返回每个可能的正则表达式结果,而不仅仅是第一个
我有一个看起来像这样的正则表达式:
/^(.*?)( tom.*)?$/
我在字符串
上执行它call tomorrow
我的匹配组将是
1. `call`
2. ` tomorrow`
但是,请注意,因为第二个匹配组是可选的,所以第一个通配符可以使用整个字符串,并且匹配仍然有效。如果您通过删除问号使第一个通配符贪婪,就会发生这种情况。
1. `call tomorrow`
所以我的问题是:有没有办法指示正则表达式引擎我希望所有有效匹配字符串,而不仅仅是第一个(基于懒惰/贪婪)?我承认这可能很慢,但对我的情况来说这是必要的。
为了澄清,我想解析字符串call tomorrow并让它返回:
MATCH 1
1. `call`
2. ` tomorrow`
MATCH 2
1. `call tomorrow`
当Regex引擎遇到(.*?)时,它将消耗0个字符,然后尝试其余的字符串。当失败时,它会尝试1个字符,然后是2个,然后是3个,然后是4.当它击中4个字符时,(call)正则表达式会解析到最后,然后退出。我想要一种说法再次解析的方法,但是从那个消耗5个字符的通配符开始,然后是6,然后是7 ......"最终,它将尝试消耗13个字符(call tomorrow),这将还允许正则表达式的其余部分解析完成,并返回该结果。
请注意,这不是关于/g/标志的问题 - 匹配的索引没有变化。
如果无法做到这一点,Regex是否适用于此应用程序?我该怎么用呢?
2 个答案:
答案 0 :(得分:0)
我认为你可以用一个抽象的捕获组来做这个,用另一个组包装所有这些,如下所示:
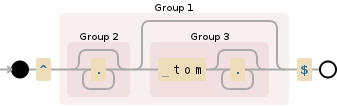
^((.*?)( tom.*)?)$
<强> Working demo
我知道这不是您想要的确切输出,但您可以拥有此匹配内容:
MATCH 1
1. [0-13] `call tomorrow`
2. [0-4] `call`
3. [4-13] ` tomorrow`
以更好的图形方式,它将是:
作为旁注,我注意到你明天之前有空白也许你也喜欢这个正则表达式:
^((.*?) (tom.*)?)$
答案 1 :(得分:0)
在这个简单的示例中,添加另一个捕获组,但您需要处理重复项。
> re = /^((.*?)( tom.*)?)$/
> console.log('call tomorrow'.match(re))
["call tomorrow", "call tomorrow", "call", " tomorrow", index: 0, input: "call tomorrow"]
对于更复杂的情况,您需要自己编写一个循环。这些答案有一些好主意:
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?