如何在keras fit_generator()中定义max_queue_size,worker和use_multiprocessing?
我正在使用GPU版本的keras在经过预训练的网络上应用转移学习。我不了解如何定义参数 max_queue_size , workers 和 use_multiprocessing 。如果我更改了这些参数(主要是为了加快学习速度),我不确定是否每个时期仍能看到所有数据。
max_queue_size :
-
内部训练队列的最大大小,该队列用于“预缓存”生成器中的样本
-
问题:这是否表示在CPU上准备了多少批?它与
workers有什么关系?如何最佳定义它?
workers :
-
并行生成批处理的线程数。批处理在CPU上并行计算,然后即时传递到GPU进行神经网络计算
-
问题:我如何找出我的CPU可以/应该并行生成多少个批次?
use_multiprocessing :
-
是否使用基于进程的线程
-
问题:如果更改
workers,是否必须将此参数设置为true?它与CPU使用率有关吗?
相关问题可以在这里找到:
- Detailed explanation of model.fit_generator() parameters: queue size, workers and use_multiprocessing
-
What is the parameter “max_q_size” used for in “model.fit_generator”?
-
A detailed example of how to use data generators with Keras。
我正在使用fit_generator(),如下所示:
history = model.fit_generator(generator=trainGenerator,
steps_per_epoch=trainGenerator.samples//nBatches, # total number of steps (batches of samples)
epochs=nEpochs, # number of epochs to train the model
verbose=2, # verbosity mode. 0 = silent, 1 = progress bar, 2 = one line per epoch
callbacks=callback, # keras.callbacks.Callback instances to apply during training
validation_data=valGenerator, # generator or tuple on which to evaluate the loss and any model metrics at the end of each epoch
validation_steps=
valGenerator.samples//nBatches, # number of steps (batches of samples) to yield from validation_data generator before stopping at the end of every epoch
class_weight=classWeights, # optional dictionary mapping class indices (integers) to a weight (float) value, used for weighting the loss function
max_queue_size=10, # maximum size for the generator queue
workers=1, # maximum number of processes to spin up when using process-based threading
use_multiprocessing=False, # whether to use process-based threading
shuffle=True, # whether to shuffle the order of the batches at the beginning of each epoch
initial_epoch=0)
我的机器的规格是:
CPU : 2xXeon E5-2260 2.6 GHz
Cores: 10
Graphic card: Titan X, Maxwell, GM200
RAM: 128 GB
HDD: 4TB
SSD: 512 GB
1 个答案:
答案 0 :(得分:2)
Q_0:
问题:这是否指的是在CPU上准备多少批次?它与工人有什么关系?如何最佳定义它?
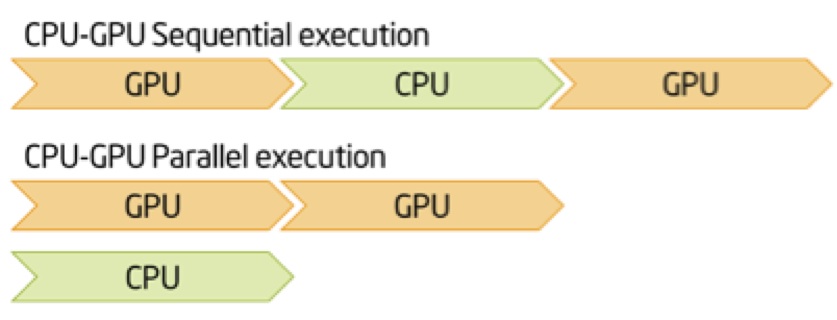
从发布的link中,您可以了解到CPU一直在创建批处理,直到队列达到最大队列大小或到达停止为止。您需要准备好批处理以供GPU“使用”,以便GPU不必等待CPU。 队列大小的理想值是使其足够大,以使您的GPU始终在接近最大值的情况下运行,而不必等待CPU准备新批处理。
Q_1:
问题:如何找出我的CPU可以/应该并行生成多少个批次?
如果您发现GPU处于空闲状态并且正在等待批处理,请尝试增加工作人员的数量,也许还增加队列的大小。
Q_2:
如果我更换工人,是否必须将此参数设置为true?它与CPU使用率有关吗?
Here是对将其设置为True或False时发生的情况的实用分析。建议将Here设置为False以防止冻结(在我的设置中True可以正常工作而不会冻结)。也许其他人可以增进我们对该主题的理解。
总结:
请尝试不进行顺序设置,请尝试使CPU为GPU提供足够的数据。
还:您可以(应该吗?)下次再提出几个问题,以便更轻松地回答它们。
- 如何:fit_generator in keras
- 使用fit_generator
- Keras中的ImageDataGenerator和fit_generator:了解时代
- 在Windows的fit_generator中激活use_multiprocessing时出错
- 间谍与Windows 10中的Keras fit_generator()中关于多处理和工作者的混淆
- fit和fit_generator之间的区别
- 如何在keras fit_generator()中定义max_queue_size,worker和use_multiprocessing?
- Keras序列,fit_generator和steps_per_epoch
- 是否有use_multiprocessing = True的fit_generator的工作示例?
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?