我向那些(几乎)不知道GPU是如何工作的人做了一个演示。我认为说GPU有一千个核心,其中CPU只有四到八个是没有意义的。但我想给观众一个比较的元素。
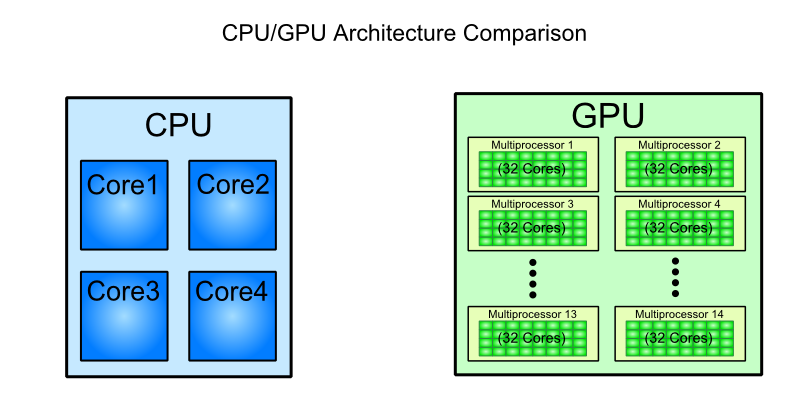
在使用NVidia的Kepler和AMD的GCN架构几个月后,我很想将 GPU“核心”与 CPU的SIMD ALU 进行比较(我不知道)知道他们在英特尔是否有这个名字。 公平吗?毕竟,在查看汇编级别时,这些编程模型有很多共同之处(至少对于GCN,请看一下 p2-6 ISA manual)。
This article表示Haswell处理器每个周期可以执行32次单精度操作,但我认为有流水线或其他事情可以实现该速率。 在NVidia的说法中,这个处理器有多少 Cuda-cores ?我会说每个CPU核心有8个用于32位操作,但这只是基于SIMD宽度。
当然,在比较CPU和GPU硬件时还有许多其他因素需要考虑,但这不是我想要做的。我只需要解释这件事是如何运作的。
PS:非常感谢所有指向 CPU 硬件文档或CPU / GPU演示的指针!
修改 谢谢你的回答,遗憾的是我不得不只选择其中一个。我标记Igor's answer,因为它最符合我最初的问题,并给了我足够的信息来证明为什么不应该把这种比较放得太远,而是CaptainObvious provided very good articles。
答案 0 :(得分:11)
我非常谨慎进行这种比较。毕竟即使在GPU世界中,取决于上下文的术语“核心”具有非常不同的能力:新的AMD GCN与旧的VLIW4完全不同,旧的VLIW4本身与CUDA核心版本截然不同。
除此之外,如果你只与CPU进行一次小比较就会给你的观众带来更多的困惑而不是理解。如果我是你,我仍然会更详细(仍然可以快速)比较。
例如,有人习惯于CPU并且对GPU知之甚少,可能会想知道GPU如何拥有如此多的寄存器,尽管它如此昂贵(在CPU世界中)。在post结尾处给出了对该问题的解释,以及一些GPU和CPU的比较。
另一个article通过解释GPU如何工作以及它们如何演变并显示与CPU的差异,对这两种处理单元进行了很好的比较。它涉及数据流,内存层次结构等主题,但也涉及GPU有用的应用程序类型。在GPU可以开发的所有功能之后,只能针对某些类型的问题(高效)访问
而且就个人而言,如果我不得不做一个关于GPU的演示并且有可能只使用一个对CPU 的引用,那就是:提出GPU可以有效解决的问题与CPU可以更好地处理的问题。
作为奖励即使它与你的演示文稿没有直接关系,这里有一个article让GPGPU正确看待,显示某些人所声称的某些加速被高估(这与我最后一点btw相关联):)
答案 1 :(得分:10)
非常松散地说,Haswell核心拥有大约16个CUDA核心并不是完全没有道理的,但你绝对不想把这个比较太过分。您可能希望在演示文稿中直接制作该语句时要谨慎,但我发现将CUDA核心视为与标量FP单元有些相关是有用的。
如果我解释为什么Haswell每个周期可以执行32次单精度操作,这可能会有所帮助。
在每条AVX / AVX2指令中执行8次单精度运算。编写将在Haswell CPU上运行的代码时,可以使用以256位向量运行的AVX和AVX2指令。这些256位向量可以表示8个单精度FP数,8个整数(32位)或4个双精度FP数。
每个周期可以在每个核心执行2条AVX / AVX2指令,尽管对哪些指令可以配对有一些限制。
融合乘法加法(FMA)指令在技术上执行2次单精度运算。 FMA指令执行“融合”操作,例如A = A * B + C,因此每个标量操作数可以说有两个操作:乘法和加法。
本文更详细地解释了上述几点:http://www.realworldtech.com/haswell-cpu/4/
在总计算中,Haswell核心可以在每个周期执行8 * 2 * 2单精度运算。由于CUDA内核也支持FMA操作,因此在将CUDA内核与Haswell内核进行比较时,不能将该系数计为2。
Kepler CUDA内核有一个单精度浮点单元,因此每个周期可以执行一次浮点运算:http://www.nvidia.com/content/PDF/kepler/NVIDIA-Kepler-GK110-Architecture-Whitepaper.pdf,http://www.realworldtech.com/kepler-brief/
如果我把幻灯片放在一起,我会有一节解释Haswell每周期可以执行多少FP操作:上面的三点,再加上你有多个核心,可能还有多个处理器。而且,我还有另一部分解释每个周期Kepler GPU可以执行多少FP操作:每个SMX 192个,并且GPU上有多个SMX单元。
PS:我可能会说明显而易见的,但为了避免混淆:Haswell架构还包括一个集成的GPU,它与Haswell CPU完全不同。答案 2 :(得分:2)
我完全同意CaptainObvious,特别是提出GPU可以有效解决的问题与CPU可以处理的问题是个好主意。
我喜欢比较CPU和GPU的一种方法是它们可以执行的操作/秒数。但当然不要将一个CPU核心与多核gpu进行比较。
SandyBridge核心可以执行2个AVX操作/循环,即8个双精度数字/循环。因此,一台具有16个Sandy-Bridge内核的计算机,主频为2.6 GHz,峰值功率为333 Gflops。
K20计算模块GK110的峰值为1170 Gflops,是3.5倍。在我看来,这是一个公平的比较,应该强调的是,峰值性能更容易达到CPU(一些应用程序达到峰值的80%-90%)而不是GPU(最佳案例)我知道是less than 50% of peak)。
所以为了总结一下,我不会深入讨论架构细节,而是说明一些剪切数,其中的观点是峰值通常远不及GPU。
答案 3 :(得分:1)
将GPU与矢量化CPU单位进行比较更为公平,但如果您的观众对GPU的工作方式有零概念,那么假设他们对矢量化SSE指令有类似的了解似乎是公平的。
对于像这样的受众,重要的是要指出高级别的差异,比如gpu上的“核心”块如何共享调度程序和注册文件。
我会参考GTC Kepler architecture overview以更好地了解Kepler架构的外观。 如果你想坚持“gpu核心”的想法,This也是两者之间相当可比的比较。
{kind=link}