TensorFlow:如何将浮点序列嵌入到固定大小的向量中?
我正在寻找将浮点值嵌入到固定大小向量的可变长度序列的方法。输入格式如下:
[f1,f2,f3,f4]->[f1,f2,f3,f4]->[f1,f2,f3,f4]-> ... -> [f1,f2,f3,f4]
[f1,f2,f3,f4]->[f1,f2,f3,f4]->[f1,f2,f3,f4]->[f1,f2,f3,f4]-> ... -> [f1,f2,f3,f4]
...
[f1,f2,f3,f4]-> ... -> ->[f1,f2,f3,f4]
每一行是一个可变长度的sequnece,最大长度为60.一个sequece中的每个单位是一个4浮点值的元组。我已经用零填充所有序列来填充相同的长度。
如果我将输出与输入相同,以下架构似乎解决了我的问题,我需要中心的思想向量作为序列的嵌入。
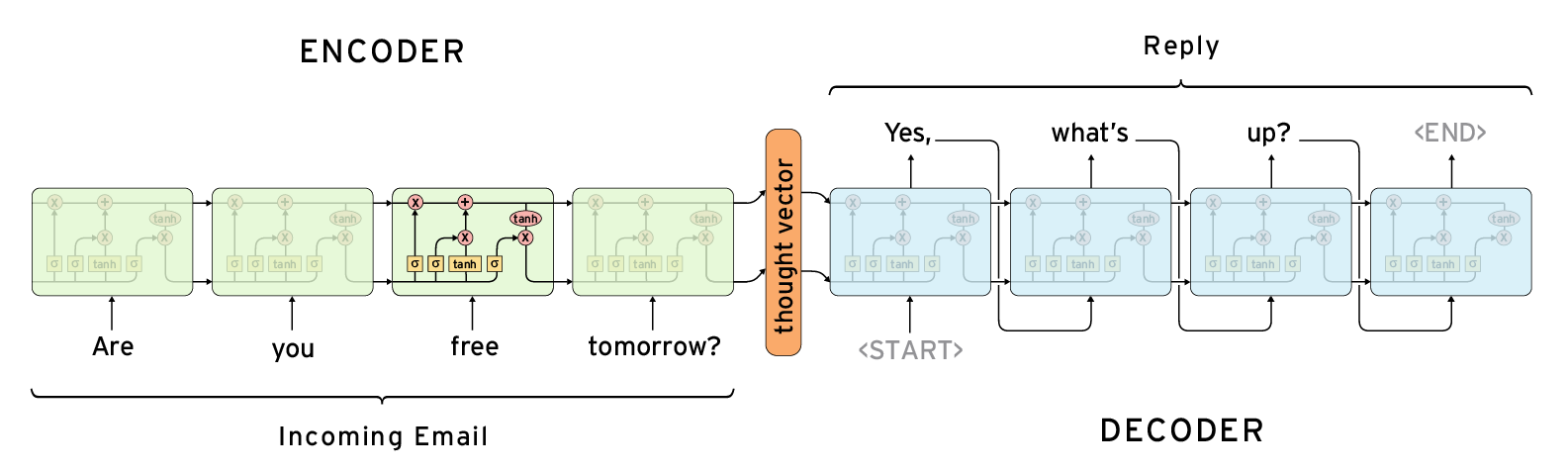
在tensorflow中,我找到了两种候选方法tf.contrib.legacy_seq2seq.basic_rnn_seq2seq和tf.contrib.legacy_seq2seq.embedding_rnn_seq2seq。
然而,这些两种方法似乎用于解决NLP问题,输入必须是单词的离散值。
那么,还有其他功能可以解决我的问题吗?
3 个答案:
答案 0 :(得分:2)
所有你需要的只是一个RNN,而不是seq2seq模型,因为seq2seq附带一个额外的解码器,在你的情况下是不必要的。
示例代码:
import numpy as np
import tensorflow as tf
from tensorflow.contrib import rnn
input_size = 4
max_length = 60
hidden_size=64
output_size = 4
x = tf.placeholder(tf.float32, shape=[None, max_length, input_size], name='x')
seqlen = tf.placeholder(tf.int64, shape=[None], name='seqlen')
lstm_cell = rnn.BasicLSTMCell(hidden_size, forget_bias=1.0)
outputs, states = tf.nn.dynamic_rnn(cell=lstm_cell, inputs=x, sequence_length=seqlen, dtype=tf.float32)
encoded_states = states[-1]
W = tf.get_variable(
name='W',
shape=[hidden_size, output_size],
dtype=tf.float32,
initializer=tf.random_normal_initializer())
b = tf.get_variable(
name='b',
shape=[output_size],
dtype=tf.float32,
initializer=tf.random_normal_initializer())
z = tf.matmul(encoded_states, W) + b
results = tf.sigmoid(z)
###########################
## cost computing and training components goes here
# e.g.
# targets = tf.placeholder(tf.float32, shape=[None, input_size], name='targets')
# cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=targets, logits=z))
# optimizer = tf.train.AdamOptimizer(learning_rate=0.1).minimize(cost)
###############################
init = tf.global_variables_initializer()
batch_size = 4
data_in = np.zeros((batch_size, max_length, input_size), dtype='float32')
data_in[0, :4, :] = np.random.rand(4, input_size)
data_in[1, :6, :] = np.random.rand(6, input_size)
data_in[2, :20, :] = np.random.rand(20, input_size)
data_in[3, :, :] = np.random.rand(60, input_size)
data_len = np.asarray([4, 6, 20, 60], dtype='int64')
with tf.Session() as sess:
sess.run(init)
#########################
# training process goes here
#########################
res = sess.run(results,
feed_dict={
x: data_in,
seqlen: data_len})
print(res)
答案 1 :(得分:1)
要将序列编码为固定长度的矢量,通常使用递归神经网络(RNN)或卷积神经网络(CNN)。
如果使用递归神经网络,则可以使用最后一步的输出(序列中的最后一个元素)。这对应于您问题中的思维向量。看看tf.dynamic_rnn。 dynamic_rnn要求您指定要使用的RNN单元格的类型。 tf.contrib.rnn.LSTMCell和tf.contrib.rnn.GRUCell是最常见的。
如果您想使用CNN,则需要使用1维卷积。要构建CNN,您需要tf.layers.conv1d和tf.layers.max_pooling1d
答案 2 :(得分:0)
我找到了解决我的问题的方法,使用以下架构,
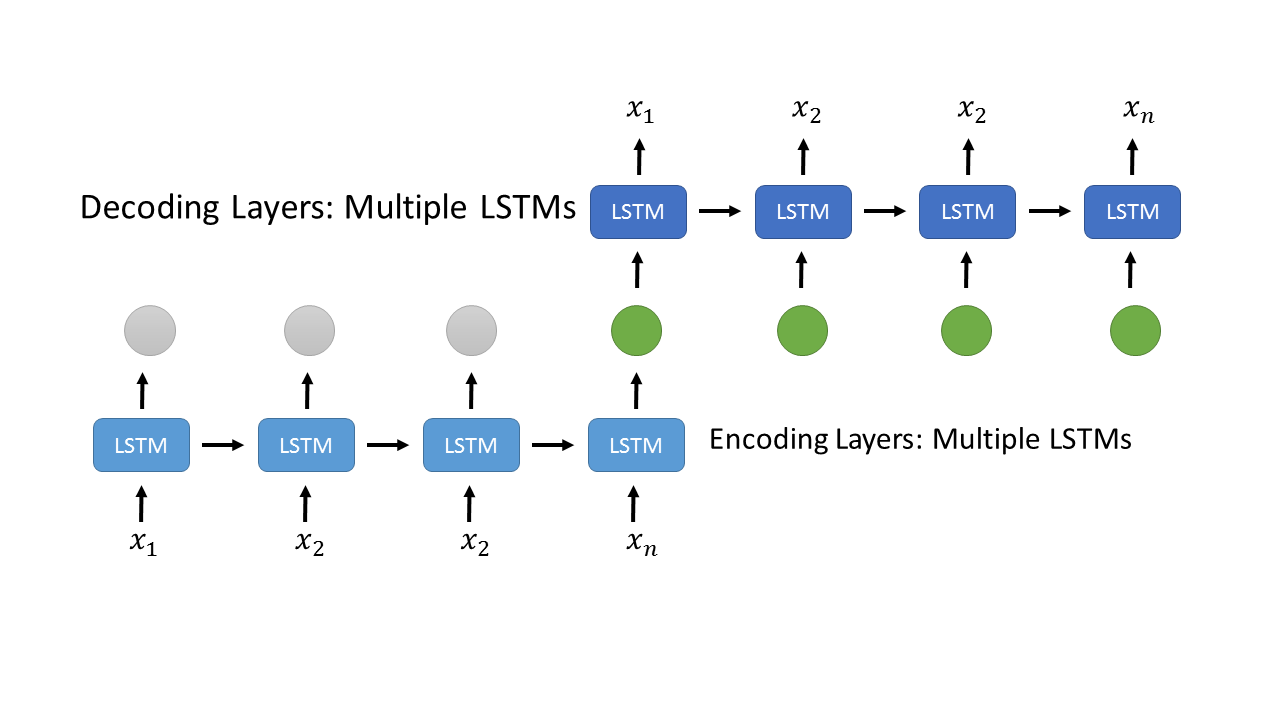 ,
,
下面的LSTMs层编码系列x1,x2,...,xn。最后一个输出(绿色输出)被复制到与上述解码LSTM层的输入相同的计数。张量流代码如下
series_input = tf.placeholder(tf.float32, [None, conf.max_series, conf.series_feature_num])
print("Encode input Shape", series_input.get_shape())
# encoding layer
encode_cell = tf.contrib.rnn.MultiRNNCell(
[tf.contrib.rnn.BasicLSTMCell(conf.rnn_hidden_num, reuse=False) for _ in range(conf.rnn_layer_num)]
)
encode_output, _ = tf.nn.dynamic_rnn(encode_cell, series_input, dtype=tf.float32, scope='encode')
print("Encode output Shape", encode_output.get_shape())
# last output
encode_output = tf.transpose(encode_output, [1, 0, 2])
last = tf.gather(encode_output, int(encode_output.get_shape()[0]) - 1)
# duplite the last output of the encoding layer
decoder_input = tf.stack([last for _ in range(conf.max_series)], axis=1)
print("Decoder input shape", decoder_input.get_shape())
# decoding layer
decode_cell = tf.contrib.rnn.MultiRNNCell(
[tf.contrib.rnn.BasicLSTMCell(conf.series_feature_num, reuse=False) for _ in range(conf.rnn_layer_num)]
)
decode_output, _ = tf.nn.dynamic_rnn(decode_cell, decoder_input, dtype=tf.float32, scope='decode')
print("Decode output", decode_output.get_shape())
# Loss Function
loss = tf.losses.mean_squared_error(labels=series_input, predictions=decode_output)
print("Loss", loss)
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?