sql中的表分布和表分区之间有什么区别?
我仍在努力确定Azure SQL数据仓库中表分配的概念与Sql Server中表分区的概念有何不同?
两者的定义似乎都取得了相同的结果。
3 个答案:
答案 0 :(得分:7)
Azure DW的MPP architecture中包含多达60个计算节点。在Azure DW上存储表时,就是在这些节点之间存储表。您的表数据分布在这些节点上(根据需要使用哈希分布或循环分布)。您还可以选择在这些节点之间复制表(最好是很小的表)。

那是分布。每个节点都有自己的不同记录,只有该节点在与数据进行交互时才担心。这是什么都不共享的架构。

Partitioning完全不同于这种分配概念。在对表进行分区时,我们根据某种方案(例如,将order表用order.create_date进行分区)来决定哪些行属于哪些分区。然后,每个create_date的大块记录都存储在它自己的表中,该记录与其他create_date条记录集(在后台看不见)分开存储。
{kind=link}
分区很不错,因为您可能会发现您只想从表中选择10天的orders,因此您只需要读取10个较小的表,而不必扫描多年的{{ 1}}数据来查找您需要的10天。
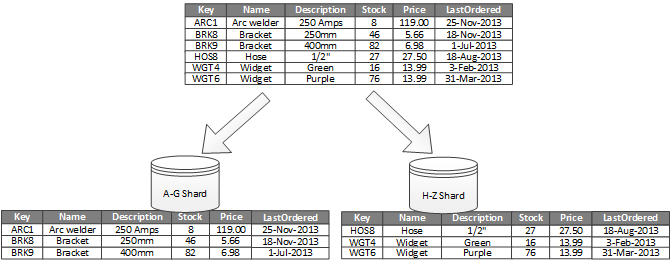
这是Microsoft网站上的一个示例,其中在order列上进行水平分区,并根据name字母顺序使用两个“分片”:

表分发是仅适用于Azure DW或Teradata等MPP类型RDBMS的概念。最容易想到的是它与某种程度上与数据脱节的硬件概念。 Azure在这里为您提供了很多控制权,其他MPP数据库则基于主键进行分发。几乎每个RDBMS都可以使用分区(无论是否有MPP),最容易将其视为由表中的数据定义并依赖于表中的数据的存储/软件概念。
最后,它们都可以解决相同的问题。但是...几乎每个RDBMS概念(索引,磁盘存储,优化,分区,分发等)都可以解决相同的问题。即:“如何尽快获取需要的确切数据?”将这些概念组合在一起以满足您的数据检索需求时,即使对巨大的数据,您也可以快速发出SQL请求CRAZY。
答案 1 :(得分:4)
只是为了好玩,让我用一个比喻解释一下。
假设有一本关于世界所有历史的巨著。它的大小为42层。
现在,如果图书馆员每年将那本书分成一本书怎么办?这使查找特定年份所需的所有信息变得更加容易。因为您可以将其他书籍放在书架上。
小书也更容易携带。
这就是表分区的目的。 (Reference: Data Partitioning in Azure)
根据一个键(或一组列)将数据块保持在一起,这对大多数查询都非常有用,并且具有良好的平均分布。
这可以减少IO,因为仅需要访问相关的块。
现在,如果首席图书管理员取消捆绑这本书怎么办。并将页面集发送到许多不同的库。
然后,当我们需要某些信息时,我们要求每个图书馆向我们发送所需页面的副本。
更好的是,这些图书馆员已经可以汇总其页面的信息,然后仅将其摘要发送到一个图书馆为您收集这些信息。
这就是表分配的含义。 (Reference: Table Distribution Guidance in Azure)
将数据分散到不同的节点上。
答案 2 :(得分:0)
从概念上讲,它们是相同的。基本思想是将数据拆分到多个存储中。但是,实现方式完全不同。在幕后,Azure SQL数据仓库管理和维护70个数据库,您定义的每个表都在其中创建。除了定义键,您什么也不做。分发已处理。对于分区,您必须定义和维护几乎所有内容才能使其正常工作。甚至还有更多,但您有核心思想。这些是在宏级别到达相似终点的不同过程和机制。但是,这些东西支持的过程是非常不同的。分发有助于提高性能,而分区主要是改善数据管理(滚动窗口等)的一种方式。尽管它们是相似的,但它们具有不同的意图,并且具有不同的意图。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?