将不同数据框标签中的geom_text分配给图形
因此,我正在使用Twitter API来收集与某个主题相关的信息,而我所看到的事情之一就是设备的普及程度。
到目前为止,我有这个: https://gyazo.com/441a9ab80b943f9e0c3a36131273844a
以上是通过此代码生成的:
device_types_condensed <- (ggplot(manu_tweets3, aes(x= statusSource_clean , fill = isRetweet)) + geom_bar()
+ theme(panel.background=element_rect(fill='white'),
axis.ticks.x=element_blank(),
axis.text.x=element_blank())
+ theme(axis.ticks.x=element_blank(), axis.text.x = element_text(angle = 25),
axis.text=element_text(size=8))
+ labs(x="", title = "Device Popularity for Tweet or Retweet Usage", y ="No. of Tweets on Device")
)
device_types_condensed
我想做的是在每个栏上方添加文本,以反映设备负责的tweet活动的百分比。
这意味着我没有更改y轴。 y轴仍反映了tweet的计数,条形图顶部的数字将反映百分比。到目前为止,我已经有一个使用该值制作的表: https://i.gyazo.com/5f14d2c1352e8c9c2c5997678ceea3b4.png
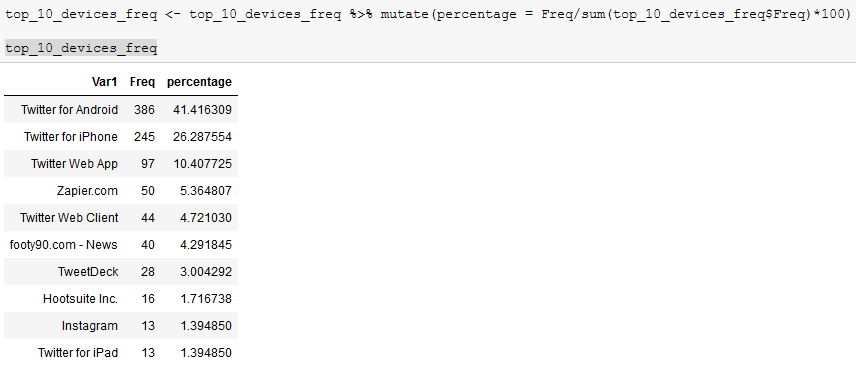{kind=link}
我终生无法发现的是如何在上表中选择%标签,然后根据设备类型将其应用于ggplot图。
对不起,没有代表发布图片,但是我链接了网址!
2 个答案:
答案 0 :(得分:0)
您可以使用dput()打印数据并将其发布到代码中以制作可重复的示例,但是您应该能够使用Sandy Muspratt here的答案来做您想做的事情。
答案 1 :(得分:0)
您非常接近。我无权访问您的确切数据,因此简化了您的问题。您说您有一些设备,每个设备都有与这些设备相关的推文计数,并且每个设备都具有单独的比例。您还说过,它们位于两个不同的data.frame中。
处理此问题的最ggplot方式是将它们连接在一起成为单个data.frame,因为两个data.frame共享一个公用密钥:设备。这简化了ggplot2代码的触摸。首先,我将不结合就解决一个问题,然后向您展示如何将两个data.frame结合在一起。
我生成的数据看起来类似于您的数据,如下所示:
mydf <- data.frame(device = c("A", "B", "C"),
num_tweets = c(100, 200, 50))
prop_df <- data.frame(device = c("A", "B", "C"),
proportion = c(.29, .57, .14))
无需先将它们连接在一起,我想您可以通过以下代码获得想要的东西:
ggplot(mydf) +
geom_col(aes(device,
num_tweets)) +
geom_text(data = prop_df,
aes(device,
max(mydf$num_tweets * 1.10),
label = paste0(proportion * 100, "%"))) +
scale_y_continuous(expand = expand_scale(mult = c(0, .1)))
注意几件事:
- 我进行了一次
geom_text调用以显示百分比,因为我希望ggplot2为我处理x位置(以匹配我们在其上方调用geom_col时已经显示的内容)条和百分比匹配。 -
geom_text调用的第一个参数为data = prop_df,它告诉geom_text不要使用绘图的默认data.frame,mydf,而要使用{ {1}}代替 just 该层。 - 在我的
prop_df通话中,我告诉ggplot将aes映射到x轴,然后将y值硬编码为最大设备数量的110%,这样它们将在高度相同,就在杠上方。 -
device默认情况下会尝试缩小绘图区域以匹配您绘制的数据,而我想要更多的呼吸空间,因此我使用ggplot2沿y方向将绘图扩展了110%。
这与您想要的东西相似吗?

然后我继续进行操作,通过将两个expand_scale(mult = c(0, .1)与之前的ggplot一起加入来简化了data.frame的调用:
dplyr::left_join短一点,不需要您覆盖library(dplyr)
mydf <- left_join(mydf, prop_df)
ggplot(mydf) +
geom_col(aes(device,
num_tweets)) +
geom_text(aes(device,
max(mydf$num_tweets * 1.10),
label = paste0(proportion * 100, "%"))) +
scale_y_continuous(expand = expand_scale(mult = c(0, .1)))
中的data参数。
你怎么看?
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?