最近question,是否允许编译器用浮点乘法替换浮点除法,这激励我提出这个问题。
在严格的要求下,代码转换后的结果应与实际除法运算在位上相同,
很容易看出,对于二进制IEEE-754算术,这对于2的幂的除数是可能的。只要互惠
除数的可表示,乘以除数的倒数得到的结果与除法相同。例如,乘以0.5可以用2.0替换除法。
然后人们想知道其他除数这样的替换是如何工作的,假设我们允许任何短指令序列取代除法但运行速度明显更快,同时提供比特相同的结果。特别是除了普通乘法之外,还允许融合乘法 - 加法运算。 在评论中,我指出了以下相关文件:
Nicolas Brisebarre,Jean-Michel Muller和Saurabh Kumar Raina。当事先知道除数时,加速正确舍入的浮点除法。 IEEE Transactions on Computers,Vol。 53,第8期,2004年8月,第1069-1072页。
本文作者提倡的技术预先计算除数 y 的倒数作为标准化的头尾对 z h :z l 如下: z h = 1 / y,z l = fma(-y,z h < / sub>,1)/ y 。之后,除法 q = x / y 计算为 q = fma(z h ,x,z l * x )。本文推导出除此 y 必须满足的各种条件才能使该算法起作用。正如人们容易观察到的那样,当头尾迹象不同时,该算法存在无穷大和零的问题。更重要的是,它无法为权重非常小的股息 x 提供正确的结果,因为计算商尾 z l * x ,遭受下流。
本文还提到了另一种基于FMA的划分算法,该算法由Peter Markstein在IBM工作时开创。相关参考文献是:
P上。 W. Markstein。在IBM RISC System / 6000处理器上计算基本功能。 IBM Journal of Research&amp;发展,卷。 1990年1月34日第1号,第111-119页
在Markstein算法中,首先计算倒数 rc ,从中形成初始商 q = x * rc 。然后,用FMA精确计算除法的余数为 r = fma(-y,q,x),并且最终计算出改进的,更准确的商,因为 q = fma (r,rc,q)。
此算法还存在 x 的问题,这些问题是零或无穷大(可以通过适当的条件执行轻松解决),但使用IEEE-754单精度float数据的详尽测试表明它为这些许多小整数中的许多除数 y 提供了所有可能红利 x 的正确商数。这个C代码实现了它:
/* precompute reciprocal */
rc = 1.0f / y;
/* compute quotient q=x/y */
q = x * rc;
if ((x != 0) && (!isinf(x))) {
r = fmaf (-y, q, x);
q = fmaf (r, rc, q);
}
在大多数处理器体系结构中,这应该转换为无分支指令序列,使用预测,条件移动或选择类型指令。举一个具体的例子:对于除3.0f,CUDA 7.5的nvcc编译器为Kepler级GPU生成以下机器代码:
LDG.E R5, [R2]; // load x
FSETP.NEU.AND P0, PT, |R5|, +INF , PT; // pred0 = fabsf(x) != INF
FMUL32I R2, R5, 0.3333333432674408; // q = x * (1.0f/3.0f)
FSETP.NEU.AND P0, PT, R5, RZ, P0; // pred0 = (x != 0.0f) && (fabsf(x) != INF)
FMA R5, R2, -3, R5; // r = fmaf (q, -3.0f, x);
MOV R4, R2 // q
@P0 FFMA R4, R5, c[0x2][0x0], R2; // if (pred0) q = fmaf (r, (1.0f/3.0f), q)
ST.E [R6], R4; // store q
对于我的实验,我编写了下面显示的微小C测试程序,它按递增顺序逐步执行整数除数,并且每一个都按照正确的除法详尽地测试上面的代码序列。它会打印一份通过此详尽测试的除数列表。部分输出如下:
PASS: 1, 2, 3, 4, 5, 7, 8, 9, 11, 13, 15, 16, 17, 19, 21, 23, 25, 27, 29, 31, 32, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 64, 65, 67, 69,
要将替换算法作为优化合并到编译器中,可以安全地应用上述代码转换的除数白名单是不切实际的。到目前为止,程序的输出(以每分钟大约一个结果的速率)表明快速代码可以在x的所有可能编码中正确地处理奇数整数或幂的除数y两个。轶事证据,当然不是证明。
什么样的数学条件可以确定先验代码转换为上述代码序列是否安全?答案可以假设所有浮点运算都是在默认的舍入模式下执行的&#34;舍入到最近或甚至&#34;。
#include <stdlib.h>
#include <stdio.h>
#include <math.h>
int main (void)
{
float r, q, x, y, rc;
volatile union {
float f;
unsigned int i;
} arg, res, ref;
int err;
y = 1.0f;
printf ("PASS: ");
while (1) {
/* precompute reciprocal */
rc = 1.0f / y;
arg.i = 0x80000000;
err = 0;
do {
/* do the division, fast */
x = arg.f;
q = x * rc;
if ((x != 0) && (!isinf(x))) {
r = fmaf (-y, q, x);
q = fmaf (r, rc, q);
}
res.f = q;
/* compute the reference, slowly */
ref.f = x / y;
if (res.i != ref.i) {
err = 1;
break;
}
arg.i--;
} while (arg.i != 0x80000000);
if (!err) printf ("%g, ", y);
y += 1.0f;
}
return EXIT_SUCCESS;
}
答案 0 :(得分:7)
这个问题要求一种方法来识别常量Y的值,这样可以安全地将x / Y转换为使用FMA为x的所有可能值更便宜的计算。另一种方法是使用静态分析来确定值x可以采用的过度近似,以便通常不健全的变换可以应用于变换代码与原始分区不同的值的知识中。没有发生。
使用很好地适应浮点计算问题的浮点值集合的表示,即使从函数开头开始的向前分析也可以产生有用的信息。例如:
float f(float z) {
float x = 1.0f + z;
float r = x / Y;
return r;
}
假设默认的舍入到最近模式(*),在上面的函数x中只能是NaN(如果输入是NaN),+ 0.0f或大于2的数字 -24 的幅度,但不是-0.0f或更接近于零的任何值 -24 。这证明了转换为问题中显示的两种形式之一,用于常数Y的许多值。
(*)假设没有这种假设,除非程序明确使用#pragma STDC FENV_ACCESS ON
预测上面x的信息的转发静态分析可以基于表达式可以作为以下元组的浮点值集合的表示:
true表示可以存在一些NaN,false表示否NaN存在。),为了遵循这种方法,静态分析器必须理解C程序中可能发生的所有浮点运算。为了说明,在分析的代码中用于处理+的值集U和V之间的相加可以实现为:
致谢:上述借鉴了“改善浮点加法和减法约束”,Bruno Marre&amp;克劳德米歇尔
示例:编译下面的函数f:
float f(float z, float t) {
float x = 1.0f + z;
if (x + t == 0.0f) {
float r = x / 6.0f;
return r;
}
return 0.0f;
}
问题中的方法拒绝将函数f中的除法转换为替代形式,因为6不是可以无条件转换除法的值之一。相反,我建议的是从函数的开头应用一个简单的值分析,在这种情况下,确定x是有限浮点数+0.0f或至少2 -24 的大小,并使用此信息来应用Brisebarre等人的转换,对x * C2不会下溢的知识充满信心。
为明确起见,我建议使用下面的算法来决定是否将分割转换为更简单的分类:
Y是否可以使用Brisebarre等人的方法转换其中一个值?x只能采用0的两个表示中的一个?如果在C1和C2具有不同符号并且x只能是零的一个表示的情况下,请记住使用基于FMA的计算的符号来调整(**)以使其在{时{0}产生正确的零。 {1}}为零。x下溢的可能性吗?如果对四个问题的答案为“是”,则可以在正在编译的函数的上下文中将除法转换为乘法和FMA。上述静态分析用于回答问题2,3和4。
(**)“摆弄标志”是指使用-FMA(-C1,x,( - C2)* x)代替FMA(C1,x,C2 * x),这是必要的当x只能是两个带符号的零之一时,结果会正确显示
答案 1 :(得分:6)
让我第三次重启。我们正在努力加速
q = x / y
其中y是一个整数常量,q,x和y都是IEEE 754-2008 binary32个浮点值。下面,fmaf(a,b,c)表示使用binary32值的融合乘法加a * b + c。
朴素算法是通过预先计算的倒数,
C = 1.0f / y
这样在运行时(更快)乘法就足够了:
q = x * C
Brisebarre-Muller-Raina加速度使用两个预先计算的常数,
zh = 1.0f / y
zl = -fmaf(zh, y, -1.0f) / y
这样在运行时,一个乘法和一个融合乘法 - 加法就足够了:
q = fmaf(x, zh, x * zl)
Markstein算法将朴素方法与两个融合乘法相加结合起来,如果天真方法在最不重要的位置产生1个单位内的结果,通过预先计算得出正确的结果
C1 = 1.0f / y
C2 = -y
这样可以使用
来近似divison t1 = x * C1
t2 = fmaf(C1, t1, x)
q = fmaf(C2, t2, t1)
天真的方法适用于两个y的所有权力,但除此之外它非常糟糕。例如,对于除数7,14,15,28和30,它会导致超过一半可能x的结果不正确。
Brisebarre-Muller-Raina方法同样失败了几乎所有两个y的非幂,但更少x产生不正确的结果(不到所有可能的{{1}的一半},取决于x)。
Brisebarre-Muller-Raina文章显示,天真方法的最大误差为±1.5 ULPs。
Markstein方法为两个y的幂以及奇数y的幂提供了正确的结果。 (我没有找到Markstein方法的失败奇数整数除数。)
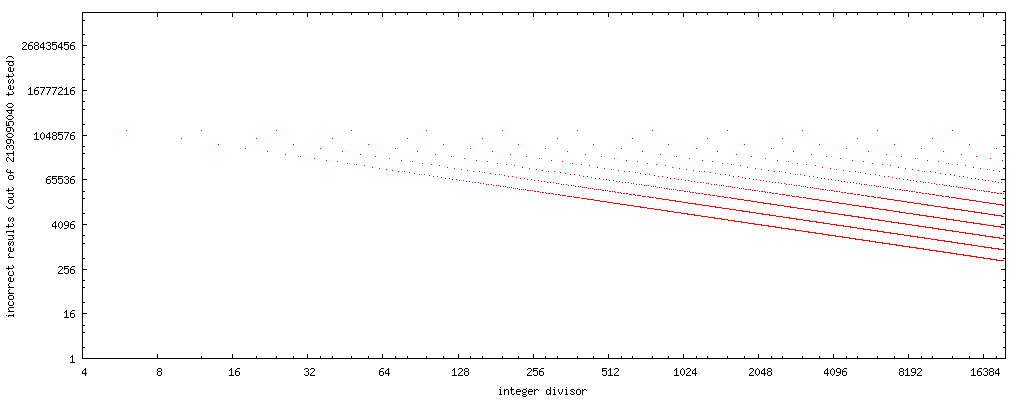
对于Markstein方法,我已经分析了除数1 - 19700(raw data here)。
绘制失败案例的数量(水平轴上的除数,Markstein逼近所述除数的y的值的数量),我们可以看到一个简单的模式:
Markstein failure cases http://www.nominal-animal.net/answers/markstein.png
请注意,这些图的水平轴和垂直轴都是对数的。奇数除数没有点,因为这种方法可以为我测试过的所有奇数除数产生正确的结果。
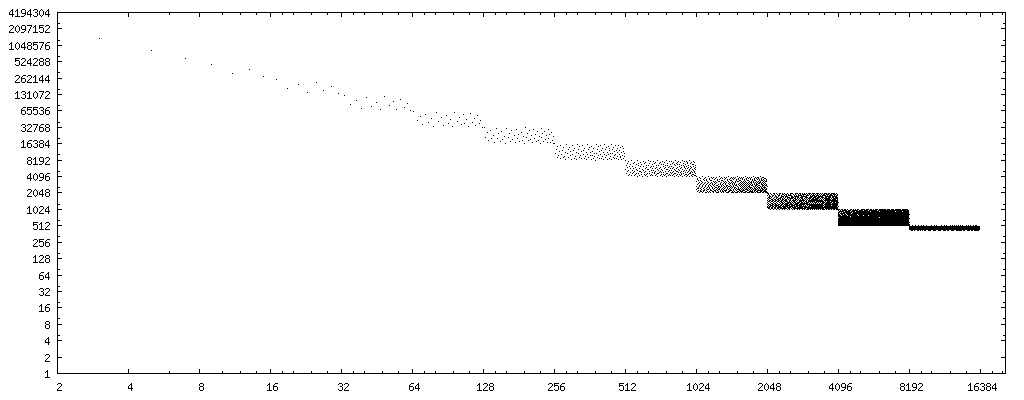
如果我们将x轴改为除数的位反转(反向二进制数字,即0b11101101→0b10110111,data),我们有一个非常清晰的模式: Markstein failure cases, bit reverse divisor http://www.nominal-animal.net/answers/markstein-failures.png
如果我们在点集的中心绘制一条直线,我们得到曲线x。 (请记住,该图只考虑了一半可能的浮点数,因此在考虑所有可能的浮点数时,将其加倍。)
4194304/x和8388608/x完全包含整个错误模式。
因此,如果我们使用2097152/x计算除数rev(y)的位反转,那么y是一个良好的一阶近似的案例数(在所有可能的浮点数中) Markstein方法对偶数,非幂二除数8388608/rev(y)产生不正确的结果。 (或者,y为上限。)
添加2016-02-28:在给定任何整数(binary32)除数的情况下,我找到了使用Markstein方法的错误情况数的近似值。这是伪代码:
16777216/rev(x)在我测试的Markstein失效案例中,这产生了一个正确的误差估计值±1(但我还没有充分测试大于8388608的除数)。最终的划分应该是它没有报告错误的零,但我不能保证它(还)。它没有考虑具有下溢问题的非常大的除数(比如0x1p100,或1e + 30,并且幅度更大) - 无论如何我绝对会将这些除数从加速中排除。
在初步测试中,估计似乎非常准确。我没有绘制比较估计值和除数1到20000的实际误差的图,因为这些点在图中完全重合。 (在此范围内,估计是精确的,或者是太大。)基本上,估计完全重现了这个答案中的第一个图。
Markstein方法的失败模式是有规律的,非常有趣。该方法适用于两个除数的所有幂和所有奇数整数除数。
对于大于16777216的除数,我一直看到与除数的相同误差除以2的最小幂,得到小于16777216的值。例如,0x1.3cdfa4p + 23和0x1.3cdfa4p + 41 ,0x1.d8874p + 23和0x1.d8874p + 32,0x1.cf84f8p + 23和0x1.cf84f8p + 34,0x1.e4a7fp + 23和0x1.e4a7fp + 37。 (在每对中,尾数是相同的,只有2的幂变化。)
假设我的测试平台没有出错,这意味着Markstein方法的幅度大于16777216的除数(但小于1e + 30),如果除数是除以最小的幂两个产生的数量小于16777216的商,且商是奇数。
答案 2 :(得分:1)
浮点除法的结果是:
fenv())正确获得前3个部分(但标志集不正确)是不够的。如果没有进一步的知识(例如,哪些部分的结果实际上是重要的,被除数的可能值等),我会假设用一个常数(和/或一个复杂的FMA混乱)替换除以常数永远不安全。
另外;对于现代CPU,我也不会假设用2个FMA替换分区总是一个改进。例如,如果瓶颈是指令获取/解码,那么这个&#34;优化&#34;会使表现更糟。再举一个例子,如果后续指令不依赖于结果(CPU可以在等待结果的同时并行执行许多其他指令),则FMA版本可能会引入多个依赖性停顿并使性能变差。对于第三个例子,如果正在使用所有寄存器,那么FMA版本(需要额外的&#34;实时&#34;变量)可能会增加&#34;溢出&#34;并使表现更糟。
请注意(在很多但不是所有情况下)除以2的常数倍可以单独添加(具体地说,向指数添加移位计数)。
答案 3 :(得分:1)
我喜欢@Pascal的答案,但在优化中,通常更好的方法是拥有一个简单且易于理解的变换子集,而不是完美的解决方案。
所有当前和常见的历史浮点格式都有一个共同点:二进制尾数。
因此,所有分数都是形式的有理数:
x / 2 n
这与程序中的常量(以及所有可能的基数为10的分数)形成对比,这些常数是形式的有理数:
x /(2 n * 5 m )
因此,一个优化只是测试 m == 0的输入和倒数,因为这些数字完全以FP格式表示,并且使用它们的操作应该产生在格式内准确的数字
因此,例如,在.01到0.99的(十进制2位数)范围内,除以或乘以以下数字将会优化:
.25 .50 .75
其他一切都不会。 (我想,先测试一下,哈哈。)
{kind=link}
{kind=link}