我正在尝试使用scikit-learn Python库在不平衡的数据集上安装随机森林分类器。
我的目标是获得与召回率和精度相同的值,为此,我正在使用RandomForestClassifier函数的class_weight参数。
当使用class_weight = {0:1,1:1}拟合随机森林时(换句话说,假设数据集不平衡),我得到:
准确度:0.79 精度:0.63 召回率:0.32 AUC:0.74
当我将class_weight更改为{0:1,1:10}时,我得到:
准确度:0.79 精度:0.65 召回率:0.29 AUC:0.74
因此,召回率和精度值几乎没有变化(即使我从10增加到100,变化也很小)。
由于X_train和X_test都以相同的比例失衡(数据集有超过一百万行),所以在使用class_weight = {0:1,1:10时,我是否应该获得截然不同的召回率和精度值}?
答案 0 :(得分:2)
如果您想增加模型的召回率,可以使用一种更快的方法。
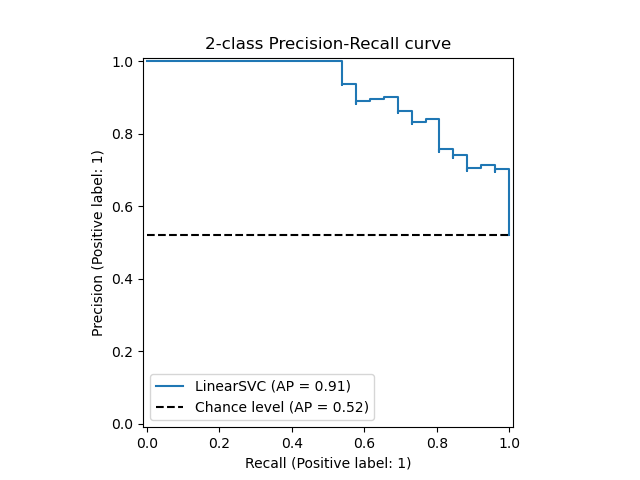
您可以使用sklearn计算precision recall curve。
此曲线将为您提供模型的精度和召回率之间的权衡。
这意味着,如果您想增加模型的召回率,则可以要求随机森林检索您每个类别的概率,将类别1加0.1,然后将类别0的概率减去0.1。这将有效地增加召回率
如果绘制精度召回曲线,您将能够找到相同精度和召回率的最佳阈值
这里有sklearn的示例
from sklearn import svm, datasets
from sklearn.model_selection import train_test_split
import numpy as np
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Add noisy features
random_state = np.random.RandomState(0)
n_samples, n_features = X.shape
X = np.c_[X, random_state.randn(n_samples, 200 * n_features)]
# Limit to the two first classes, and split into training and test
X_train, X_test, y_train, y_test = train_test_split(X[y < 2], y[y < 2],
test_size=.5,
random_state=random_state)
# Create a simple classifier
classifier = svm.LinearSVC(random_state=random_state)
classifier.fit(X_train, y_train)
y_score = classifier.decision_function(X_test)
from sklearn.metrics import precision_recall_curve
import matplotlib.pyplot as plt
from sklearn.utils.fixes import signature
precision, recall, _ = precision_recall_curve(y_test, y_score)
# In matplotlib < 1.5, plt.fill_between does not have a 'step' argument
step_kwargs = ({'step': 'post'}
if 'step' in signature(plt.fill_between).parameters
else {})
plt.step(recall, precision, color='b', alpha=0.2,
where='post')
plt.fill_between(recall, precision, alpha=0.2, color='b', **step_kwargs)
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.ylim([0.0, 1.05])
plt.xlim([0.0, 1.0])
哪个应该给你类似this
答案 1 :(得分:0)
作为补充的答案,您还可以尝试针对一个或多个指标优化模型。您可以使用RandomizedSearchCV为您寻找超参数的良好组合。例如,如果您训练随机森林分类器”:
#model
MOD = RandomForestClassifier()
#Implemente RandomSearchCV
m_params = {
"RF": {
"n_estimators" : np.linspace(2, 500, 500, dtype = "int"),
"max_depth": [5, 20, 30, None],
"min_samples_split": np.linspace(2, 50, 50, dtype = "int"),
"max_features": ["sqrt", "log2",10, 20, None],
"oob_score": [True],
"bootstrap": [True]
},
}
scoreFunction = {"recall": "recall", "precision": "precision"}
random_search = RandomizedSearchCV(MOD,
param_distributions = m_params[model],
n_iter = 20,
scoring = scoreFunction,
refit = "recall",
return_train_score = True,
random_state = 42,
cv = 5,
verbose = 1 + int(log))
#trains and optimizes the model
random_search.fit(x_train, y_train)
#recover the best model
MOD = random_search.best_estimator_
请注意,参数评分和调整将告诉RandomizedSerachCV您最想最大化哪些指标。这种方法还可以节省手动调整的时间(并可能使模型在测试数据上过拟合)。
祝你好运!
{kind=link}