在sklearn机器学习工具链中找到最佳算法组合
在sklearn中,可以创建一个管道来优化机器学习设置的完整工具链,如以下示例所示:
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
from sklearn.decomposition import PCA
estimators = [('reduce_dim', PCA()), ('svm', SVC())]
clf = Pipeline(estimators)
现在,管道根据定义表示一个串行进程。但是,如果我想在管道的同一级别上比较不同的算法呢?假设我想尝试另外的PCA和另一种机器学习算法(如SVM之外的树)的另一种特征转换算法,并获得4种可能组合中的最佳组合?这可以用某种并行管道来表示,还是在sklearn中有一个元算法?
2 个答案:
答案 0 :(得分:2)
管道不是并行过程。它相当顺序(管道行) - 请参阅here文档,提及:
按顺序应用变换列表和最终估算器。 [...]管道的目的是组装几个步骤,可以在设置不同参数的同时进行交叉验证。
因此,您只需更改一个参数即可创建两个管道。然后,您将能够比较结果并保持更好。如果您愿意,让我们说,比较更多的估算工具,您可以自动化流程
这是一个简单的例子:
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression
from sklearn.decomposition import PCA
clf1 = SVC(Kernel = 'rbf')
clf2 = RandomForestClassifier()
feat_selec1 = SelectKBest(f_regression)
feat_selec2 = PCA()
for selec in [('SelectKBest', feat_selec1), ('PCA', feat_select2)]:
for clf in [('SVC', clf1), ('RandomForest', clf2):
pipe = Pipeline([selec, clf])
//Do your training / testing cross_validation
答案 1 :(得分:1)
管道是连续的:
url = 'https://www.googleapis.com/gmail/v1/users/me/messages/send?uploadType=multipart'
headers = {
'Authorization': 'Bearer ' + accessToken,
'Content-Type': 'message/rfc822'
}
requests.post(url, headers=headers, payload=message)
平行的东西,我也认为你所寻找的东西被称为" Ensemble"。例如,在分类上下文中,您可以训练多个SVM,但具有不同的功能:
Data -> Process input with algorithm A -> Process input with algorithm B -> ...
在这个小例子中,3个分类器中有2个投票给了1级,第3个投票给了0级。因此,通过多数投票,整体将数据分类为1级。(这里,分类器是并行执行的)
当然,你可以在一个整体中有几个管道。
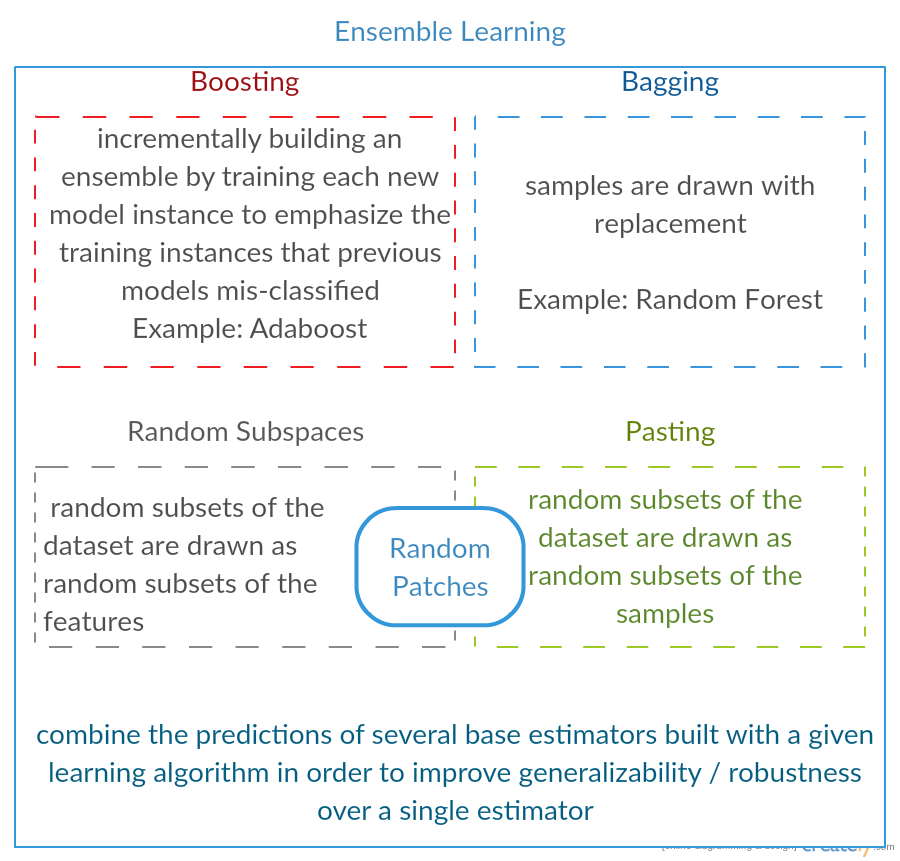
请参阅sklearns Ensemble methods以获得相当不错的摘要。
我刚才为不同的合奏方法做了一个简短的图像摘要:
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?