使用转移学习对单类数据集进行图像分类
我只有大约1000张计算机图像。我需要训练一个可以识别图像是计算机还是非计算机的模型。我没有非计算机的数据集,因为它可能是任何东西。
我想最好的方法是运用迁移学习。我正在尝试在预训练的VGG19模型上训练数据。但是,我仍然不知道如何仅使用计算机图像而不使用任何非计算机图像来训练模型。
我是ML全面知识的新手,很抱歉,如果问题不重要。
4 个答案:
答案 0 :(得分:1)
对不起,很抱歉。您将需要很多(至少其他1000张图片)非计算机图片。您可以从任何地方获取它们,它们“变化”得越多,对您的模型越有利于提取代表计算机的特征。
想象一下,要成为一个受过训练的婴儿,总是要在某个事物前面说“是”,下次您会发现某个事物时,无论您面前有什么东西,您都会说“是” ...
对于机器学习模型也是如此,您需要正面的例子和负面的例子,否则您的模型通过始终预测为“是”将具有100%的准确性。
如果要从数学/几何角度看待它,可以在特征空间中以点的形式看到每个样本(在您的情况下为图像):想象为每个属性(x,y,z绘制一个轴等等),图像将成为该空间中的一个点。
为简单起见,我们考虑一个二维空间,这意味着每个图像都可以用2个属性来描述(对于图像而言,情况并非如此,通常特征很多,但为简单起见,请想象feature_1 =颜色数量,feature_2 =角度数),在此示例中,我们可以简单地在笛卡尔图中绘制一个点,每个图像对应一个点:
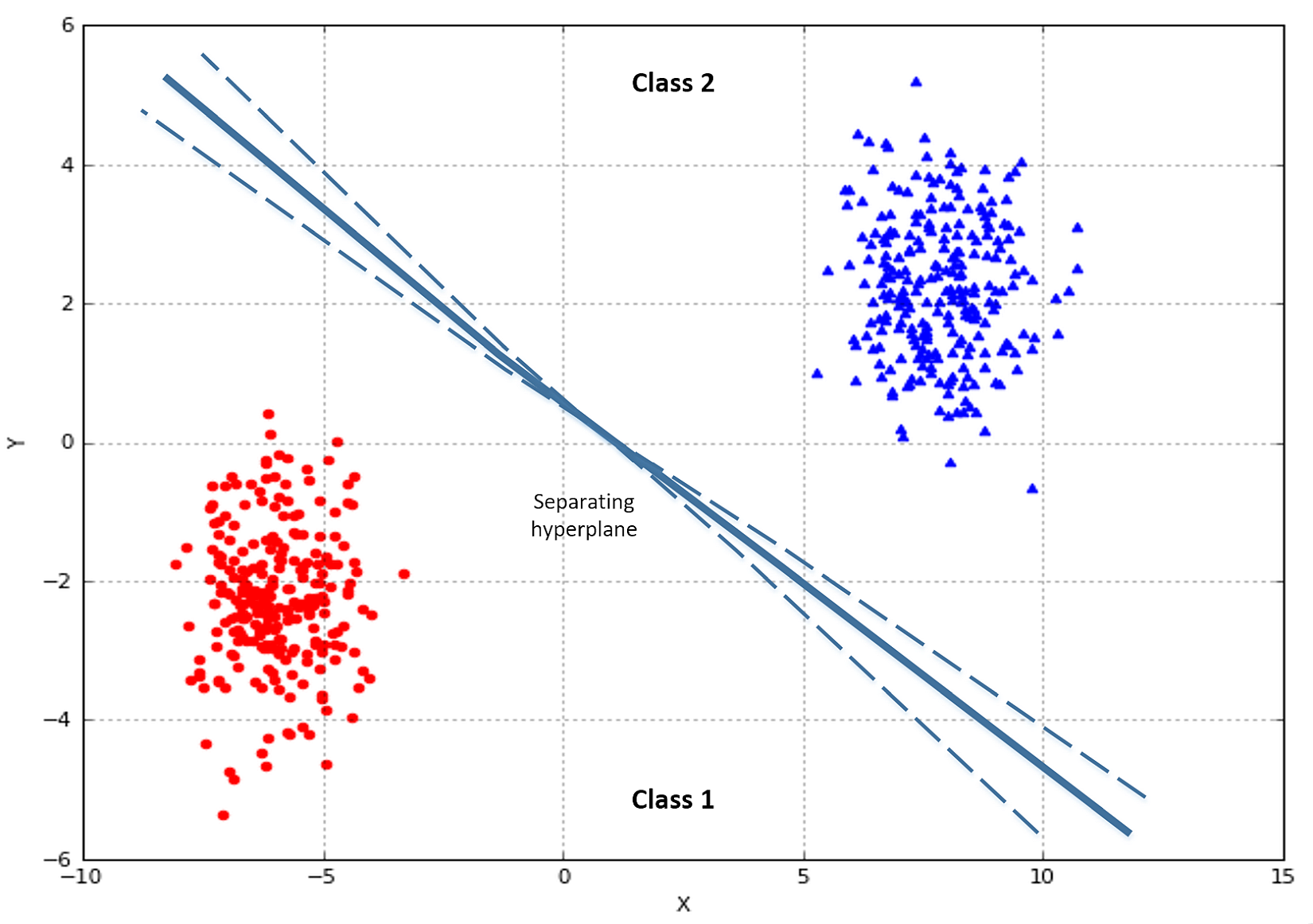
分类器的目的是画一条线,以更好地将红点和蓝点分开,这意味着将正例与负例分开。
如果仅给模型提供正个样本(这是您要做的),则将拥有100%精度的无限模型!因为您可以在任意位置放置一条线,所以唯一的要求就是不要“剪切”数据集。
鉴于我想你是一个初学者,我只告诉你怎么做,而不是告诉你怎么做,因为这将花费数年的时间;)
1)收集数据-正如我告诉你的,甚至是负面的例子,至少还有其他1000个样本
2)将数据拆分为训练/测试-良好的拆分可能是训练集中的样本的2/3和测试集中的1/3。 [记住]请保持最终课程分配的一致性,即,如果您拥有“计算机”-“非计算机”课程的50%-50%,则应同时保持训练集和测试集的百分比
3)训练模型-观看this链接以获取指导示例,它使用MNIST数据集,这是著名的图像分类之一,您应该使用数据
4)在测试集上测试模型并查看性能
答案 1 :(得分:1)
虽然并非不可能只将数据归为一类数据,然后使用方法对其他数据是否属于同一类进行分类,但通常这样做的准确性通常不会很高。 / p>
一种方法是使用称为“自动编码器”的东西。这里的要点是,您使用相同的图像作为输入和目标,并确保(通常是神经网络)被强制以某种方式压缩图像,以便它仅存储对重新创建计算机图像很重要的内容。理想情况下,这应该导致一个模型,该模型擅长重新创建计算机映像,而在其他所有方面都不擅长,这意味着您可以测试输出上的损失有多高,并且如果该损失高于您确定的某个阈值,则可以认为这是别的东西。同样,这样做可能不会获得接近90%的准确性,但这 是解决问题的一种方法。
一种更好的方法是去寻找已经在某些数据集上进行过预训练的模型,这些数据集具有计算机作为数据集的一部分,采用相同的数据集并将所有计算机设置为一类(+您自己的图像,请确保它们遵守数据集格式),并将其他图像选入另一个类别。确保不要使类过于不平衡,否则您的模型将因此受苦。用两层扩展预训练模型,完全连接应该可以做得很好,并使模型的预训练部分不易训练,因此当您实际告诉它时,您不会在那儿弄乱好砝码忽略一切不是计算机的东西。 这可能是您最好的选择,但是在寻找实现它所需的所有这些方面以及了解如何将代码集成到您的方面方面,您需要付出更多的努力。
答案 2 :(得分:1)
- 您可以在imagenet数据集上使用预先训练的模型来使用转移学习。如另一个答案中所述,imagenet内有一堆类,它们靠近计算机和电子设备(例如显示器,CD播放器,笔记本电脑,扬声器等)。因此,您可以微调数据集上的模型,然后对其进行训练以预测计算机(对大约750张图像进行训练,并对其余250张图像进行测试)。
- 您可以手动收集计算机以外的物体的图像,最好是收集许多电子设备(因为它们靠近计算机)和一堆其他家用物品(有home objects dataset by Caltech)。您应该收集大约1000张这样的图像,以达到班级平衡。拥有此数据集后,您就可以训练自己的自定义模型。
答案 3 :(得分:0)
没问题!
第一步:安装您选择的深度学习工具包。这些天来,它们都有不错的教程。
第二步:获取一个预先训练的 imagenet 模型。在该模型中,已经内置了一些计算机类! (“ desktop_computer”,“ laptop”,“ notebook”和其他用于手持计算机的类“ hand-held_computer”)
第三步:使用模型进行预测。为此,您需要将图像的大小正确设置。
更多步骤:进一步微调模型……稍微先进一点,但会带来一些好处。
要考虑的是您的目标是什么?准确性?误报/否定等?从一开始就确定需要完成的目标总是很高兴。
编辑:可能最简单的入门方法(如果您没有库,gpu等)是去google colab(https://colab.research.google.com/notebooks/welcome.ipynb)并在浏览器中创建一个笔记本并运行以下代码。
#some code take and modded from https://www.learnopencv.com/keras-tutorial- using-pre-trained-imagenet-models/
import keras
import numpy as np
from keras.applications import vgg16
from keras.preprocessing.image import load_img
from keras.preprocessing.image import img_to_array
from keras.applications.imagenet_utils import decode_predictions
import matplotlib.pyplot as plt
from PIL import Image
import requests
from io import BytesIO
%matplotlib inline
vgg_model = vgg16.VGG16(weights='imagenet')
def predict_image(image_url, model):
response = requests.get(image_url)
original = Image.open(BytesIO(response.content))
newsize = (224, 224)
original = original.resize(newsize)
# convert the PIL image to a numpy array
# IN PIL - image is in (width, height, channel)
# In Numpy - image is in (height, width, channel)
numpy_image = img_to_array(original)
# Convert the image / images into batch format
# expand_dims will add an extra dimension to the data at a particular axis
# We want the input matrix to the network to be of the form (batchsize, height, width, channels)
# Thus we add the extra dimension to the axis 0.
image_batch = np.expand_dims(numpy_image, axis=0)
plt.imshow(np.uint8(image_batch[0]))
plt.show()
# prepare the image for the VGG model
processed_image = vgg16.preprocess_input(image_batch.copy())
# get the predicted probabilities for each class
predictions = model.predict(processed_image)
# convert the probabilities to class labels
# We will get top 5 predictions which is the default
label = decode_predictions(predictions)
print label[0][0:2] #just display top 2
urls = ['https://4.imimg.com/data4/CO/YS/MY-29352968/samsung-desktop-computer-500x500.jpg', 'https://cdn.britannica.com/77/170477-050-1C747EE3/Laptop-computer.jpg']
for u in urls:
predict_image(u, vgg_model)

这应该是一个很好的起点。哦,而且如果预测的最高标签不在计算机,笔记本电脑等设备中,那么它不是计算机!
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?