我有两个不同的表有一些共同的文本,我怎么能把它拿出来
示例:
这是第一张表
column1 username
ajay|buln|khera| 110040062
ajay|shara|khera 110040082
ajay|abhay|bul 110040046
这是第二张表
column2 username
buln 110040062
buln 110040082
ajay|bhav 110040046
我希望这样做:
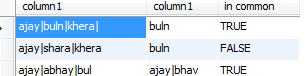
column1 column2 anything common
ajay|buln|khera| buln TRUE
ajay|shara|khera buln FALSE
ajay|abhay|bul ajay|bhav TRUE
2 个答案:
答案 0 :(得分:1)
正如在注释中所写,您的表未规范化,并且它不是在字段中连接多个值的正确方法。
但是,如果您真的需要管理列中的倍数值。我建议使用用户定义的函数。这是我的解决方案。
首先是数据库创建脚本:
create database stackAjay;
use stackAjay;
create table tableOne
(column1 varchar(50),
username INT(15) primary key);
create table tableTwo
(column1 varchar(50),
username INT(15) primary key);
insert into tableOne(column1,username)
values ('ajay|buln|khera|',110040062),('ajay|shara|khera',110040082), ('ajay|abhay|bul',110040046);
insert into tableTwo(column1,username)
values ('buln', 110040062),('buln',110040082),('ajay|bhav',110040046);
然后我们将创建三个用户定义的函数 第一个计算文本中的字符数。在这里,我们将使用它来计算" |"
DELIMITER $$
CREATE DEFINER=`root`@`localhost` FUNCTION `countCharInString`(myString text, myChar char) RETURNS int(11)
BEGIN
RETURN (select length(myString)-length(replace(myString,myChar,'')));
END
第二个UDF将用于使用分隔符作为数组管理文本。
DELIMITER $$
CREATE DEFINER=`root`@`localhost` FUNCTION `SPLIT_STR`(
x VARCHAR(255),
delim VARCHAR(12),
pos INT
) RETURNS varchar(255) CHARSET utf8
RETURN REPLACE(SUBSTRING(SUBSTRING_INDEX(x, delim, pos),
LENGTH(SUBSTRING_INDEX(x, delim, pos -1)) + 1),
delim, '')
最后,第三个UDF将比较你的" text"的每个单元格。数组,如果两个文本数组中至少有一个单词,则返回true。
DELIMITER $$
CREATE DEFINER=`rroot`@`localhost` FUNCTION `hasSomethingInCommom`(text1 text, text2 text) RETURNS varchar(5) CHARSET latin1
BEGIN
Declare amountOfWordText1 int;
Declare amountOfWordText2 int;
Declare currentWord1 int;
Declare currentWord2 int;
Set amountOfWordText1=countCharInString(text1,'|')+1;
Set amountOfWordText2=countCharInString(text2,'|')+1;
Set currentWord1=1;
Set currentWord2=1;
while (currentWord1<=amountOfWordText1) do
Set currentWord2=1;
while (currentWord2<=amountOfWordText2) do
if (SPLIT_STR(text1,'|',currentWord1)=SPLIT_STR(text2,'|',currentWord2)) Then
RETURN 'TRUE';
END IF;
Set currentWord2=currentWord2+1;
END WHILE;
Set currentWord1=currentWord1+1;
END WHILE;
RETURN 'FALSE';
END
最后比较你可以做的两个表的列。
select tableOne.column1, tableTwo.column1,hasSomethingInCommom(tableOne.column1, tableTwo.column1) as `in common`
from tableOne
left outer join tabletwo
ON tableOne.username=tableTwo.username
如前所述,通过良好的数据库设计来管理它会更容易。
答案 1 :(得分:0)
好的,,,我会试一试,但这只是一个猜测。
Select Table1.Column1
, Table2.Column2
, Case when Table2.Column1 like '%Table2.Column1%'
Then 'TRUE'
Else 'FALSE'
End Case
From Table1
Left Outer
Join Table2
On Table2.username = Table1.username
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?