我无法识别使用CNN的多字符输入图像,该图像使用自己的字符图像数据集进行了训练
我使用自己的角色图像数据集训练了CNN,这是我自己创建的。然后我遵循https://in.mathworks.com/help/deeplearning/examples/create-simple-deep-learning-network-for-classification.html。到目前为止,我给出了90%以上的准确性。 在上面提到的过程中,它只是作为训练和测试从数据集中分为两部分。 但是,我想训练所有的数据集而不拆分,并且想识别包含数字单词的输入图像中的字符。 我试着做,但结果令人惊讶。 CNN培训代码:
close all;
clear all;
clc;
%%%%-------Load and Explore Image Data----%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
digitDatasetPath = fullfile('abcd');
imds = imageDatastore(digitDatasetPath, ...
'IncludeSubfolders',true,'LabelSource','foldernames');
labelCount = countEachLabel(imds);
numTrainFiles = 180;
imdsTrain = splitEachLabel(imds,numTrainFiles,'randomize'); %%%%%% I Used
all images for training
layers = [
imageInputLayer([28 28 1])
convolution2dLayer(3,8,'Padding','same')
batchNormalizationLayer
reluLayer
maxPooling2dLayer(2,'Stride',2)
convolution2dLayer(3,16,'Padding','same')
batchNormalizationLayer
reluLayer
maxPooling2dLayer(2,'Stride',2)
convolution2dLayer(3,32,'Padding','same')
batchNormalizationLayer
reluLayer
fullyConnectedLayer(10)
softmaxLayer
classificationLayer];
options = trainingOptions('sgdm', ...
'InitialLearnRate',0.01, ...
'MaxEpochs',4, ...
'Shuffle','every-epoch', ...
'ValidationFrequency',30, ...
'Verbose',false, ...
'Plots','training-progress');
mynet = trainNetwork(imdsTrain,layers,options);
save mynet;
预处理和识别程序:
close all;
clear all;
clc;
%outputfolder='L:\cnn';
load mynet
aa=imread('0.tif');
% figure;
% imshow(a);
% title('Input Image');
bb=rgb2gray(aa);
% figure;
% imshow(b);
% title('gray image');
cc=imbinarize(bb);
%figure;
%imshow(cc);
% title('binary Image');
dd=~cc;
% figure;
%imshow(dd);
[x,y]=size(cc);
ee=sum(cc,2);
mat2=y-ee;
mat3=mat2~=0;
mat4=diff(mat3);
index1=find(mat4);
[q,w]=size(index1);%size of index2 matrix is q*w
kap=1;
lam=1;
while kap<((q/2)+1)%number of loops=number of lines
k=1;
mat5=([]);
for j=(index1(lam)+1):1:index1(lam+1)
mat5(k,:)=cc(j,:); %store the line segmented matrix
k=k+1;
end
lam=lam+2;
kap=kap+1;
%figure, imshow(mat5);
%imsave();
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%% WORD SEGMENT%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
ccc=imbinarize(mat5);
[xx,yy]=size(ccc);
eee=sum(ccc,1);
mat22=xx-eee;
mat33=mat22~=0;
mat44=diff(mat33);
index11=find(mat44);
[qq,ww]=size(index11);%size of index2 matrix is q*w
kap1=1;
lam1=1;
while kap1<((ww/2)+1)%number of loops=number of lines
kk=1;
mat55=([]);
for jj=(index11(lam1)+1):1:index11(lam1+1)
mat55(:,kk)=ccc(:,jj); %store the line segmented matrix
kk=kk+1;
end
lam1=lam1+2;
kap1=kap1+1;
%figure, imshow(mat55);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%% REMOVE UNWANTED SPACE %%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
invmat55=~mat55;
chasum=sum(invmat55,2);
measurements = regionprops(chasum == 0, 'Area',
'PixelIdxList');
fiveLongRegions = find([measurements.Area] >= 4);
theIndexes =
vertcat(measurements(fiveLongRegions).PixelIdxList);
cccc=mat55;
cccc(theIndexes,:)=0;
bbbb=cccc;
%figure, imshow(bbbb);
measurements = regionprops(bbbb, 'Area', 'BoundingBox');
allAreas = [measurements.Area];
% Crop out each word
a=001;
for blob = 1 : length(measurements)
% Get the bounding box.
thisBoundingBox = measurements(blob).BoundingBox;
% Crop it out of the original gray scale image.
thisWord = imcrop(mat55, thisBoundingBox);
RI2 = imresize(thisWord,[28 28]);
YPred = classify(mynet,RI2);
figure;
imshow(RI2);
label = YPred;
title(string(label));
end
end
end
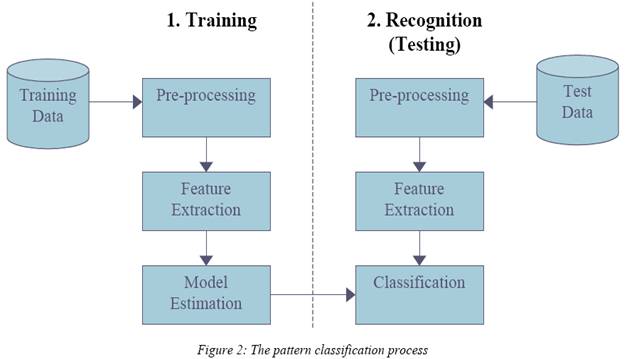
我希望我的程序分为以下两部分,即培训和测试,如下面的波纹管模型所示:测试数据输入图像包含行数和单词数。
0 个答案:
没有答案
相关问题
- 如何使用java识别图像中的字符?
- 哪个变量是等于函数camparing字符集?
- cnn使用张量流为自己的图像集 - 应该是tfrecord格式
- 如何用cnn训练模型预测输入图像
- 训练有素的重量是否取决于训练数据的输入顺序?
- 在训练有素的CNN模型中使用类似MNIST的图像数据进行错误的预测
- 如何使用经过训练的CNN张量流模型来测试另一个.py文件中的输入图像
- 我无法识别使用CNN的多字符输入图像,该图像使用自己的字符图像数据集进行了训练
- 如何将自己训练有素的数据与Tesseract(pytesseract)结合使用?
- 为什么使用我训练有素的模型(CNN Pytorch),以相同的数据收入获得不同的结果?
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?