R:使用hclust()进行聚类分析。如何获得群集代表?
我正在使用 R 进行一些聚类分析。我正在使用hclust()函数,在执行聚类分析之后,我希望得到每个聚类的聚类代表。
我将群集代表定义为最接近群集质心的实例。
所以步骤是:
- 查找群集的质心
- 查找群集代表
我已经问过类似的问题,但使用K-means:https://stats.stackexchange.com/questions/251987/cluster-analysis-with-k-means-how-to-get-the-cluster-representatives
在这种情况下,问题是hclust没有给出质心!
例如,说d是我的数据,到目前为止我所做的是:
hclust.fit1 <- hclust(d, method="single")
groups1 <- cutree(hclust.fit1, k=3) # cut tree into 3 clusters
## getting centroids ##
mycentroid <- colMeans(CV)
clust.centroid = function(i, dat, groups1) {
ind = (groups1 == i)
colMeans(dat[ind,])
}
centroids <- sapply(unique(groups1), clust.centroid, data, groups1)
但是现在,我试图通过这个代码获得集群代表(我在其他问题中得到了它,对于k-means):
index <- c()
for (i in 1:3){
rowsum <- rowSums(abs(CV[which(centroids==i),1:3] - centroids[i,]))
index[i] <- as.numeric(names(which.min(rowsum)))
}
它说:
“e2 [[j]]出错:索引超出限制”
如果你们中的任何人能给我一点帮助,我将不胜感激。感谢。
- (不是)代码的工作示例 -
example_data.txt
A,B,C
10.761719,5.452188,7.575762
10.830457,5.158822,7.661588
10.75391,5.500170,7.740330
10.686719,5.286823,7.748297
10.864527,4.883244,7.628730
10.701415,5.345650,7.576218
10.820583,5.151544,7.707404
10.877528,4.786888,7.858234
10.712337,4.744053,7.796390
至于代码:
# Install R packages
#install.packages("fpc")
#install.packages("cluster")
#install.packages("rgl")
library(fpc)
library(cluster)
library(rgl)
CV <- read.csv("example_data")
str(CV)
data <- scale(CV)
d <- dist(data,method = "euclidean")
hclust.fit1 <- hclust(d, method="single")
groups1 <- cutree(hclust.fit1, k=3) # cut tree into 3 clusters
mycentroid <- colMeans(CV)
clust.centroid = function(i, dat, groups1) {
ind = (groups1 == i)
colMeans(dat[ind,])
}
centroids <- sapply(unique(groups1), clust.centroid, CV, groups1)
index <- c()
for (i in 1:3){
rowsum <- rowSums(abs(CV[which(centroids==i),1:3] - centroids[i,]))
index[i] <- as.numeric(names(which.min(rowsum)))
}
1 个答案:
答案 0 :(得分:1)
分层聚类不使用(或计算)代表。
特别是对于单个链接(但也可能发生在其他链接中),“中心”可以位于不同的群集中。只需考虑示例中的前两个数据集:
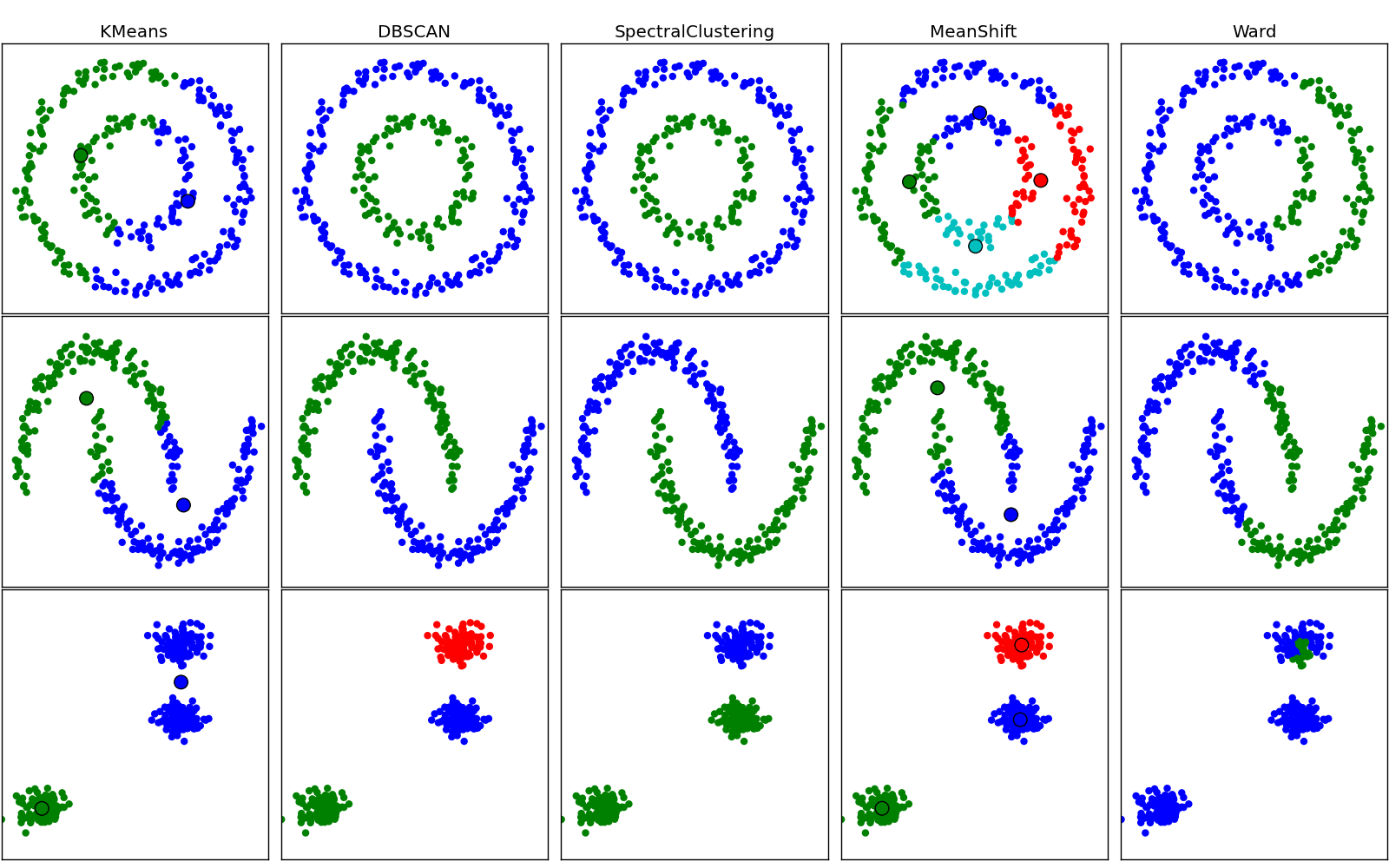
此外,质心(平均值)与欧几里德距离相关。对于其他距离,它可能是一个非常糟糕的代表。
所以要小心使用!
无论哪种方式,分层聚类都不会定义或计算代表。您必须自己 。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?