LSTM自动编码器中的输入数据减少了多少
问题
-
在LSTM自动编码器中,我的输入数据(59个特征)在通常位于编码器和解码器中间的潜矢量中减少了多少?
-
作者为什么在编码阶段的中间将特征号从5增加到16。下面的LSTM自动编码器结构图将更详细地描述这个问题。
我的问题基于文章LSTM Autoencoder for Extreme Rare Event Classification in Keras。您可以查看this github repository中的代码。请参考这些资源以更好地了解我的问题。
问题的详细信息
- 我的自动编码器模型如下:
lstm_autoencoder = Sequential()
# Encoder
lstm_autoencoder.add(LSTM(timesteps, activation='relu', input_shape=(timesteps, n_features), return_sequences=True))
lstm_autoencoder.add(LSTM(16, activation='relu', return_sequences=True))
lstm_autoencoder.add(LSTM(1, activation='relu'))
lstm_autoencoder.add(RepeatVector(timesteps))
# Decoder
lstm_autoencoder.add(LSTM(timesteps, activation='relu', return_sequences=True))
lstm_autoencoder.add(LSTM(16, activation='relu', return_sequences=True))
lstm_autoencoder.add(TimeDistributed(Dense(n_features)))
lstm_autoencoder.summary()
-
输入数据的形状为
X_train_y0_scaled.shape = (11692,5,59)。这意味着我们有11692批次。每个批次由5行和59列组成,并且由于该数据是时间序列数据,因此意味着每5天收集59个特征。 -
自动编码器模型的摘要如下:
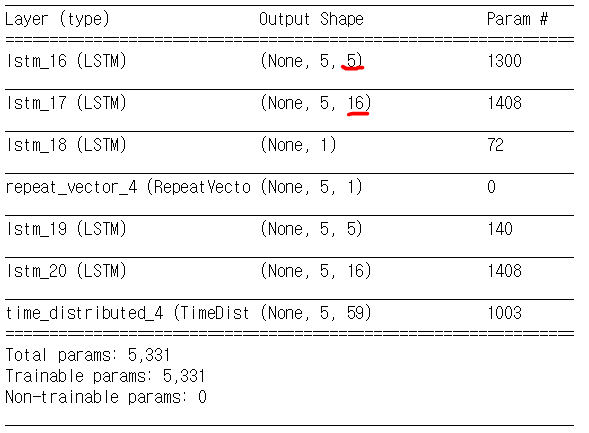
-另一个问题:我不明白为什么这些代码的作者将功能编号从5(在“ lstm_16”层中)增加到16(在“ lstm_17”层中)。
-特征的原始数量是59,因此在第一层中,特征数量从59减少到了5。但是在减小尺寸之后,为什么有人要在编码阶段增加尺寸?!
-
很容易看出,如果它是完全连接的自动编码器,则在潜矢量中输入数据的形状会减小多少。例如,在下面的图片中,10节点长的输入数据被简化为3节点长的潜矢量。
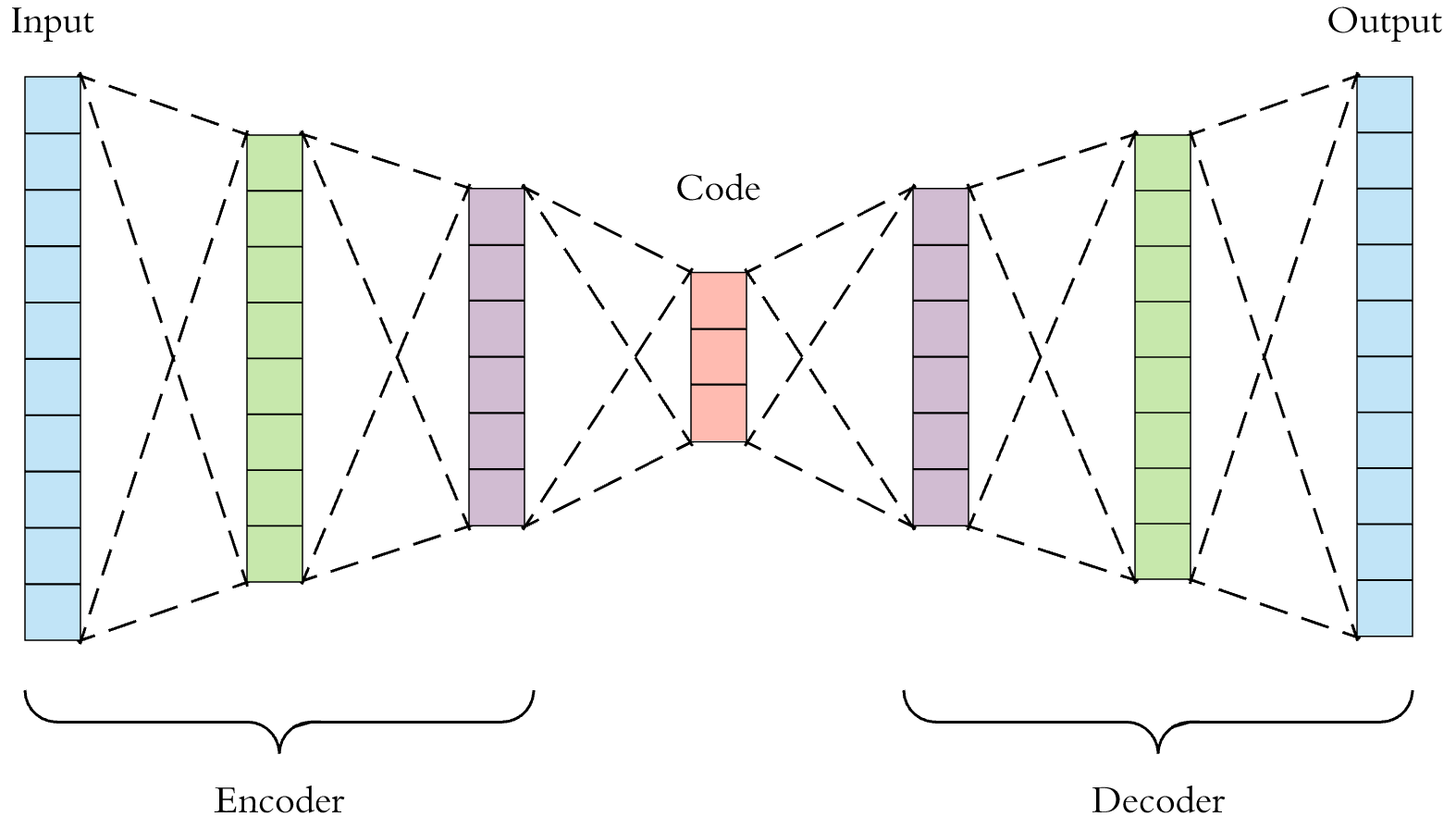
-
但是,在LSTM自动编码器中,我不清楚将59个特征长向量减少到多长时间。
The layer lstm_18仅1个节点,而repeat vector仅(5,1)。这是否意味着将59个特征的长向量简化为1个节点的长向量?
0 个答案:
没有答案
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?