是否可以从Python中的HDF5文件中的复合数据集中读取字段名称?
我有一个HDF5文件,其中包含一个带有列名的2D表。当我掠夺这个名为results的对象时,它会在HDFView中显示出来。
事实证明results是一个"复合数据集",一个一维数组,其中每个元素都是一行。以下是HDFView显示的属性:
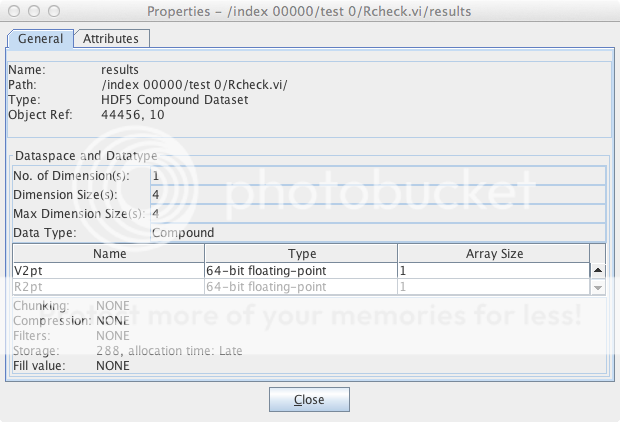
我可以处理这个对象,让我们称之为res。
列名称为V2pt,R2pt等。
我可以将整个数组作为数据读取,我可以用
读取一个元素res[0,...,"V2pt"].
这将返回列V2pt第一行中的数字。用0替换1将返回第二行值等
如果我知道colunm名称是先验,那就是。但我不是。
我只是希望获得整个数据集和的列名。我怎么能这样做?
我发现HDF5文档中的HDF5 documentation中有一个get_field_info函数,但我在h5py中找不到这样的函数。
我搞砸了吗?
更好的解决方案是将此表作为pandas DataFrame读取......
1 个答案:
答案 0 :(得分:11)
这在h5py中很容易实现,就像Numpy中的复合类型一样。
如果res是数据集的句柄,res.dtype.fields.keys()将返回a
所有字段名称的列表。
如果您需要了解具体的dtype,res.dtype.fields['V2pt']之类的内容会提供。{/ p>
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?