用于从neative浮点数中删除前导零的正则表达式
人。 我有个问题。我的输入字符串如下:
- 1-000000.02
- 1-000000.00
- 1 + 000025.48
- 1-000025.47
- 1-000000.00
- 1 + 000000.00
- 1 + 000025.46
我想提取normilize(删除加号,删除前导零,但在点之前排除一个零)浮点数如下:
- 0.02
- 0.00
- 25.48
- -25.47
- -0.00
- 0.00
- 25.46
我使用下一个表达式:0 *([0-9] +。?[0-9] +)(http://regexr.com/3dicv),它的工作正常,但我无法抓住减号(" 25.47"相反" -25.47")。 所以,如果有人指出我正确的方式,我将非常感激。 感谢。
2 个答案:
答案 0 :(得分:2)
这适用于regexr.com
\d[+]?([-]?)0*(\d+\.\d+)
替换:
$1$2
对于这些值:
1+000050.93
1-000025.47
1+000000.00
1-000000.00
1+000000.02
1-000000.02
1+100025.47
1-100025.48
它返回:
50.93
-25.47
0.00
-0.00
0.02
-0.02
100025.47
-100025.48
但是,当你在C ++中使用它时,我不明白为什么尾随零是一个问题。
这个C ++似乎提取并解析为双精度。
#include <iostream>
#include <string>
#include <cstdlib>
#include <regex>
using namespace std;
int main() {
string teststring("1+000001.62");
regex re("1([+-][0-9]+[.][0-9]{2})");
smatch match;
string resultstring = regex_replace(teststring, re, "$1" );
double value = std::atof(resultstring.c_str());
cout << value;
return 0;
}
答案 1 :(得分:1)
描述
你只需要向前看一下你的字符串,然后匹配你想要删除的子字符串,同时捕获减号(如果它在那里)。
(?=^[0-9][+-][0-9]+\.[0-9]{2}$)(?:[0-9]+(?:(-)|\+))0+(?!\.)
替换为: $1
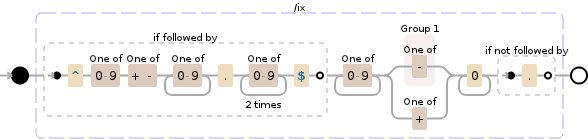
此正则表达式将执行以下操作:
- 验证您的字符串的格式是整数加或减实数,带有两个小数点
- 替换所有其他不可取的内容,如前导整数,小数点前的零,不包括小数点前的零。
实施例
现场演示
https://regex101.com/r/mP4gH1/2
示例文字
1-000000.02
1-000000.00
1+000025.48
1-000025.47
1-000000.00
1+000000.00
1+000025.46
替换后
-0.02
-0.00
25.48
-25.47
-0.00
0.00
25.46
解释
NODE EXPLANATION
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
^ the beginning of a "line"
----------------------------------------------------------------------
[0-9] any character of: '0' to '9'
----------------------------------------------------------------------
[+-] any character of: '+', '-'
----------------------------------------------------------------------
[0-9]+ any character of: '0' to '9' (1 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
\. '.'
----------------------------------------------------------------------
[0-9]{2} any character of: '0' to '9' (2 times)
----------------------------------------------------------------------
$ before an optional \n, and the end of a
"line"
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
[0-9]+ any character of: '0' to '9' (1 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
( group and capture to \1:
----------------------------------------------------------------------
- '-' character
----------------------------------------------------------------------
) end of \1
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
\+ '+' character
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
0+ '0' (1 or more times (matching the most
amount possible))
----------------------------------------------------------------------
(?! look ahead to see if there is not:
----------------------------------------------------------------------
\. '.'
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?