以下是我实施的就地快速排序算法,来自this视频的改编:
def partition(arr, start, size):
if (size < 2):
return
index = int(math.floor(random.random()*size))
L = start
U = start+size-1
pivot = arr[start+index]
while (L < U):
while arr[L] < pivot:
L = L + 1
while arr[U] > pivot:
U = U - 1
temp = arr[L]
arr[L] = arr[U]
arr[U] = temp
partition(arr, start, L-start)
partition(arr, L+1, size-(L-start)-1)
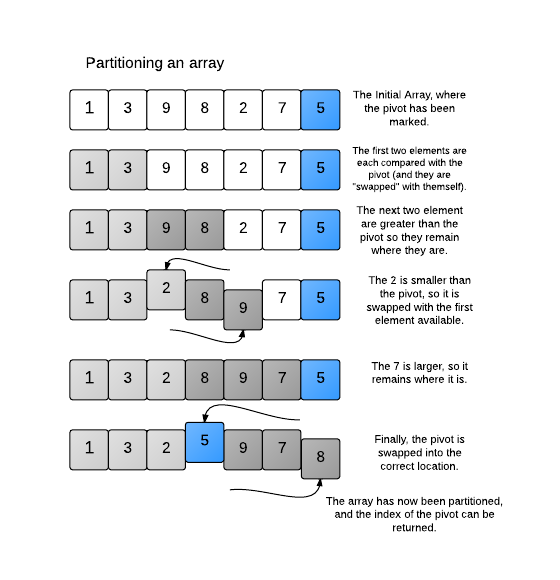
似乎有一些扫描步骤的实现,其中阵列(或阵列的当前部分)被分成3个段:低于枢轴,枢轴和大于枢轴的元素的元素。我从左边扫描大于或等于枢轴的元素,从右边扫描小于或等于枢轴的元素。一旦找到其中一个,就进行交换,循环继续,直到左标记等于或大于右标记。但是,在this图表后面还有另一种方法可以在很多情况下减少分区步骤。有人可以验证哪种方法对快速排序算法实际上更有效吗?
答案 0 :(得分:1)
您使用的两种方法基本相同。在上面的代码中
new-session索引是随机选择的,因此它可以是第一个元素或最后一个元素。在链接https://s3.amazonaws.com/hr-challenge-images/quick-sort/QuickSortInPlace.png中,他们首先将最后一个元素作为数据透视,并以与在代码中相同的方式移动。
所以两种方法都是一样的。在您的代码中,您可以随机选择数据透视图,在图像中 - 您可以说明数据透视表。
{kind=link}