在Python中展平浅层列表
是否有一种简单的方法可以使用列表推导来展平迭代列表,或者如果没有这样做,你会认为什么是平衡这样的浅层列表,平衡性能和可读性的最佳方法?
我尝试使用嵌套列表理解来压缩这样的列表,如下所示:
[image for image in menuitem for menuitem in list_of_menuitems]
但我遇到了NameError种类的麻烦,因为name 'menuitem' is not defined。在谷歌搜索和浏览Stack Overflow后,我得到了reduce语句所需的结果:
reduce(list.__add__, map(lambda x: list(x), list_of_menuitems))
但是这个方法相当难以理解,因为我需要list(x)调用它,因为x是Django QuerySet对象。
结论:
感谢所有为此问题做出贡献的人。以下是我学到的内容摘要。我也将其作为社区维基,以防其他人想要添加或更正这些观察结果。
我原来的reduce语句是多余的,用这种方式编写得更好:
>>> reduce(list.__add__, (list(mi) for mi in list_of_menuitems))
这是嵌套列表理解的正确语法(Brilliant summary dF!):
>>> [image for mi in list_of_menuitems for image in mi]
但这些方法都不如使用itertools.chain:
>>> from itertools import chain
>>> list(chain(*list_of_menuitems))
正如@cdleary指出的那样,通过使用chain.from_iterable来避免*操作员魔法可能是更好的风格:
>>> chain = itertools.chain.from_iterable([[1,2],[3],[5,89],[],[6]])
>>> print(list(chain))
>>> [1, 2, 3, 5, 89, 6]
23 个答案:
答案 0 :(得分:286)
如果您只想迭代数据结构的扁平化版本并且不需要可索引序列,请考虑itertools.chain and company。
>>> list_of_menuitems = [['image00', 'image01'], ['image10'], []]
>>> import itertools
>>> chain = itertools.chain(*list_of_menuitems)
>>> print(list(chain))
['image00', 'image01', 'image10']
它可以处理任何可迭代的东西,其中应包括Django的可迭代QuerySet,看起来你正在问题中使用它。
编辑:无论如何,这可能与reduce一样好,因为reduce会将项目复制到正在扩展的列表中。如果您在结束时运行chain,list(chain)只会产生相同的开销。
Meta-Edit:实际上,它比问题的建议解决方案的开销更少,因为当您使用临时扩展原始文件时,您会丢弃您创建的临时列表。
修改:由于J.F. Sebastian says itertools.chain.from_iterable避免了解包,您应该使用它来避免*魔术,但the timeit app显示可忽略不计的性能差异
答案 1 :(得分:262)
你几乎拥有它! way to do nested list comprehensions将for语句的顺序与常规嵌套for语句中的顺序相同。
因此,这个
for inner_list in outer_list:
for item in inner_list:
...
对应
[... for inner_list in outer_list for item in inner_list]
所以你想要
[image for menuitem in list_of_menuitems for image in menuitem]
答案 2 :(得分:126)
@S.Lott:你鼓励我写一个timeit app。
我认为它也会根据分区数量(容器列表中的迭代器数量)而有所不同 - 您的评论没有提到30个项目中有多少个分区。这个图在每次运行中展平了一千个项目,分区数量不同。这些项目均匀分布在分区中。
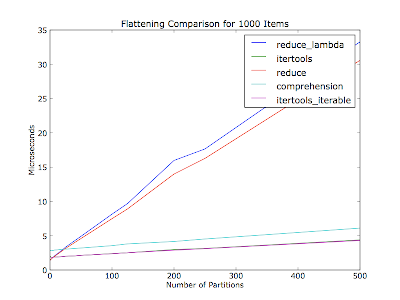
代码(Python 2.6):
#!/usr/bin/env python2.6
"""Usage: %prog item_count"""
from __future__ import print_function
import collections
import itertools
import operator
from timeit import Timer
import sys
import matplotlib.pyplot as pyplot
def itertools_flatten(iter_lst):
return list(itertools.chain(*iter_lst))
def itertools_iterable_flatten(iter_iter):
return list(itertools.chain.from_iterable(iter_iter))
def reduce_flatten(iter_lst):
return reduce(operator.add, map(list, iter_lst))
def reduce_lambda_flatten(iter_lst):
return reduce(operator.add, map(lambda x: list(x), [i for i in iter_lst]))
def comprehension_flatten(iter_lst):
return list(item for iter_ in iter_lst for item in iter_)
METHODS = ['itertools', 'itertools_iterable', 'reduce', 'reduce_lambda',
'comprehension']
def _time_test_assert(iter_lst):
"""Make sure all methods produce an equivalent value.
:raise AssertionError: On any non-equivalent value."""
callables = (globals()[method + '_flatten'] for method in METHODS)
results = [callable(iter_lst) for callable in callables]
if not all(result == results[0] for result in results[1:]):
raise AssertionError
def time_test(partition_count, item_count_per_partition, test_count=10000):
"""Run flatten methods on a list of :param:`partition_count` iterables.
Normalize results over :param:`test_count` runs.
:return: Mapping from method to (normalized) microseconds per pass.
"""
iter_lst = [[dict()] * item_count_per_partition] * partition_count
print('Partition count: ', partition_count)
print('Items per partition:', item_count_per_partition)
_time_test_assert(iter_lst)
test_str = 'flatten(%r)' % iter_lst
result_by_method = {}
for method in METHODS:
setup_str = 'from test import %s_flatten as flatten' % method
t = Timer(test_str, setup_str)
per_pass = test_count * t.timeit(number=test_count) / test_count
print('%20s: %.2f usec/pass' % (method, per_pass))
result_by_method[method] = per_pass
return result_by_method
if __name__ == '__main__':
if len(sys.argv) != 2:
raise ValueError('Need a number of items to flatten')
item_count = int(sys.argv[1])
partition_counts = []
pass_times_by_method = collections.defaultdict(list)
for partition_count in xrange(1, item_count):
if item_count % partition_count != 0:
continue
items_per_partition = item_count / partition_count
result_by_method = time_test(partition_count, items_per_partition)
partition_counts.append(partition_count)
for method, result in result_by_method.iteritems():
pass_times_by_method[method].append(result)
for method, pass_times in pass_times_by_method.iteritems():
pyplot.plot(partition_counts, pass_times, label=method)
pyplot.legend()
pyplot.title('Flattening Comparison for %d Items' % item_count)
pyplot.xlabel('Number of Partitions')
pyplot.ylabel('Microseconds')
pyplot.show()
修改:决定将其设为社区维基。
注意: METHODS可能应该与装饰者一起累积,但我认为人们更容易阅读这种方式。
答案 3 :(得分:44)
sum(list_of_lists, [])会压扁它。
l = [['image00', 'image01'], ['image10'], []]
print sum(l,[]) # prints ['image00', 'image01', 'image10']
答案 4 :(得分:37)
此解决方案适用于任意嵌套深度 - 不仅仅是“列表列表”深度,其他解决方案中的一些(全部?)仅限于:
def flatten(x):
result = []
for el in x:
if hasattr(el, "__iter__") and not isinstance(el, basestring):
result.extend(flatten(el))
else:
result.append(el)
return result
这是允许任意深度嵌套的递归 - 直到你达到最大递归深度,当然......
答案 5 :(得分:23)
在Python 2.6中,使用chain.from_iterable():
>>> from itertools import chain
>>> list(chain.from_iterable(mi.image_set.all() for mi in h.get_image_menu()))
避免创建中间列表。
答案 6 :(得分:22)
表现结果。修改。
import itertools
def itertools_flatten( aList ):
return list( itertools.chain(*aList) )
from operator import add
def reduce_flatten1( aList ):
return reduce(add, map(lambda x: list(x), [mi for mi in aList]))
def reduce_flatten2( aList ):
return reduce(list.__add__, map(list, aList))
def comprehension_flatten( aList ):
return list(y for x in aList for y in x)
我将30个项目的2级列表展平1000次
itertools_flatten 0.00554
comprehension_flatten 0.00815
reduce_flatten2 0.01103
reduce_flatten1 0.01404
减少总是一个糟糕的选择。
答案 7 :(得分:15)
似乎与operator.add混淆了!当您将两个列表一起添加时,正确的术语是concat,而不是添加。 operator.concat是你需要使用的。
如果您正在考虑功能,那就像这个一样简单:
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9))
>>> reduce(operator.concat, list2d)
(1, 2, 3, 4, 5, 6, 7, 8, 9)
你看到reduce尊重序列类型,所以当你提供一个元组时,你会得到一个元组。让我们尝试使用list ::
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> reduce(operator.concat, list2d)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
表现如何::
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> %timeit list(itertools.chain.from_iterable(list2d))
1000000 loops, best of 3: 1.36 µs per loop
from_iterable非常快!但是用concat减少它是没有比较的。
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9))
>>> %timeit reduce(operator.concat, list2d)
1000000 loops, best of 3: 492 ns per loop
答案 8 :(得分:8)
离开我的头顶,你可以消除lambda:
reduce(list.__add__, map(list, [mi.image_set.all() for mi in list_of_menuitems]))
甚至消除地图,因为你已经有了list-comp:
reduce(list.__add__, [list(mi.image_set.all()) for mi in list_of_menuitems])
您也可以将其表达为一系列列表:
sum([list(mi.image_set.all()) for mi in list_of_menuitems], [])
答案 9 :(得分:7)
这是使用列表推导的正确解决方案(它们在问题中是向后的):
>>> join = lambda it: (y for x in it for y in x)
>>> list(join([[1,2],[3,4,5],[]]))
[1, 2, 3, 4, 5]
在你的情况下,它将是
[image for menuitem in list_of_menuitems for image in menuitem.image_set.all()]
或者您可以使用join并说
join(menuitem.image_set.all() for menuitem in list_of_menuitems)
在任何一种情况下,问题都是for循环的嵌套。
答案 10 :(得分:3)
l=[[1,2,3],[4,5,6], [7], [8,9]]*33
run("list(flatten(l))")
3732 function calls (3303 primitive calls) in 0.007 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.007 0.007 <string>:1(<module>)
429 0.001 0.000 0.001 0.000 cbook.py:475(iterable)
429 0.002 0.000 0.003 0.000 cbook.py:484(is_string_like)
429 0.002 0.000 0.006 0.000 cbook.py:565(is_scalar_or_string)
727/298 0.001 0.000 0.007 0.000 cbook.py:605(flatten)
429 0.000 0.000 0.001 0.000 core.py:5641(isMaskedArray)
858 0.001 0.000 0.001 0.000 {isinstance}
429 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*66
run("list(flatten(l))")
7461 function calls (6603 primitive calls) in 0.007 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.007 0.007 <string>:1(<module>)
858 0.001 0.000 0.001 0.000 cbook.py:475(iterable)
858 0.002 0.000 0.003 0.000 cbook.py:484(is_string_like)
858 0.002 0.000 0.006 0.000 cbook.py:565(is_scalar_or_string)
1453/595 0.001 0.000 0.007 0.000 cbook.py:605(flatten)
858 0.000 0.000 0.001 0.000 core.py:5641(isMaskedArray)
1716 0.001 0.000 0.001 0.000 {isinstance}
858 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*99
run("list(flatten(l))")
11190 function calls (9903 primitive calls) in 0.010 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.010 0.010 <string>:1(<module>)
1287 0.002 0.000 0.002 0.000 cbook.py:475(iterable)
1287 0.003 0.000 0.004 0.000 cbook.py:484(is_string_like)
1287 0.002 0.000 0.009 0.000 cbook.py:565(is_scalar_or_string)
2179/892 0.001 0.000 0.010 0.000 cbook.py:605(flatten)
1287 0.001 0.000 0.001 0.000 core.py:5641(isMaskedArray)
2574 0.001 0.000 0.001 0.000 {isinstance}
1287 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*132
run("list(flatten(l))")
14919 function calls (13203 primitive calls) in 0.013 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.013 0.013 <string>:1(<module>)
1716 0.002 0.000 0.002 0.000 cbook.py:475(iterable)
1716 0.004 0.000 0.006 0.000 cbook.py:484(is_string_like)
1716 0.003 0.000 0.011 0.000 cbook.py:565(is_scalar_or_string)
2905/1189 0.002 0.000 0.013 0.000 cbook.py:605(flatten)
1716 0.001 0.000 0.001 0.000 core.py:5641(isMaskedArray)
3432 0.001 0.000 0.001 0.000 {isinstance}
1716 0.001 0.000 0.001 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler'
<强>更新 这给了我另一个想法:
l=[[1,2,3],[4,5,6], [7], [8,9]]*33
run("flattenlist(l)")
564 function calls (432 primitive calls) in 0.000 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
133/1 0.000 0.000 0.000 0.000 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
429 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*66
run("flattenlist(l)")
1125 function calls (861 primitive calls) in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
265/1 0.001 0.000 0.001 0.001 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
858 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*99
run("flattenlist(l)")
1686 function calls (1290 primitive calls) in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
397/1 0.001 0.000 0.001 0.001 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
1287 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*132
run("flattenlist(l)")
2247 function calls (1719 primitive calls) in 0.002 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
529/1 0.001 0.000 0.002 0.002 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.002 0.002 <string>:1(<module>)
1716 0.001 0.000 0.001 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*1320
run("flattenlist(l)")
22443 function calls (17163 primitive calls) in 0.016 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
5281/1 0.011 0.000 0.016 0.016 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.016 0.016 <string>:1(<module>)
17160 0.005 0.000 0.005 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
因此,为了测试递归变深的效果:更深入了多少?
l=[[1,2,3],[4,5,6], [7], [8,9]]*1320
new=[l]*33
run("flattenlist(new)")
740589 function calls (566316 primitive calls) in 0.418 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
174274/1 0.281 0.000 0.417 0.417 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.001 0.001 0.418 0.418 <string>:1(<module>)
566313 0.136 0.000 0.136 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*66
run("flattenlist(new)")
1481175 function calls (1132629 primitive calls) in 0.809 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
348547/1 0.542 0.000 0.807 0.807 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.002 0.002 0.809 0.809 <string>:1(<module>)
1132626 0.266 0.000 0.266 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*99
run("flattenlist(new)")
2221761 function calls (1698942 primitive calls) in 1.211 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
522820/1 0.815 0.000 1.208 1.208 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.002 0.002 1.211 1.211 <string>:1(<module>)
1698939 0.393 0.000 0.393 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*132
run("flattenlist(new)")
2962347 function calls (2265255 primitive calls) in 1.630 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
697093/1 1.091 0.000 1.627 1.627 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.003 0.003 1.630 1.630 <string>:1(<module>)
2265252 0.536 0.000 0.536 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*1320
run("flattenlist(new)")
29623443 function calls (22652523 primitive calls) in 16.103 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
6970921/1 10.842 0.000 16.069 16.069 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.034 0.034 16.103 16.103 <string>:1(<module>)
22652520 5.227 0.000 5.227 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
我打赌“flattenlist”我将使用这个而不是matploblib很长一段时间,除非我想要一个yield yield和快速结果,因为“flatten”在matploblib.cbook中使用
这很快。
- 以下是代码
typ=(list,tuple)
def flattenlist(d):
thelist = []
for x in d:
if not isinstance(x,typ):
thelist += [x]
else:
thelist += flattenlist(x)
return thelist
答案 11 :(得分:3)
这个版本是一个生成器。如果你想要一个列表,那就去吧。
def list_or_tuple(l):
return isinstance(l,(list,tuple))
## predicate will select the container to be flattened
## write your own as required
## this one flattens every list/tuple
def flatten(seq,predicate=list_or_tuple):
## recursive generator
for i in seq:
if predicate(seq):
for j in flatten(i):
yield j
else:
yield i
如果想要展平符合条件的谓词
,可以添加谓词取自python cookbook
答案 12 :(得分:3)
根据我的经验,压缩列表列表的最有效方法是:
flat_list = []
map(flat_list.extend, list_of_list)
与其他提议的方法进行一些时间比较:
list_of_list = [range(10)]*1000
%timeit flat_list=[]; map(flat_list.extend, list_of_list)
#10000 loops, best of 3: 119 µs per loop
%timeit flat_list=list(itertools.chain.from_iterable(list_of_list))
#1000 loops, best of 3: 210 µs per loop
%timeit flat_list=[i for sublist in list_of_list for i in sublist]
#1000 loops, best of 3: 525 µs per loop
%timeit flat_list=reduce(list.__add__,list_of_list)
#100 loops, best of 3: 18.1 ms per loop
现在,处理更长的子列表时效率提升似乎更好:
list_of_list = [range(1000)]*10
%timeit flat_list=[]; map(flat_list.extend, list_of_list)
#10000 loops, best of 3: 60.7 µs per loop
%timeit flat_list=list(itertools.chain.from_iterable(list_of_list))
#10000 loops, best of 3: 176 µs per loop
此方法也适用于任何迭代对象:
class SquaredRange(object):
def __init__(self, n):
self.range = range(n)
def __iter__(self):
for i in self.range:
yield i**2
list_of_list = [SquaredRange(5)]*3
flat_list = []
map(flat_list.extend, list_of_list)
print flat_list
#[0, 1, 4, 9, 16, 0, 1, 4, 9, 16, 0, 1, 4, 9, 16]
答案 13 :(得分:3)
以下是使用collectons.Iterable的多个级别列表的版本:
import collections
def flatten(o, flatten_condition=lambda i: isinstance(i,
collections.Iterable) and not isinstance(i, str)):
result = []
for i in o:
if flatten_condition(i):
result.extend(flatten(i, flatten_condition))
else:
result.append(i)
return result
答案 14 :(得分:2)
如果您正在寻找内置的,简单的单线程,您可以使用:
a = [[1, 2, 3], [4, 5, 6]
b = [i[x] for i in a for x in range(len(i))]
print b
返回
[1, 2, 3, 4, 5, 6]
答案 15 :(得分:2)
如果你必须使用不可迭代的元素或深度超过2的扁平化更复杂的列表,你可以使用以下函数:
def flat_list(list_to_flat):
if not isinstance(list_to_flat, list):
yield list_to_flat
else:
for item in list_to_flat:
yield from flat_list(item)
它将返回一个生成器对象,您可以将其转换为具有list()函数的列表。请注意,yield from语法从python3.3开始可用,但您可以使用显式迭代
例如:
>>> a = [1, [2, 3], [1, [2, 3, [1, [2, 3]]]]]
>>> print(list(flat_list(a)))
[1, 2, 3, 1, 2, 3, 1, 2, 3]
答案 16 :(得分:2)
def is_iterable(item):
return isinstance(item, list) or isinstance(item, tuple)
def flatten(items):
for i in items:
if is_iterable(item):
for m in flatten(i):
yield m
else:
yield i
测试:
print list(flatten2([1.0, 2, 'a', (4,), ((6,), (8,)), (((8,),(9,)), ((12,),(10)))]))
答案 17 :(得分:2)
pylab提供了一个展平: link to numpy flatten
答案 18 :(得分:2)
怎么样:
from operator import add
reduce(add, map(lambda x: list(x.image_set.all()), [mi for mi in list_of_menuitems]))
但是,Guido建议不要在一行代码中执行太多操作,因为它会降低可读性。通过在单行和多行中执行您想要的操作,可以获得最小的性能提升。
答案 19 :(得分:1)
如果列表中的每个项目都是一个字符串(并且这些字符串中的任何字符串都使用&#34;&#34;而不是&#39;&#39;),则可以使用正则表达式({{1} }模块)
re上面的代码将in_list转换为字符串,使用正则表达式查找引号中的所有子字符串(即列表中的每个项目)并将它们作为列表吐出。
答案 20 :(得分:1)
一个简单的替代方法是使用numpy's concatenate但它将内容转换为float:
import numpy as np
print np.concatenate([[1,2],[3],[5,89],[],[6]])
# array([ 1., 2., 3., 5., 89., 6.])
print list(np.concatenate([[1,2],[3],[5,89],[],[6]]))
# [ 1., 2., 3., 5., 89., 6.]
答案 21 :(得分:1)
在Python 2或3中实现此目的的最简单方法是使用pip install morph使用morph库。
代码是:
import morph
list = [[1,2],[3],[5,89],[],[6]]
flattened_list = morph.flatten(list) # returns [1, 2, 3, 5, 89, 6]
答案 22 :(得分:0)
在Python 3.4中你可以做到:
[*innerlist for innerlist in outer_list]
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?