我想从某处获取一个字节数组(Array [Byte])(从文件中读取,从socket中读取等),然后提供一种有效的方法来从中提取位数(例如,提供一个函数来提取32数组中偏移量N的位整数)。然后我想包装字节数组(隐藏它),提供从数组中拉出位的函数(可能使用lazy val为每个位拉出)。
我认为有一个包装类在构造函数中采用不可变的字节数组类型来证明数组内容永远不会被修改。 IndexedSeq [Byte]似乎很相关,但我无法弄清楚如何从Array [Byte]转到IndexedSeq [Byte]。
问题的第2部分是,如果我使用IndexedSeq [Byte],结果代码会慢吗?我需要代码尽可能快地执行,所以如果编译器可以更好地使用它,那么就会坚持使用Array [Byte]。
我可以在数组周围编写一个包装类,但这样会减慢速度 - 每次访问数组中的字节时会有一个额外的间接级别。由于需要的阵列访问次数,性能至关重要。我需要快速代码,但希望能够很好地同时执行代码。谢谢!
PS:我是斯卡拉新手。
答案 0 :(得分:15)
将Array[T]视为IndexedSeq[T]几乎不会更简单:
Array(1: Byte): IndexedSeq[Byte] // trigger an Implicit View
wrapByteArray(Array(1: Byte)) // explicitly calling
在一个额外的间接层之前很久,取消装箱会杀了你。
C:\>scala -Xprint:erasure -e "{val a = Array(1: Byte); val b1: Byte = a(0); val
b2 = (a: IndexedSeq[Byte])(0)}"
[[syntax trees at end of erasure]]// Scala source: scalacmd5680604016099242427.s
cala
val a: Array[Byte] = scala.Array.apply((1: Byte), scala.this.Predef.
wrapByteArray(Array[Byte]{}));
val b1: Byte = a.apply(0);
val b2: Byte = scala.Byte.unbox((scala.this.Predef.wrapByteArray(a): IndexedSeq).apply(0));
为了避免这种情况,Scala集合库应该专门针对元素类型,与Tuple1和Tuple2的样式相同。我被告知这是有计划的,但它比在任何地方简单地打@specialized更为复杂,所以我不知道需要多长时间。
<强>更新
是的,WrappedArray是可变的,虽然collection.IndexedSeq[Byte]没有变异方法,所以你可以信任客户端不要强制转换为可变接口。 Scalaz的下一个版本将包括ImmutableArray,这可以防止这种情况发生。
装箱通过这种通用方法从集合中检索一个元素:
trait SeqLike[+A, +Repr] extends IterableLike[A, Repr] { self =>
def apply(idx: Int): A
}
在JVM级别,此签名被类型擦除为:
def apply(idx: Int): Object
如果您的集合包含基元,即AnyVal的子类型,则必须在相应的包装器中将它们装箱以从此方法返回。对于某些应用程序,这是一个主要的性能问题。整个库都是用Java编写的,以避免这种情况,特别是fastutils。
Annotation directed specialization被添加到Scala 2.8中,以指示编译器生成针对基本类型的排列定制的各种版本的类或方法。这已经应用于标准库中的一些地方,例如TupleN,ProductN,Function{0, 1, 2}。如果这也适用于集合层次结构,则可以降低此性能成本。
答案 1 :(得分:10)
如果您想在Scala中使用序列,我建议您选择其中一个:
不可变的seqs:
(链接的seqs)List,Stream,Queue
(索引序列)矢量
可变序列:
(链接seq)ListBuffer
(索引序列号)ArrayBuffer
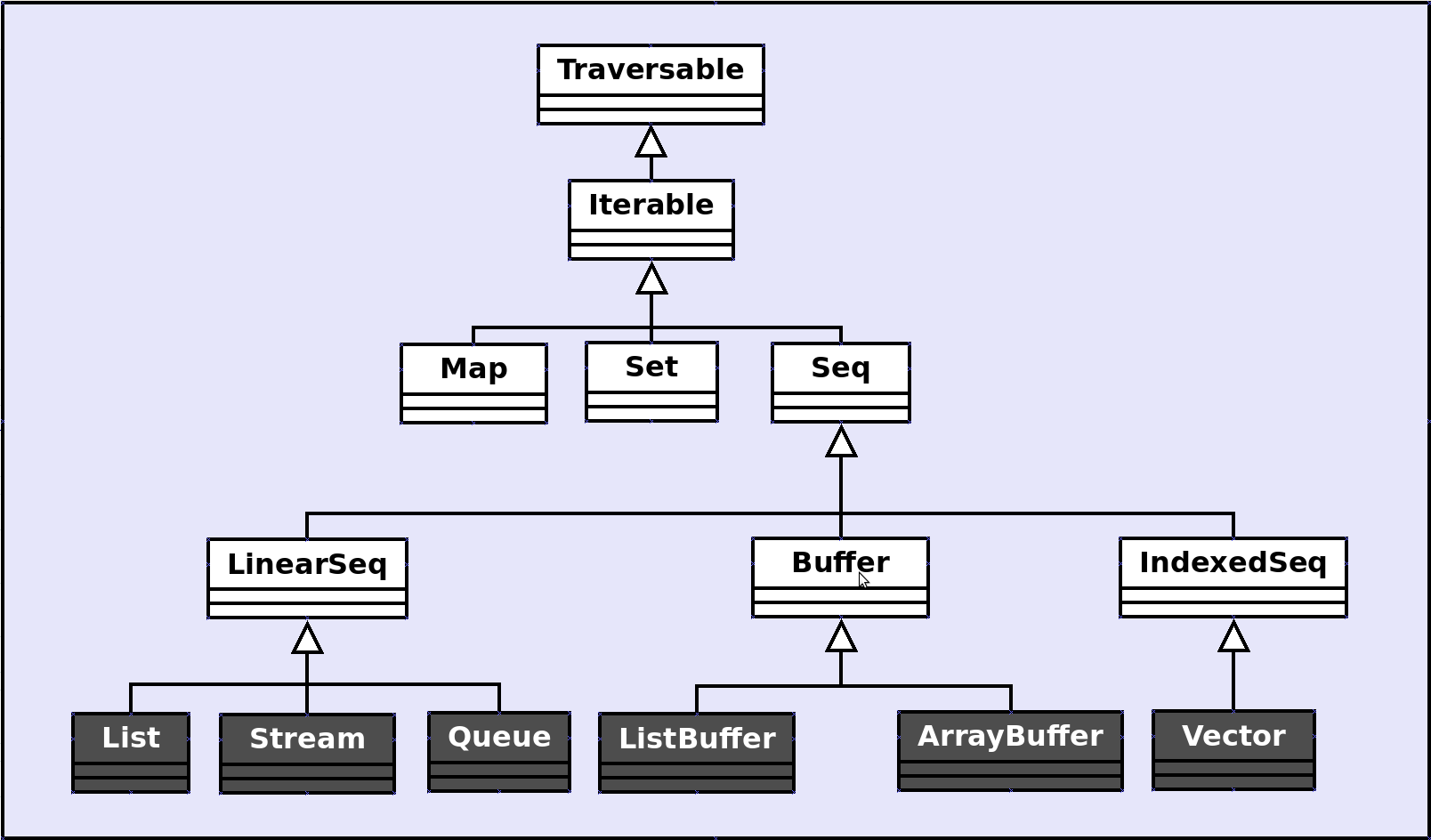
新的(2.8)Scala集合对我来说很难掌握,主要是由于(正确的)文档的不足,还因为源代码(复杂的层次结构)。为了清楚我的想法,我将这张照片想象成了基本结构:
alt text http://www.programmera.net/scala/img/seq_tree.png
另外,请注意Array不是树结构的一部分,它是一种特殊情况,因为它包装了Java数组(这是Java中的特殊情况)。
{kind=link}