我是R的新手,我试图在整数组中找到几个月(3,6,9)的滚动标准偏差。例如,对于一年的数据和三组,我想找到(1月,2月,3月),(2月,3月,4月)每个组1,2,3的标准偏差,(3月,4月, ())等等。
在我的数据框df中,我有列NUM:用于查找标准差的值,列NO:定义组的整数和列日期:具有每日日期。我还创建了列Yr_Mo,这是一个对应于日期年份和月份的整数。因此,例如,2017年的所有1月份日期在Yr_Mo列中的值为1701
一个月后,我使用了聚合: new< - aggregate(NUM~Yr_Mo + NO,df,sd)
这是非常基本的。然而,对于3个月以上的人来说,这似乎更复杂。因为不是所有的月份都是相同的长度而且几个月都缺少日期,所以我无法对某些时间间隔进行硬编码。我已经看过很多关于类似问题的帖子,但这些问题似乎总体上要求找到滚动的std devs或者分组,但不是两者。我在考虑使用rollapply这样的动物园功能,但是再次看不出如何考虑我的问题的两个部分。
提前感谢您提供的任何帮助或指向我可能从中学习的文档!
NO date Yr_Mo NUM
1 2017-01-01 1701 3.4
1 2017-01-02 1701 5
1 2017-01-12 1701 4.2
1 2017-01-13 1701 1
1 2017-01-20 1701 6
1 2017-02-03 1702 3.9
1 2017-02-08 1702 5.5
1 2017-02-15 1702 8
1 2017-02-22 1702 1.1
1 2017-02-26 1702 4
1 2017-03-02 1703 1
1 2017-03-07 1703 7.5
1 2017-03-11 1703 2
1 2017-03-20 1703 3.1
1 2017-03-28 1703 2
1 2017-04-01 1704 2
1 2017-04-05 1704 3.5
1 2017-04-12 1704 1
1 2017-04-19 1704 4.1
1 2017-04-23 1704 5
1 2017-05-02 1705 1
1 2017-05-03 1705 4.5
1 2017-05-04 1705 2
1 2017-05-10 1705 6.1
1 2017-05-20 1705 7
2 2017-01-01 1701 3
2 2017-01-02 1701 53
2 2017-01-11 1701 2
2 2017-01-15 1701 4.1
2 2017-01-22 1701 1
2 2017-02-01 1702 8.9
2 2017-02-08 1702 1.5
2 2017-02-15 1702 3
2 2017-02-27 1702 7.2
2 2017-02-28 1702 4
2 2017-03-02 1703 1
2 2017-03-07 1703 5.2
2 2017-03-11 1703 2
2 2017-03-21 1703 1
2 2017-03-28 1703 2
2 2017-04-01 1704 2.4
2 2017-04-05 1704 3.5
2 2017-04-11 1704 1
2 2017-04-19 1704 4.1
2 2017-04-23 1704 3
2 2017-05-02 1705 1.2
2 2017-05-03 1705 4.5
2 2017-05-04 1705 2
2 2017-05-10 1705 6.1
2 2017-05-21 1705 9
答案 0 :(得分:2)
使用方差的定义(参见sample variance)以及OP在问题中提到的内容(即aggregate和rollapply),我们可以如下计算滚动3个月标准差。内联更多评论。
winsize <- 3
#calculate sum of squares of NUM by month and group
sumxsq <- aggregate(NUM ~ Yr_Mo + NO, df, function(x) sum(x^2))
names(sumxsq) <- c("Yr_Mo", "NO", "SUM_X_SQ")
#calculate sum of NUM by month and group
sumx <- aggregate(NUM ~ Yr_Mo + NO, df, sum)
names(sumx) <- c("Yr_Mo", "NO", "SUM_X")
#count number of observations by month and group
nobs <- aggregate(NUM ~ Yr_Mo + NO, df, length)
names(nobs) <- c("Yr_Mo", "NO", "N")
#merge all stats together
mySD <- merge(merge(sumxsq, sumx, by=c("NO","Yr_Mo")), nobs, by=c("NO","Yr_Mo"))
#calculate rolling sample variance using zoo::rollapplyr by group, then take sqrt for sd
mySD$STD_DEV <- sqrt(unlist(by(mySD, mySD$NO, function(submySD) {
zoo::rollapplyr(submySD,
width=winsize,
FUN=function(x) (sum(x[,"SUM_X_SQ"]) - sum(x[,"SUM_X"])^2 / sum(x[,"N"])) / (sum(x[,"N"]) - 1),
by.column=FALSE,
fill=NA)
})))
mySD
解决方案假设每个组每个月至少有1个数据点。如果有帮助,请告诉我。
数据:
df <- read.csv(text="NO,date,Yr_Mo,NUM
1,2017-01-01,1701,3.4
1,2017-01-02,1701,5
1,2017-01-12,1701,4.2
1,2017-01-13,1701,1
1,2017-01-20,1701,6
1,2017-02-03,1702,3.9
1,2017-02-08,1702,5.5
1,2017-02-15,1702,8
1,2017-02-22,1702,1.1
1,2017-02-26,1702,4
1,2017-03-02,1703,1
1,2017-03-07,1703,7.5
1,2017-03-11,1703,2
1,2017-03-20,1703,3.1
1,2017-03-28,1703,2
1,2017-04-01,1704,2
1,2017-04-05,1704,3.5
1,2017-04-12,1704,1
1,2017-04-19,1704,4.1
1,2017-04-23,1704,5
1,2017-05-02,1705,1
1,2017-05-03,1705,4.5
1,2017-05-04,1705,2
1,2017-05-10,1705,6.1
1,2017-05-20,1705,7
2,2017-01-01,1701,3
2,2017-01-02,1701,53
2,2017-01-11,1701,2
2,2017-01-15,1701,4.1
2,2017-01-22,1701,1
2,2017-02-01,1702,8.9
2,2017-02-08,1702,1.5
2,2017-02-15,1702,3
2,2017-02-27,1702,7.2
2,2017-02-28,1702,4
2,2017-03-02,1703,1
2,2017-03-07,1703,5.2
2,2017-03-11,1703,2
2,2017-03-21,1703,1
2,2017-03-28,1703,2
2,2017-04-01,1704,2.4
2,2017-04-05,1704,3.5
2,2017-04-11,1704,1
2,2017-04-19,1704,4.1
2,2017-04-23,1704,3
2,2017-05-02,1705,1.2
2,2017-05-03,1705,4.5
2,2017-05-04,1705,2
2,2017-05-10,1705,6.1
2,2017-05-21,1705,9", header=TRUE)
答案 1 :(得分:1)
您可以创建一个分割数据的函数,使用 Yr_Mo列创建子集的上下边界,然后只获取子集范围的sd()值。其中df是您在上面提供的数据集,首先重新排列数据集(不需要,但更容易检查输出是否正确)
抱歉,完全错过了您想要保留NO分组。这应该可以解决问题(df这里是您上面提供的示例数据):
此函数迭代每个唯一的Yr_Mo值,以生成范围的上限和下限(在本例中为x - 1:x + 1)。然后,它会根据这些边界对提供的数据框进行子集,并计算sd的{{1}}。如果子集无效(时间范围可用的时间少于三个月),则输出为NUM。
NA然后,使用roll_sd <- function(df_, lead = 1, lag = -1) {
id_sd <- do.call(rbind, lapply(unique(df_$Yr_Mo), function(x) {
start = x + lag
end = x + lead
group = df_[df_$Yr_Mo >= start & df_$Yr_Mo <= end,]
group_sd = sd(group$NUM)
group_sd = ifelse(length(unique(group$Yr_Mo)) < 3, NA, sd(group$NUM))
out = data.frame(central_value = x, group_sd)
})
)
}
将此功能应用于group_by的每个分组:
NO library(dplyr)
df2 <- df %>%
group_by(NO) %>%
do(roll_sd(data.frame(.)))
> as.data.frame(df2)
NO central_value group_sd
1 1 1701 NA
2 1 1702 2.248449
3 1 1703 2.209460
4 1 1704 2.179406
5 1 1705 NA
6 2 1701 NA
7 2 1702 13.046809
8 2 1703 2.311833
9 2 1704 2.270305
10 2 1705 NA
列是&#34;中间&#34;滑动窗口的月份值。
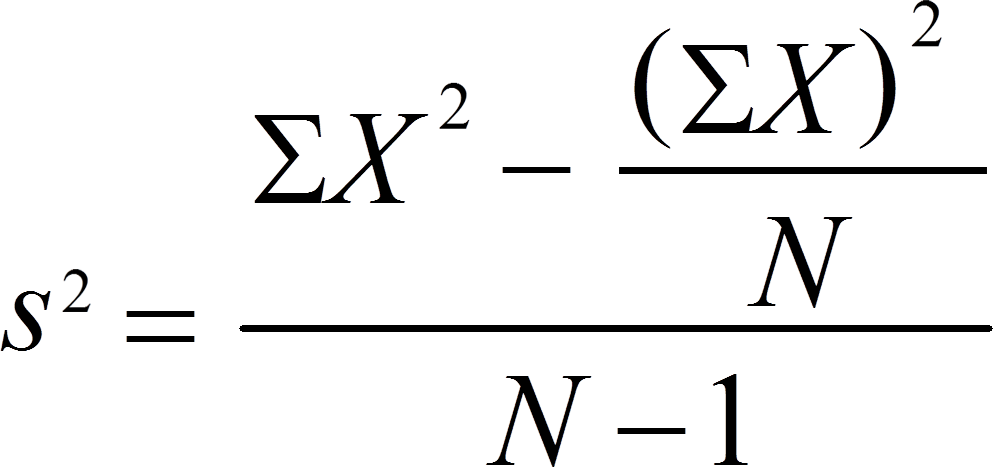{kind=link}