顺序树遍历:哪个定义是正确的?
我从以前的一个学术课程中得到以下文字:关于二叉树(不是BST)的顺序遍历(他们也称之为pancaking):
顺序树遍历
在外围画一条线 树。从根的左边开始, 绕过树的外面, 结束根的权利。 尽量靠近树, 但是不要越过树。 (考虑到 树 - 它的分支和节点 - 如 一个坚实的障碍。)的顺序 nodes是此行的顺序 从他们下面经过。如果你是 不确定你什么时候去“下面” 一个节点,记住一个节点“到了 离开“永远是第一位的。
这是使用的示例(从下面略微不同的树)
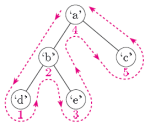
然而,当我在谷歌搜索时,我得到一个相互矛盾的定义。例如wikipedia example:

按顺序遍历序列:A,B,C, D,E,F,G,H,I (leftchild,rootnode,right node)
但根据(我的理解)定义#1,这应该是
A,B,D,C,E,F,G,I,H
任何人都可以澄清哪个定义是正确的吗?他们可能都在描述不同的遍历方法,但碰巧使用相同的名称。我很难相信同行评审的学术文本是错误的,但不能确定。
14 个答案:
答案 0 :(得分:35)
在我对绘图的不良尝试中,这是显示如何挑选它们的顺序。

几乎选择正在绘制的线上方的节点。
答案 1 :(得分:25)
忘记定义,只需应用算法就容易多了:
void inOrderPrint(Node root)
{
if (root.left != null) inOrderPrint(root.left);
print(root.name);
if (root.right != null) inOrderPrint(root.right);
}
这只是三行。重新排列订单前后的订单。
答案 2 :(得分:4)
如果您仔细阅读,您会看到第一个“定义”表示启动根 left ,并且当您在下传递时确定节点的顺序他们。因此,B不是第一个节点,因为您在前往A的路上从左侧传递,然后首先在 A下传递,之后您上升并在 B下传递。因此,似乎两个定义都给出了相同的结果。
答案 3 :(得分:2)
我个人认为this lecture非常有帮助。
答案 4 :(得分:1)
两个定义都给出了相同的结果。不要被第一个例子中的字母所迷惑 - 看看路径上的数字。第二个例子确实使用字母来表示路径 - 也许这就是让你失望的原因。
例如,在您的示例顺序中显示您如何使用第一个树的算法遍历第二个树,您将“D”放在“B”之后,但您不应该因为还有左手D的子节点可用(这就是为什么第一个项目表示“此行通过在下面的顺序”。
答案 5 :(得分:1)
我认为第一个具有a根的二叉树是一个未正确构造的二叉树。
尝试实现,以便树的所有左侧都小于根,并且树的所有右侧都大于或等于根。
答案 6 :(得分:1)
这可能会迟到但以后对任何人都有用.. 你只需要不要忽略虚节点或空节点,例如节点G有一个左空节点。考虑到这个空节点将使每一件事都好。
答案 7 :(得分:1)
正确的遍历将是:尽可能远离叶节点(不是根节点)
左右根
A B NULL
C D E
Null F G
H I NULL
F是root还是left,我不确定
答案 8 :(得分:0)
但根据(我的理解) 定义#1,这应该是
A, B, D, C, E, F, G, I, H
不幸的是,你的理解是错误的。
每当到达节点时,必须先下降到可用的左节点,然后再查看当前节点,然后查看可用的右节点。 当你在C之前选择D时,你没有先下降到左边的节点。
答案 9 :(得分:0)
嘿,根据我在维基中提到的是正确的,顺序遍历的顺序是左右根。
直到A,B,C,D,E,F我认为你已经理解了。现在在根F之后,下一个节点是G,它不具有左节点而是具有右节点,因此根据规则(左 - 右 - 右)它的null-g-right。现在我是G的正确节点,但我有一个左节点,因此遍历将是GHI。这是正确的。
希望这有帮助。
答案 10 :(得分:0)
对于内联树遍历,您必须记住遍历的顺序是左节点右侧。对于您遇到冲突的上图,在读取左侧任何叶子(子)节点之前读取父节点时会发生错误。
正确的遍历将是:尽可能离开叶子节点(A),返回父节点(B),向右移动,但由于D左边有一个孩子,你再次向下移动(C) ,回到C的父母(D),到D的右边的孩子(E),反向回到根(F),移到右边的叶子(G),移动到G的叶子但是因为它有一个左叶子节点移动到那里(H),回到父母(I)。
上面的遍历在我将它列在括号中时读取节点。
答案 11 :(得分:0)
包数据结构;
公共类BinaryTreeTraversal {
public static Node<Integer> node;
public static Node<Integer> sortedArrayToBST(int arr[], int start, int end) {
if (start > end)
return null;
int mid = start + (end - start) / 2;
Node<Integer> node = new Node<Integer>();
node.setValue(arr[mid]);
node.left = sortedArrayToBST(arr, start, mid - 1);
node.right = sortedArrayToBST(arr, mid + 1, end);
return node;
}
public static void main(String[] args) {
int[] test = new int[] { 1, 2, 3, 4, 5, 6, 7 };
Node<Integer> node = sortedArrayToBST(test, 0, test.length - 1);
System.out.println("preOrderTraversal >> ");
preOrderTraversal(node);
System.out.println("");
System.out.println("inOrderTraversal >> ");
inOrderTraversal(node);
System.out.println("");
System.out.println("postOrderTraversal >> ");
postOrderTraversal(node);
}
public static void preOrderTraversal(Node<Integer> node) {
if (node != null) {
System.out.print(" " + node.toString());
preOrderTraversal(node.left);
preOrderTraversal(node.right);
}
}
public static void inOrderTraversal(Node<Integer> node) {
if (node != null) {
inOrderTraversal(node.left);
System.out.print(" " + node.toString());
inOrderTraversal(node.right);
}
}
public static void postOrderTraversal(Node<Integer> node) {
if (node != null) {
postOrderTraversal(node.left);
postOrderTraversal(node.right);
System.out.print(" " + node.toString());
}
}
}
包数据结构;
public class Node {
E value = null;
Node<E> left;
Node<E> right;
public E getValue() {
return value;
}
public void setValue(E value) {
this.value = value;
}
public Node<E> getLeft() {
return left;
}
public void setLeft(Node<E> left) {
this.left = left;
}
public Node<E> getRight() {
return right;
}
public void setRight(Node<E> right) {
this.right = right;
}
@Override
public String toString() {
return " " +value;
}
}
preOrderTraversal&gt;&gt; 4 2 1 3 6 5 7 inOrderTraversal&gt;&gt; 1 2 3 4 5 6 7 postOrderTraversal&gt;&gt; 1 3 2 5 7 6 4
答案 12 :(得分:0)
void
inorder (NODE root)
{
if (root != NULL)
{
inorder (root->llink);
printf ("%d\t", root->info);
inorder (root->rlink);
}
}
这是递归定义有序遍历的最简单方法,只需在main函数中调用此函数即可获得给定二叉树的有序遍历。
答案 13 :(得分:-2)
预订是正确的,nt是为了顺序
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?