994/Inception-v4/blob/master/inception_resnet_v2.py
中的apearsResNet V2有467层,如下所示
def validate_path(path):
return not any(filter_edge(edge.id) for edge in path)
要查看图层的完整描述,您可以下载inception_resnet_v2.py文件并在其末尾添加以下两行:
input_1
conv2d_1
conv2d_2
conv2d_3
max_pooling2d_1
conv2d_4
merge_1
conv2d_7
conv2d_8
conv2d_5
conv2d_9
conv2d_6
conv2d_10
merge_2
max_pooling2d_2
conv2d_11
merge_3
batch_normalization_1
activation_1
conv2d_15
conv2d_13
conv2d_16
conv2d_12
conv2d_14
conv2d_17
merge_4
conv2d_18
lambda_1
merge_5
batch_normalization_2
activation_2
conv2d_22
conv2d_20
conv2d_23
conv2d_19
conv2d_21
conv2d_24
merge_6
conv2d_25
lambda_2
merge_7
batch_normalization_3
activation_3
conv2d_29
conv2d_27
conv2d_30
conv2d_26
conv2d_28
conv2d_31
merge_8
conv2d_32
lambda_3
merge_9
batch_normalization_4
activation_4
conv2d_36
conv2d_34
conv2d_37
conv2d_33
conv2d_35
conv2d_38
merge_10
conv2d_39
lambda_4
merge_11
batch_normalization_5
activation_5
conv2d_43
conv2d_41
conv2d_44
conv2d_40
conv2d_42
conv2d_45
merge_12
conv2d_46
lambda_5
merge_13
batch_normalization_6
activation_6
conv2d_50
conv2d_48
conv2d_51
conv2d_47
conv2d_49
conv2d_52
merge_14
conv2d_53
lambda_6
merge_15
batch_normalization_7
activation_7
conv2d_57
conv2d_55
conv2d_58
conv2d_54
conv2d_56
conv2d_59
merge_16
conv2d_60
lambda_7
merge_17
batch_normalization_8
activation_8
conv2d_64
conv2d_62
conv2d_65
conv2d_61
conv2d_63
conv2d_66
merge_18
conv2d_67
lambda_8
merge_19
batch_normalization_9
activation_9
conv2d_71
conv2d_69
conv2d_72
conv2d_68
conv2d_70
conv2d_73
merge_20
conv2d_74
lambda_9
merge_21
batch_normalization_10
activation_10
conv2d_78
conv2d_76
conv2d_79
conv2d_75
conv2d_77
conv2d_80
merge_22
conv2d_81
lambda_10
merge_23
batch_normalization_11
activation_11
conv2d_83
conv2d_84
max_pooling2d_3
conv2d_82
conv2d_85
merge_24
batch_normalization_12
activation_12
conv2d_87
conv2d_88
conv2d_86
conv2d_89
merge_25
conv2d_90
lambda_11
merge_26
batch_normalization_13
activation_13
conv2d_92
conv2d_93
conv2d_91
conv2d_94
merge_27
conv2d_95
lambda_12
merge_28
batch_normalization_14
activation_14
conv2d_97
conv2d_98
conv2d_96
conv2d_99
merge_29
conv2d_100
lambda_13
merge_30
batch_normalization_15
activation_15
conv2d_102
conv2d_103
conv2d_101
conv2d_104
merge_31
conv2d_105
lambda_14
merge_32
batch_normalization_16
activation_16
conv2d_107
conv2d_108
conv2d_106
conv2d_109
merge_33
conv2d_110
lambda_15
merge_34
batch_normalization_17
activation_17
conv2d_112
conv2d_113
conv2d_111
conv2d_114
merge_35
conv2d_115
lambda_16
merge_36
batch_normalization_18
activation_18
conv2d_117
conv2d_118
conv2d_116
conv2d_119
merge_37
conv2d_120
lambda_17
merge_38
batch_normalization_19
activation_19
conv2d_122
conv2d_123
conv2d_121
conv2d_124
merge_39
conv2d_125
lambda_18
merge_40
batch_normalization_20
activation_20
conv2d_127
conv2d_128
conv2d_126
conv2d_129
merge_41
conv2d_130
lambda_19
merge_42
batch_normalization_21
activation_21
conv2d_132
conv2d_133
conv2d_131
conv2d_134
merge_43
conv2d_135
lambda_20
merge_44
batch_normalization_22
activation_22
conv2d_137
conv2d_138
conv2d_136
conv2d_139
merge_45
conv2d_140
lambda_21
merge_46
batch_normalization_23
activation_23
conv2d_142
conv2d_143
conv2d_141
conv2d_144
merge_47
conv2d_145
lambda_22
merge_48
batch_normalization_24
activation_24
conv2d_147
conv2d_148
conv2d_146
conv2d_149
merge_49
conv2d_150
lambda_23
merge_50
batch_normalization_25
activation_25
conv2d_152
conv2d_153
conv2d_151
conv2d_154
merge_51
conv2d_155
lambda_24
merge_52
batch_normalization_26
activation_26
conv2d_157
conv2d_158
conv2d_156
conv2d_159
merge_53
conv2d_160
lambda_25
merge_54
batch_normalization_27
activation_27
conv2d_162
conv2d_163
conv2d_161
conv2d_164
merge_55
conv2d_165
lambda_26
merge_56
batch_normalization_28
activation_28
conv2d_167
conv2d_168
conv2d_166
conv2d_169
merge_57
conv2d_170
lambda_27
merge_58
batch_normalization_29
activation_29
conv2d_172
conv2d_173
conv2d_171
conv2d_174
merge_59
conv2d_175
lambda_28
merge_60
batch_normalization_30
activation_30
conv2d_177
conv2d_178
conv2d_176
conv2d_179
merge_61
conv2d_180
lambda_29
merge_62
batch_normalization_31
activation_31
conv2d_182
conv2d_183
conv2d_181
conv2d_184
merge_63
conv2d_185
lambda_30
merge_64
batch_normalization_32
activation_32
conv2d_192
conv2d_188
conv2d_190
conv2d_193
max_pooling2d_4
conv2d_189
conv2d_191
conv2d_194
merge_65
batch_normalization_33
activation_33
conv2d_196
conv2d_197
conv2d_195
conv2d_198
merge_66
conv2d_199
lambda_31
merge_67
batch_normalization_34
activation_34
conv2d_201
conv2d_202
conv2d_200
conv2d_203
merge_68
conv2d_204
lambda_32
merge_69
batch_normalization_35
activation_35
conv2d_206
conv2d_207
conv2d_205
conv2d_208
merge_70
conv2d_209
lambda_33
merge_71
batch_normalization_36
activation_36
conv2d_211
conv2d_212
conv2d_210
conv2d_213
merge_72
conv2d_214
lambda_34
merge_73
batch_normalization_37
activation_37
conv2d_216
conv2d_217
conv2d_215
conv2d_218
merge_74
conv2d_219
lambda_35
merge_75
batch_normalization_38
activation_38
conv2d_221
conv2d_222
conv2d_220
conv2d_223
merge_76
conv2d_224
lambda_36
merge_77
batch_normalization_39
activation_39
conv2d_226
conv2d_227
conv2d_225
conv2d_228
merge_78
conv2d_229
lambda_37
merge_79
batch_normalization_40
activation_40
conv2d_231
conv2d_232
conv2d_230
conv2d_233
merge_80
conv2d_234
lambda_38
merge_81
batch_normalization_41
activation_41
conv2d_236
conv2d_237
conv2d_235
conv2d_238
merge_82
conv2d_239
lambda_39
merge_83
batch_normalization_42
activation_42
conv2d_241
conv2d_242
conv2d_240
conv2d_243
merge_84
conv2d_244
lambda_40
merge_85
batch_normalization_43
activation_43
average_pooling2d_1
average_pooling2d_2
conv2d_186
dropout_1
conv2d_187
flatten_2
flatten_1
dense_2
dense_1
关于你的第二个问题(下次我建议你将问题分开而不是将它们一起编写) - 是的,这些数据很可能根本不足以训练任何这些网络。坦率地说,即使对于不起眼的VGG来说也是不够的,除非以聪明的方式使用增强 - 在我看来,即便如此,这也是一个近距离的呼叫。
如果适用,您应该考虑使用已发布的权重,或者至少将它们用于转移学习。
{kind=link}