正则表达式匹配转义撇号
$str = "'ei-1395529080',0,0,1,1,'Name','email@domain.com','Sentence with \'escaped apostrophes\', which \'should\' be on one line!','no','','','yes','6.50',NULL";
preg_match_all("/(')?(.*?)(?(1)(?!\\\\)'),/s", $str.',', $values);
print_r($values);
我试图用这些目标写一个正则表达式:
- 返回
,个分隔值的数组(注意我在第2行附加$str) - 如果数组项以
'开头,则与结束'匹配
- 但是,如果它像
\'一样被转义,请继续捕获该值,直到找到'之前没有找到\
如果你尝试这些行,它会遇到\',
任何人都可以解释发生了什么以及如何解决它?感谢。
2 个答案:
答案 0 :(得分:3)
这就是我要解决的问题:
('(?>\\.|.)*?'|[^\,]+)
说明:
( Start capture group
' Match an apostrophe
(?> Atomically match the following
\\. Match \ literally and then any single character
|. Or match just any single character
) Close atomic group
*?' Match previous group 0 or more times until the first '
|[^\,] OR match any character that is not a comma (,)
+ Match the previous regex [^\,] one or more times
) Close capture group
关于原子团如何运作的说明:
说我有这个字符串'a \' b'
原子组(?>\\.|.)将在每个步骤按以下方式匹配此字符串:
-
' -
a -
-
\' -
-
b -
'
如果以后匹配失败,不会尝试将\'与\,'匹配,但始终匹配/使用第一个选项是否合适。
如果你需要帮助逃避正则表达式,这里是转义版本:('(?>\\\\.|.)*?'|[^\\,]+)
虽然我昨天花了大约10个小时写了正则表达式,但我对它并不太熟悉。我研究过逃避反斜杠但是被我读到的东西搞糊涂了。你原来的答案没有逃脱的原因是什么?它取决于不同的语言/平台吗? 〜OP
关于为什么必须在编程语言中使用正则表达式的部分。
当您编写以下字符串时:
"This is on one line.\nThis is on another line."
您的程序将按字面解释\n,并按以下方式查看:
"This is on one line.
This is on another line."
在正则表达式中,这可能会导致问题。假设您想要匹配所有不是换行符的字符。这就是你要这样做的方式:
"[^\n]*"
但是,\n在用编程语言编写时会按字面解释,并且可以通过以下方式看到:
"[^
]*"
我确信你可以说,这是错的。所以为了解决这个问题,我们转义字符串。通过在第一个反斜杠前放置一个反斜杠,可以告诉编程语言以不同的方式查看\n(或任何其他转义序列:\r,\t,\\,等等)。在基本级别上,转义原始转义序列\n以换取另一个转义序列,然后转换为字符\\,n。这就是转义如何影响上面的正则表达式。
"[^\\n]*"
编程语言将看到以下内容:
"[^\n]*"
这是因为\\是一个转义序列,意思是“当你看到\\将其字面解释为\时”。由于\\已被使用和解释,因此要读取的下一个字符为n,因此不再是转义序列的一部分。
那么为什么我的转义版本中有4个反斜杠?我们来看看:
(?>\\.|.)
所以这是我们写的原始正则表达式。我们有两个连续的反斜杠。正则表达式的此部分(\\.)表示“每当您看到反斜杠,然后是任何字符,匹配”。为了保留正则表达式引擎的这种解释,我们必须逃避每个单独的反斜杠。
\\ \\ .
所以这一切看起来像这样:
(?>\\\\.|.)
答案 1 :(得分:2)
这样的事情:
(?:'([^'\\]*(?:\\.[^'\\]*)*)'|([^,]+))
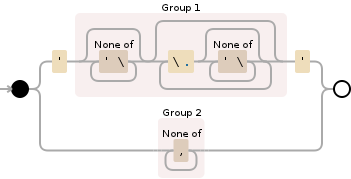
# (?:'([^'\\]*(?:\\.[^'\\]*)*)'|([^,]+))
#
# Options: Case sensitive; Exact spacing; Dot doesn’t match line breaks; ^$ don’t match at line breaks; Greedy quantifiers
#
# Match the regular expression below «(?:'([^'\\]*(?:\\.[^'\\]*)*)'|([^,]+))»
# Match this alternative (attempting the next alternative only if this one fails) «'([^'\\]*(?:\\.[^'\\]*)*)'»
# Match the character “'” literally «'»
# Match the regex below and capture its match into backreference number 1 «([^'\\]*(?:\\.[^'\\]*)*)»
# Match any single character NOT present in the list below «[^'\\]*»
# Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
# The literal character “'” «'»
# The backslash character «\\»
# Match the regular expression below «(?:\\.[^'\\]*)*»
# Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
# Match the backslash character «\\»
# Match any single character that is NOT a line break character (line feed) «.»
# Match any single character NOT present in the list below «[^'\\]*»
# Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
# The literal character “'” «'»
# The backslash character «\\»
# Match the character “'” literally «'»
# Or match this alternative (the entire group fails if this one fails to match) «([^,]+)»
# Match the regex below and capture its match into backreference number 2 «([^,]+)»
# Match any character that is NOT a “,” «[^,]+»
# Between one and unlimited times, as many times as possible, giving back as needed (greedy) «+»
https://regex101.com/r/pO0cQ0/1
preg_match_all('/(?:\'([^\'\\\\]*(?:\\\\.[^\'\\\\]*)*)\'|([^,]+))/', $subject, $result, PREG_SET_ORDER);
for ($matchi = 0; $matchi < count($result); $matchi++) {
// @todo here use $result[$matchi][1] to match quoted strings (to then process escaped quotes)
// @todo here use $result[$matchi][2] to match unquoted strings
}
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?