NVIDIA提供GPUDirect以减少内存传输开销。我想知道AMD / ATI是否有类似的概念?具体做法是:
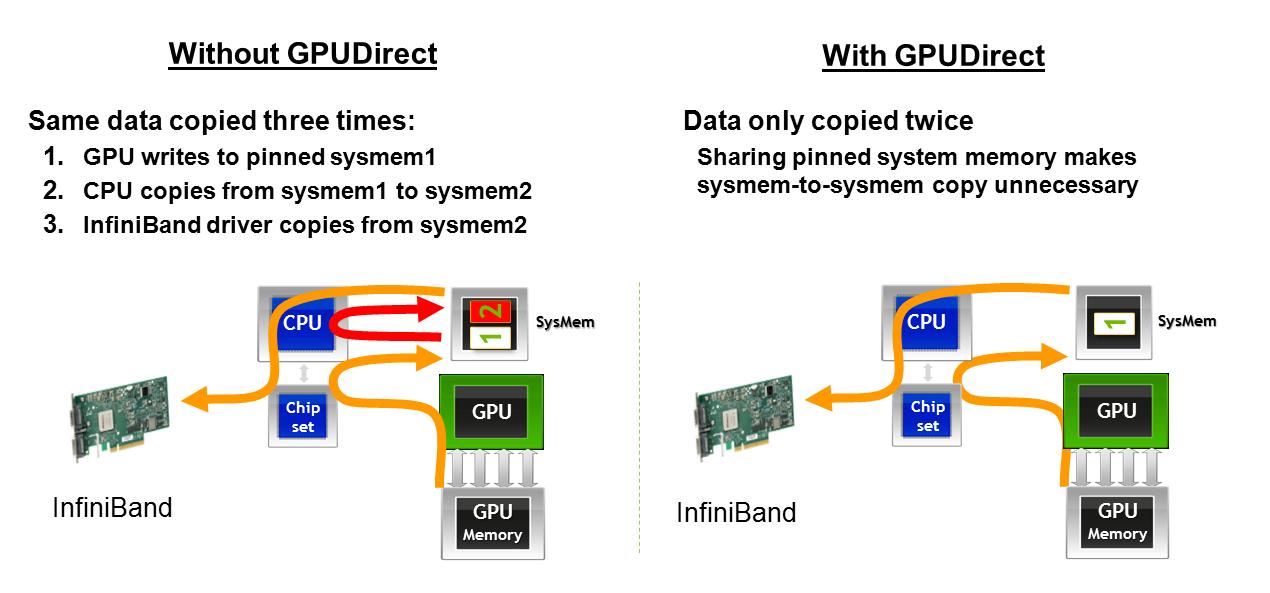
1)在与网卡as described here连接时,AMD GPU是否会避免第二次内存传输。如果图形在某些时候丢失,这里描述了GPUDirect对从一台机器上的GPU获取数据以通过网络接口传输的影响:使用GPUDirect,GPU内存进入主机内存,然后直接进入网络接口卡。如果没有GPUDirect,GPU内存将转移到一个地址空间中的主机内存,然后CPU必须进行复制以将内存转移到另一个主机内存地址空间,然后它就可以转到网卡。
2)当在同一PCIe总线as described here上共享两个GPU时,AMD GPU是否允许P2P内存传输。如果图形在某些时候丢失,这里描述了GPUDirect对同一PCIe总线上GPU之间传输数据的影响:使用GPUDirect,数据可以直接在同一PCIe总线上的GPU之间移动,而不会触及主机内存。如果没有GPUDirect,数据总是必须返回到主机才能到达另一个GPU,无论GPU位于何处。
编辑:BTW,我不完全确定GPUDirect有多少是蒸发器,有多少是实际有用的。我从来没有真正听说过GPU程序员将它用于真实的东西。对此的想法也是受欢迎的。
答案 0 :(得分:2)
我认为你可能正在clCreateBuffer中寻找CL_MEM_ALLOC_HOST_PTR标志。虽然OpenCL规范声明此标志“此标志指定应用程序希望OpenCL实现从主机可访问内存分配内存”,但不确定AMD的实现(或其他实现)可能对它做什么。
这是关于http://www.khronos.org/message_boards/viewtopic.php?f=28&t=2440
主题的信息性主题希望这有帮助。
编辑:我知道nVidia的OpenCL SDK在固定/页面锁定内存中实现了这一点。我很确定这是AMD在OpenGL SDK上运行时所做的事情。
答案 1 :(得分:2)
正如@ananthonline和@harrism所指出的,GPUDirect的许多功能在OpenCL中没有直接的等价物。但是,如果您正在尝试减少内存传输开销,如问题的第一句中所述,零复制内存可能会有所帮助。通常,当应用程序在GPU上创建缓冲区时,缓冲区的内容将从CPU内存集中复制到GPU内存。零拷贝内存,没有前期拷贝;相反,数据在GPU内核访问时被复制。
零拷贝对所有应用程序都没有意义。以下是AMD APP OpenCL编程指南中关于何时使用它的建议:
零拷贝主机驻留内存对象可以在主机时提高性能 设备以稀疏的方式或大的时候访问内存 主机内存缓冲区在多个设备和副本之间共享 太贵了。选择此项时,必须转移成本 大于较慢访问的额外成本。
编程指南的表4.3描述了传递给clCreateBuffer以利用零拷贝的标志(CL_MEM_ALLOC_HOST_PTR或CL_MEM_USE_PERSISTENT_MEM_AMD,具体取决于您是否需要设备可访问的主机内存或主机可访问的设备内存)。请注意,零复制支持取决于操作系统和硬件;它似乎在Linux或旧版Windows下不受支持。
AMD APP OpenCL编程指南:http://developer.amd.com/sdks/AMDAPPSDK/assets/AMD_Accelerated_Parallel_Processing_OpenCL_Programming_Guide.pdf
答案 2 :(得分:2)
尽管这个问题已经很老了,但我想补充一下答案,因为我认为这里的当前信息不完整。
如@Ani的回答中所述,您可以使用CL_MEM_ALLOC_HOST_PTR分配主机内存,并且您很可能会获得固定的主机内存,这取决于实现方式而避免了第二次复制。例如,《 NVidia OpenCL最佳实践指南》指出:
OpenCL应用程序无法直接控制是否存储对象 是否分配在固定内存中,但是他们可以使用 CL_MEM_ALLOC_HOST_PTR标志,此类对象可能会分配给 由驱动程序固定内存以获得最佳性能
我发现以前的答案缺少的一件事是AMD提供了DirectGMA技术。这项技术使您可以直接直接在GPU和PCI总线上的任何其他外围设备(包括其他GPU)之间传输数据,而无需通过系统内存。它更类似于NVidia的RDMA(并非在所有平台上都可用)。
要使用此技术,您必须:
具有兼容的AMD GPU(并非所有人都支持DirectGMA)。您可以使用AMD提供的OpenCL,DirectX或OpenGL扩展。
使外围设备驱动程序(网卡,视频捕获卡等)公开一个物理地址,GPU DMA引擎可以在该物理地址中进行读写操作。或能够对外围DMA引擎进行编程,以将数据传输到GPU裸露的内存中。
我使用这项技术将数据直接从视频捕获设备传输到GPU内存,再从GPU内存传输到专有FPGA。两种情况都非常有效,没有任何多余的复制。
{kind=link}
{kind=link}