这就是为什么我问这个问题: 去年,我制作了一些C ++代码来计算特定类型模型的后验概率(由贝叶斯网络描述)。该模型工作得很好,其他一些人开始使用我的软件。现在我想改进我的模型。由于我已经为新模型编写了稍微不同的推理算法,我决定使用python,因为运行时并不重要,python可以让我制作更优雅,更易于管理的代码。
通常在这种情况下我会在python中搜索现有的贝叶斯网络包,但我使用的推理算法是我自己的,我也认为这将是一个很好的机会来了解更多关于python中的优秀设计
我已经为网络图(networkx)找到了一个很棒的python模块,它允许你将字典附加到每个节点和每个边缘。从本质上讲,这将让我给出节点和边缘属性。
对于特定网络及其观察数据,我需要编写一个函数来计算模型中未分配变量的可能性。
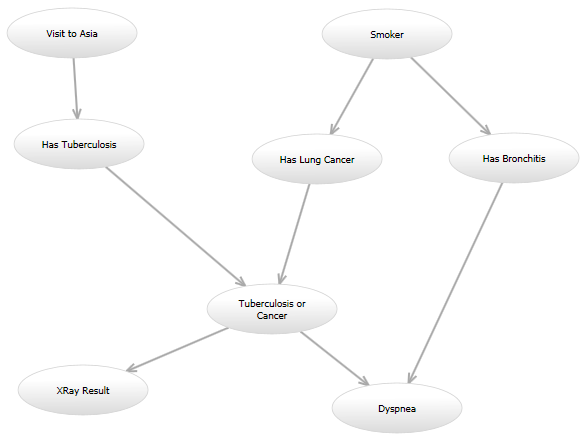
例如,在经典的“亚洲”网络(http://www.bayesserver.com/Resources/Images/AsiaNetwork.png)中,已知“X射线结果”和“呼吸困难”的状态,我需要编写一个函数来计算其他变量的可能性某些值(根据某些模型)。
以下是我的编程问题: 我将尝试一些模型,将来我可能会想要尝试另一种模型。例如,一个模型看起来可能与亚洲网络完全一样。在另一个模型中,可以从“访问亚洲”到“有肺癌”添加有针对性的边缘。另一个模型可能使用原始有向图,但给定“肺结核或癌症”和“支气管炎”节点的“呼吸困难”节点的概率模型可能不同。所有这些模型都将以不同的方式计算可能性。
所有型号都会有很大的重叠;例如,如果所有输入都为“0”,则进入“或”节点的多个边将始终为“0”,否则为“1”。但是一些模型将具有在某个范围内采用整数值的节点,而其他模型将是布尔值。
在过去,我一直在努力解决如何编写这样的事情。我不会撒谎;有相当多的复制和粘贴代码,有时我需要将单个方法中的更改传播到多个文件。这次我真的想花时间以正确的方式做这件事。
一些选项:
非常感谢你的帮助。
更新 面向对象的想法在这里有很多帮助(每个节点具有一组指定的某个节点子类型的前趋节点,并且每个节点具有似然函数,该函数函数在给定前一个节点的状态等的情况下计算其不同结果状态的可能性)。 OOP FTW!
答案 0 :(得分:22)
答案 1 :(得分:3)
Mozart/Oz3 constraints-based inference system解决了类似的问题:您根据对有限域变量,约束传播器和分发器,成本函数的约束来描述您的问题。如果不能进行更多推理但仍有未绑定的变量,它会使用您的成本函数来拆分未绑定变量上的问题空间,这很可能会降低搜索成本:也就是说,如果X在[a,c]之间就是这样一个变量并且c(a
您肯定可以在基于图形的库中实现写时复制方案(提示:numpy使用各种策略来最小化复制;如果您将图形表示基于它,则可能会获得写时复制语义免费)并实现目标。
答案 2 :(得分:2)
我对贝叶斯网络不太熟悉,所以我希望以下内容非常有用:
在过去,我有一个看似相似的高斯过程回归问题,而不是 贝叶斯分类器。
我最终使用了继承,这很好地解决了。所有特定于模型的参数都使用构造函数进行设置。 calculate()函数是虚拟的。 层叠不同的方法(例如,结合了任意数量的其他方法的求和方法)也可以很好地工作。
答案 3 :(得分:2)
我认为你需要问一些影响设计的问题。
如果大部分时间都花在现有模型上并且新模型不太常见,那么继承可能就是我要使用的设计。它使文档易于构建,使用它的代码很容易理解。
如果该库的主要目的是提供一个用于试验不同模型的平台,那么我将使用具有映射到仿函数的属性的图形来计算基于父项的事物。库会更复杂,图形创建会更复杂,但它会更强大,因为它允许你做基于节点改变计算仿函数的混合图形。
无论你最终的设计是什么,我都会从一个简单的一级实现设计开始。让它通过一系列自动化测试,然后在完成之后重构为更完整的设计。另外,不要忘记版本控制; - )
{kind=link}