我要加载3个小时的MP3文件,每隔约15分钟就会播放一次独特的1秒钟声音效果,这预示着新篇章的开始。
是否可以识别每次播放此声音效果的时间,以便记下时间偏移?
每次的声音效果都相似,但是由于它是以有损文件格式编码的,因此会有少量变化。
时间偏移将存储在ID3 Chapter Frame MetaData中。
Example Source,声音效果播放两次。
ffmpeg -ss 0.9 -i source.mp3 -t 0.95 sample1.mp3 -acodec copy -y
ffmpeg -ss 4.5 -i source.mp3 -t 0.95 sample2.mp3 -acodec copy -y
我是音频处理的新手,但我最初的想法是提取1秒音效的样本,然后在python中使用librosa为两个文件提取floating point time series浮点数,然后尝试匹配。
import numpy
import librosa
print("Load files")
source_series, source_rate = librosa.load('source.mp3') # 3 hour file
sample_series, sample_rate = librosa.load('sample.mp3') # 1 second file
print("Round series")
source_series = numpy.around(source_series, decimals=5);
sample_series = numpy.around(sample_series, decimals=5);
print("Process series")
source_start = 0
sample_matching = 0
sample_length = len(sample_series)
for source_id, source_sample in enumerate(source_series):
if source_sample == sample_series[sample_matching]:
sample_matching += 1
if sample_matching >= sample_length:
print(float(source_start) / source_rate)
sample_matching = 0
elif sample_matching == 1:
source_start = source_id;
else:
sample_matching = 0
这不适用于上面的MP3文件,但适用于MP4版本-可以找到我提取的样本,但仅仅是一个样本(并非全部12个)。
我还应注意,此脚本仅花费1分钟多的时间来处理3小时的文件(其中包括237,426,624个样本)。因此,我可以想象在每个循环上进行某种平均会导致此过程花费更长的时间。
答案 0 :(得分:1)
这是音频事件检测问题。如果声音始终相同,并且没有其他声音同时出现,则可以使用“模板匹配”方法来解决。至少如果没有其他听起来像其他意思的声音。
最简单的模板匹配方法是计算输入信号与模板之间的互相关。
您可能应该准备一些较短的测试文件,其中包含要检测的声音示例以及其他典型声音。
如果记录的音量不一致,则需要在进行检测之前将其标准化。
如果时域中的互相关不起作用,则可以计算频谱图或MFCC功能并将其互相关。如果这也不能产生良好的结果,则可以使用监督学习来训练机器学习模型,但这需要将一堆数据标记为事件/非事件。
答案 1 :(得分:1)
尝试在时域中直接匹配波形样本不是一个好主意。 mp3信号将保留感知特性,但是很可能频率分量的相位会发生偏移,因此采样值将不匹配。
您可以尝试将效果和样本的音量范围进行匹配。 这不太可能受到mp3进程的影响。
首先,对样本进行归一化,以使嵌入效果与参考效果处于同一水平。通过使用短时间内足以捕获相关特征的时间范围内的峰值平均值,从效果和样本中构造新的波形。最好还是使用重叠的框架。然后在时域中使用互相关。
如果这不起作用,则可以使用FFT分析每个帧,从而为每个帧提供一个特征向量。然后,您尝试在效果中与样本查找特征序列的匹配。与https://stackoverflow.com/users/1967571/jonnor建议类似。 MFCC用于语音识别,但由于未检测到语音,因此FFT可能还可以。
我假设效果会自己播放(没有背景噪音),并且会以电子方式添加到录制中(而不是通过麦克风录制)。如果不是这种情况,问题将变得更加困难。
答案 2 :(得分:0)
这可能不是答案,这只是我开始研究@jonnor和@ paul-john-leonard的答案之前要去的地方。
我一直在查看可以通过使用librosa stft和amplitude_to_db获得的频谱图,并认为如果我将输入到图中的数据进行四舍五入,我可以可能找到正在播放的1种音效:
https://librosa.github.io/librosa/generated/librosa.display.specshow.html
我在下面的工作中编写的代码;虽然这样:
会返回很多误报,可以通过调整视为匹配项的参数来解决。
我需要将librosa函数替换为可以解析,舍入和一次匹配检查的函数;一个3小时的音频文件会导致python在大约30分钟后甚至没有舍入位的情况下,在具有16GB RAM的计算机上用尽内存。
import sys
import numpy
import librosa
#--------------------------------------------------
if len(sys.argv) == 3:
source_path = sys.argv[1]
sample_path = sys.argv[2]
else:
print('Missing source and sample files as arguments');
sys.exit()
#--------------------------------------------------
print('Load files')
source_series, source_rate = librosa.load(source_path) # The 3 hour file
sample_series, sample_rate = librosa.load(sample_path) # The 1 second file
source_time_total = float(len(source_series) / source_rate);
#--------------------------------------------------
print('Parse Data')
source_data_raw = librosa.amplitude_to_db(abs(librosa.stft(source_series, hop_length=64)))
sample_data_raw = librosa.amplitude_to_db(abs(librosa.stft(sample_series, hop_length=64)))
sample_height = sample_data_raw.shape[0]
#--------------------------------------------------
print('Round Data') # Also switches X and Y indexes, so X becomes time.
def round_data(raw, height):
length = raw.shape[1]
data = [];
range_length = range(1, (length - 1))
range_height = range(1, (height - 1))
for x in range_length:
x_data = []
for y in range_height:
# neighbours = []
# for a in [(x - 1), x, (x + 1)]:
# for b in [(y - 1), y, (y + 1)]:
# neighbours.append(raw[b][a])
#
# neighbours = (sum(neighbours) / len(neighbours));
#
# x_data.append(round(((raw[y][x] + raw[y][x] + neighbours) / 3), 2))
x_data.append(round(raw[y][x], 2))
data.append(x_data)
return data
source_data = round_data(source_data_raw, sample_height)
sample_data = round_data(sample_data_raw, sample_height)
#--------------------------------------------------
sample_data = sample_data[50:268] # Temp: Crop the sample_data (318 to 218)
#--------------------------------------------------
source_length = len(source_data)
sample_length = len(sample_data)
sample_height -= 2;
source_timing = float(source_time_total / source_length);
#--------------------------------------------------
print('Process series')
hz_diff_match = 18 # For every comparison, how much of a difference is still considered a match - With the Source, using Sample 2, the maximum diff was 66.06, with an average of ~9.9
hz_match_required_switch = 30 # After matching "start" for X, drop to the lower "end" requirement
hz_match_required_start = 850 # Out of a maximum match value of 1023
hz_match_required_end = 650
hz_match_required = hz_match_required_start
source_start = 0
sample_matched = 0
x = 0;
while x < source_length:
hz_matched = 0
for y in range(0, sample_height):
diff = source_data[x][y] - sample_data[sample_matched][y];
if diff < 0:
diff = 0 - diff
if diff < hz_diff_match:
hz_matched += 1
# print(' {} Matches - {} @ {}'.format(sample_matched, hz_matched, (x * source_timing)))
if hz_matched >= hz_match_required:
sample_matched += 1
if sample_matched >= sample_length:
print(' Found @ {}'.format(source_start * source_timing))
sample_matched = 0 # Prep for next match
hz_match_required = hz_match_required_start
elif sample_matched == 1: # First match, record where we started
source_start = x;
if sample_matched > hz_match_required_switch:
hz_match_required = hz_match_required_end # Go to a weaker match requirement
elif sample_matched > 0:
# print(' Reset {} / {} @ {}'.format(sample_matched, hz_matched, (source_start * source_timing)))
x = source_start # Matched something, so try again with x+1
sample_matched = 0 # Prep for next match
hz_match_required = hz_match_required_start
x += 1
#--------------------------------------------------
答案 3 :(得分:0)
要跟进@jonnor和@ paul-john-leonard的回答,它们都是正确的,通过使用能够进行音频事件检测的帧(FFT)。
我在以下位置写下了完整的源代码
一些注意事项:
要创建模板,我使用了ffmpeg:
$ResourceId = (Get-AzureRmResource -ResourceType Microsoft.ServiceBus/namespaces).ResourceId
foreach($rid in $ResourceId){
New-AzureRmRoleAssignment -ObjectId <Service Principal ObjectId> -Scope $rid -RoleDefinitionName Contributor
}
我决定使用ffmpeg -ss 13.15 -i source.mp4 -t 0.8 -acodec copy -y templates/01.mp4;,但是我需要针对正在分析的3小时文件自行实现此librosa.core.stft函数,因为它太大了,无法保存记忆。
在使用stft时,我尝试使用的Hop_length最初是64,而不是默认值(512),因为我认为这将为我提供更多数据来使用...理论上可能是是的,但是64太详细了,导致大多数时候失败。
我仍然不知道如何使帧和模板之间具有互相关性(通过stft)……相反,我每帧取结果(1025个存储桶,而不是1024个,我相信与找到的Hz频率有关),并进行了非常简单的平均差异检查,然后确保平均值高于某个值(我的测试用例在0.15上工作,我使用的主要文件要求为0.55-大概是因为主文件已经压缩了很多):
numpy.correlate
hz_score = abs(source[0:1025,x] - template[2][0:1025,y])
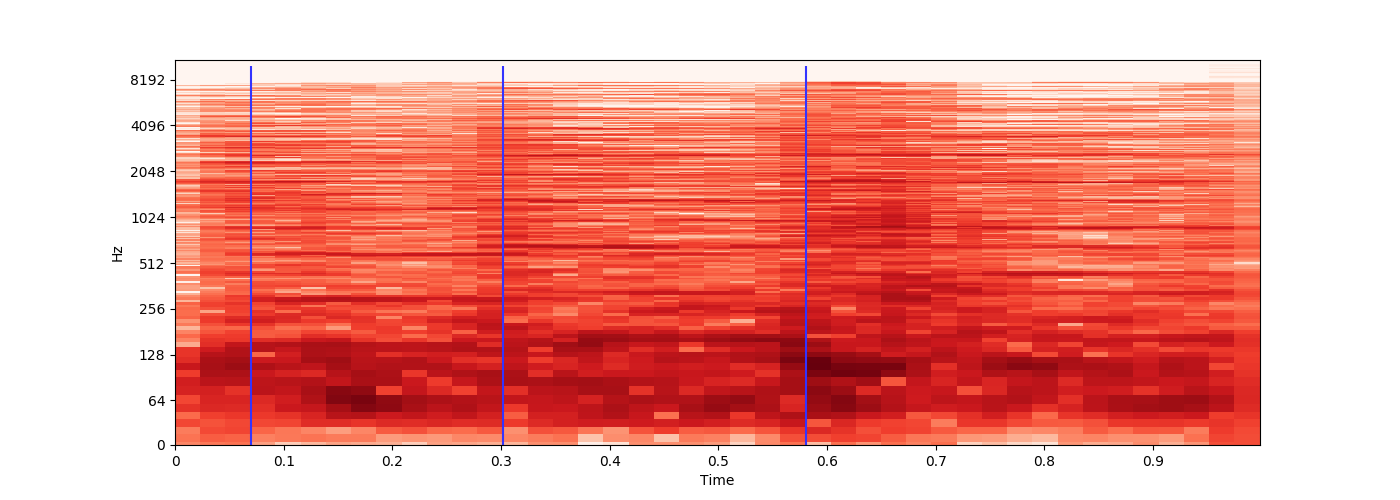
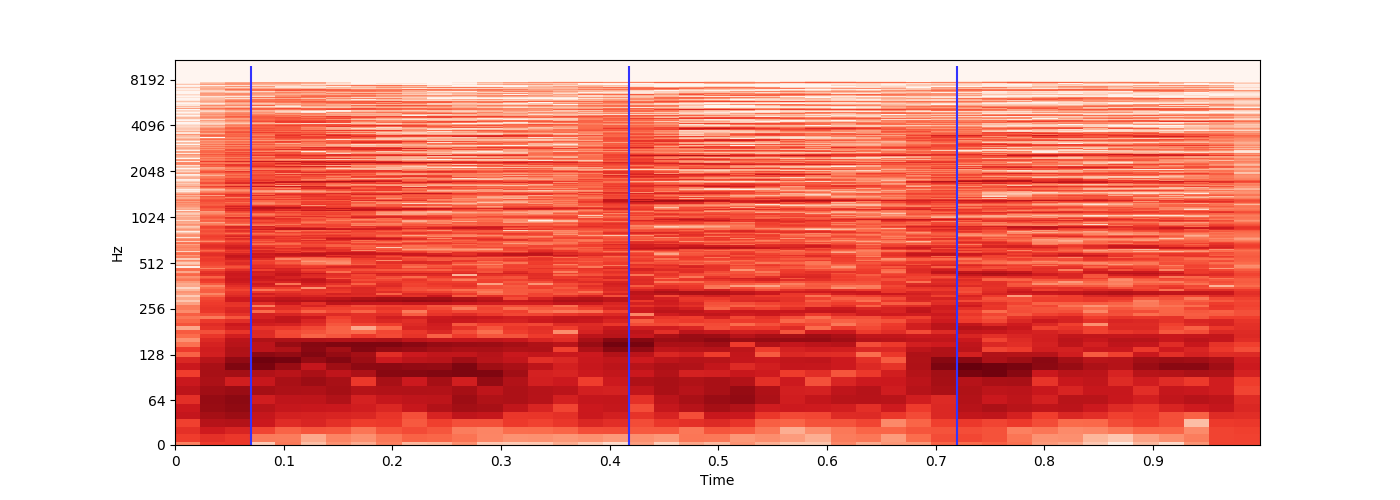
在检查这些分数时,将其显示在图表上非常有用。我经常使用以下内容:
hz_score = sum(hz_score)/float(len(hz_score))
import matplotlib.pyplot as plt
plt.figure(figsize=(30, 5))
plt.axhline(y=hz_match_required_start, color='y')
while x < source_length:
debug.append(hz_score)
if x == mark_frame:
plt.axvline(x=len(debug), ymin=0.1, ymax=1, color='r')
plt.plot(debug)
在创建模板时,您需要修剪掉所有前导的静音(以避免不匹配),以及额外的〜5帧(似乎压缩/重新编码过程会对此进行更改)...同样,删除最后2帧(我认为这些帧从其周围环境中包含了一些数据,尤其是最后一个帧可能有点偏离)。
当您开始查找匹配项时,您可能会发现前几帧没问题,然后失败了……您可能需要稍后再尝试一两帧。我发现拥有一个支持多个模板(声音略有变化)并检查其第一个可测试(例如第6个)帧的过程会更容易,如果匹配,则将它们放在潜在匹配项列表中。然后,当它前进到源的下一帧时,可以将其与模板的下一帧进行比较,直到模板中的所有帧都匹配(或失败)为止。
{kind=link}
{kind=link}