µê浡úÕ£¿õ¢┐þö¿ÕñºÕ×ïþƒ®ÚÿÁ´╝ê100x100Õê░3000x3000´╝ëÞ┐øÞíîõ©Çõ║øÞ«íþ«ù´╝êÕ¥êÕñܵÇ╗ÕÆîÕÆî120µ¼íþƒ®ÚÿÁÕÉæÚçÅõ╣ÿµ│ò´╝ë´╝îµê浡úÕ£¿õ¢┐þö¿þë╣Õ¥üÕ║ôµØÑÕñäþÉåµêæþÜäÕÉæÚçÅÕÆîþƒ®ÚÿÁÒÇé
µêæµâ│þƒÑÚüôÕªéõ¢òÕèáÚǃµêæþÜäÞ«íÕêÆÒÇéµêæÕ║öÞ»Ñþ╗ºþ╗¡õ¢┐þö¿Eigen´╝îõ¢┐þö¿1dµò░þ╗ä´╝îõ¢┐þö¿std :: vector´╝îÞ┐ÿµÿ»õ¢┐þö¿ÕàÂõ╗ûÕ║ô´╝ƒ
þ¡öµíê 0 :(Õ¥ùÕêå´╝Ü4)
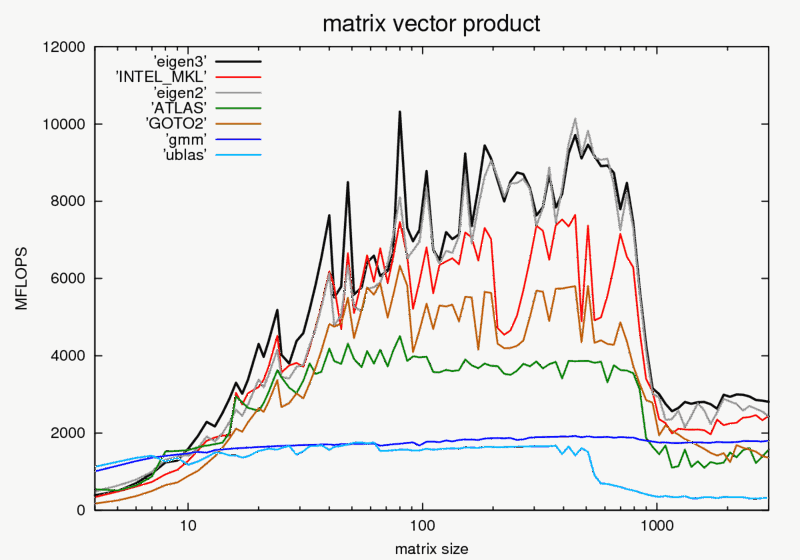
ÕüçÞ«¥µé¿õ©ìµâ│Þ┐üþº╗Õê░GPU´╝îÕ╣Âõ©öÕªéµ×£µé¿µâ│Þªüõ┐íõ╗╗EigenþÜäbenchkmarkÚíÁÚØó´╝îÚéúõ╣êEigenÚØ×Õ©©Õ┐½ÒÇéµé¿þë╣Õê½µÅÉÕê░matrix vector products´╝îÕ£¿µé¿µîçÕ«ÜþÜäÞîâÕø┤Õåà´╝îEigenõ¢ìõ║ÄÚíÂÚâ¿ÒÇéþí«õ┐ØÕÉ»þö¿OpenMP´╝îÕøáõ©║EigenÕ░åÕê®þö¿multiple coresÒÇéõ©Ävectorizationõ©ÇµáÀÒÇé
þ¡öµíê 1 :(Õ¥ùÕêå´╝Ü2)
µêæÕüÜõ║åõ©Çµ¼íµ»öÞ¥â´╝îµ»öÞ¥âõ║åEigenÕÆîViennaCL´╝êõ©ñÞÇàÚâ¢Õ£¿Þ░âÞ»òõ©¡´╝ë´╝Ü
Processing Unit | Mat Size | Exec time | Calc | Sparse %
CPU 10 0,000 dense_mat*mat
GPU 10 0,010 dense_mat*mat
CPU 100 0,103 dense_mat*mat
GPU 100 0,001 dense_mat*mat
CPU 1000 97,232 dense_mat*mat
GPU 1000 0,072 dense_mat*mat
CPU 10 0,000 sparse_mat*mat 0,25
GPU 10 0,007 sparse_mat*mat 0,25
CPU 10 0,000 sparse_mat*mat 0,5
GPU 10 0,000 sparse_mat*mat 0,5
CPU 10 0,000 sparse_mat*mat 1
GPU 10 0,000 sparse_mat*mat 1
CPU 100 0,010 sparse_mat*mat 0,25
GPU 100 0,001 sparse_mat*mat 0,25
CPU 100 0,030 sparse_mat*mat 0,5
GPU 100 0,001 sparse_mat*mat 0,5
CPU 100 0,106 sparse_mat*mat 1
GPU 100 0,001 sparse_mat*mat 1
CPU 1000 7,131 sparse_mat*mat 0,25
GPU 1000 0,073 sparse_mat*mat 0,25
CPU 1000 26,628 sparse_mat*mat 0,5
GPU 1000 0,072 sparse_mat*mat 0,5
CPU 1000 101,389 sparse_mat*mat 1
GPU 1000 0,072 sparse_mat*mat 1
õ¢┐þö¿þÜäõ╗úþáüµÿ»´╝Ü
//disable debug mechanisms to have a fair comparison with ublas:
#ifndef NDEBUG
#define NDEBUG
#endif
//
// include necessary system headers
//
#include <iostream>
#include <fstream>
//
// ublas includes
//
#include <boost/numeric/ublas/io.hpp>
#include <boost/numeric/ublas/triangular.hpp>
#include <boost/numeric/ublas/matrix_sparse.hpp>
#include <boost/numeric/ublas/matrix.hpp>
#include <boost/numeric/ublas/matrix_proxy.hpp>
#include <boost/numeric/ublas/lu.hpp>
#include <boost/numeric/ublas/io.hpp>
#define EIGEN_YES_I_KNOW_SPARSE_MODULE_IS_NOT_STABLE_YET
//
// Eigen includes
//
#include <Eigen/Core>
#include <Eigen/Dense>
// Must be set if you want to use ViennaCL algorithms on ublas objects
#define VIENNACL_WITH_UBLAS 1
//
// IMPORTANT: Must be set prior to any ViennaCL includes if you want to use ViennaCL algorithms on Eigen objects
//
#define VIENNACL_WITH_EIGEN 1
//
// IMPORTANT: Must be set prior to any ViennaCL includes if you want to use ViennaCL algorithms using OPENCL
//
#ifndef VIENNACL_WITH_OPENCL
#define VIENNACL_WITH_OPENCL
#endif
//
// ViennaCL includes
//
#include "viennacl/scalar.hpp"
#include "viennacl/vector.hpp"
#include "viennacl/matrix.hpp"
#include "viennacl/linalg/prod.hpp"
#include "viennacl/compressed_matrix.hpp"
#include "viennacl/linalg/sparse_matrix_operations.hpp"
#include "viennacl/linalg/ilu.hpp"
#include "viennacl/linalg/detail/ilu/block_ilu.hpp"
#include "viennacl/linalg/direct_solve.hpp"
#include "viennacl/linalg/bicgstab.hpp"
// Some helper functions for this tutorial:
#include "examples/tutorial/Random.hpp"
#include "examples/tutorial/vector-io.hpp"
#include "examples/benchmarks/benchmark-utils.hpp"
#define BLAS3_MATRIX_SIZE 700
using namespace boost::numeric;
#ifndef VIENNACL_WITH_OPENCL
struct dummy
{
std::size_t size() const { return 1; }
};
#endif
int main()
{
typedef float ScalarType;
Timer timer;
double exec_time;
//
// Initialize OpenCL device in the context
//
std::cout << std::endl << "--- initialized OpenGL device using ViennaCL ---" << std::endl;
#ifdef VIENNACL_WITH_OPENCL
std::vector<viennacl::ocl::device> devices = viennacl::ocl::current_context().devices();
#else
dummy devices;
#endif
#ifdef VIENNACL_WITH_OPENCL
viennacl::ocl::current_context().switch_device(devices[0]);
std::cout << " - Device Name: " << viennacl::ocl::current_device().name() << std::endl;
#endif
//// Output results file
std::ofstream resultsFile;
resultsFile.open("resultsFile.txt");
resultsFile << "Processing Unit,Mat Size,Exec time" << std::endl;
std::cout << "Processing Unit,Mat Size,Exec time" << std::endl;
// Start defining the dense matrices
size_t points = 230000;
size_t transRows=4;
size_t transCols=3;
// Other alternative: Use Eigen
Eigen::MatrixXf eigen_A(points, transRows);
Eigen::MatrixXf eigen_B(transRows, transCols);
// One alternative: Put the matrices into a contiguous block of memory (allows to use viennacl::fast_copy(), avoiding temporary memory)
std::vector<ScalarType> stl_A(points * transRows);
std::vector<ScalarType> stl_B(transRows * transCols);
// Set up the ViennaCL object
viennacl::matrix<ScalarType> vcl_A(points, transRows);
viennacl::matrix<ScalarType> vcl_B(transRows, transCols);
// Fill dense matrix in normal memory
for (unsigned int i = 0; i < points; ++i)
{
for (unsigned int j = 0; j < transRows; ++j)
{
stl_A[i*transRows + j] = random<ScalarType>();
eigen_A(i,j) = stl_A[i*transRows + j];
}
}
for (unsigned int i = 0; i < transRows; ++i)
{
for (unsigned int j = 0; j < transCols; ++j)
{
stl_B[i*transCols + j] = random<ScalarType>();
eigen_B(i,j) = stl_A[i*transCols + j];
}
}
// Perform the matrix*matrix product
// On CPU
Eigen::MatrixXf eigen_C(points, transCols);
timer.start();
eigen_C = eigen_A * eigen_B;
exec_time = timer.get();
resultsFile << "CPU," << points << "," << exec_time << std::endl;
std::cout << "CPU," << points << "," << exec_time << std::endl;
// on GPU
timer.start();
// Copy to gpu memory
// Using fastcopy I can get ~500x speed improvement
viennacl::fast_copy(&(stl_A[0]),&(stl_A[0]) + stl_A.size(),vcl_A);
viennacl::fast_copy(&(stl_B[0]),&(stl_B[0]) + stl_B.size(),vcl_B);
viennacl::matrix<ScalarType> vcl_C(points, transCols);
vcl_C = viennacl::linalg::prod(vcl_A, vcl_B);
viennacl::backend::finish();
exec_time = timer.get();
resultsFile << "GPU," << points << "," << exec_time << std::endl;
std::cout << "GPU," << points << "," << exec_time << std::endl;
//// Start defining the dense matrices
//for(size_t denseSize=10; denseSize<=1000; denseSize=denseSize*10)
//{
// // Other alternative: Use Eigen
// Eigen::MatrixXf eigen_A(denseSize, denseSize);
// // One alternative: Put the matrices into a contiguous block of memory (allows to use viennacl::fast_copy(), avoiding temporary memory)
// std::vector<ScalarType> stl_A(denseSize * denseSize);
// // Set up the ViennaCL object
// viennacl::matrix<ScalarType> vcl_A(denseSize, denseSize);
// // Fill dense matrix in normal memory
// for (unsigned int i = 0; i < denseSize; ++i)
// {
// for (unsigned int j = 0; j < denseSize; ++j)
// {
// stl_A[i*denseSize + j] = random<ScalarType>();
// eigen_A(i,j) = stl_A[i*denseSize + j];
// }
// }
// // Perform the matrix*matrix product
// // On CPU
// Eigen::MatrixXf eigen_C(denseSize, denseSize);
// timer.start();
// eigen_C = eigen_A * eigen_A;
// exec_time = timer.get();
// resultsFile << "CPU," << denseSize << "," << exec_time << std::endl;
// std::cout << "CPU," << denseSize << "," << exec_time << std::endl;
// // on GPU
// timer.start();
// // Copy to gpu memory
// // Using fastcopy I can get ~500x speed improvement
// viennacl::fast_copy(&(stl_A[0]),&(stl_A[0]) + stl_A.size(),vcl_A);
// viennacl::matrix<ScalarType> vcl_C(denseSize, denseSize);
// vcl_C = viennacl::linalg::prod(vcl_A, vcl_A);
// viennacl::backend::finish();
// exec_time = timer.get();
// resultsFile << "GPU," << denseSize << "," << exec_time << std::endl;
// std::cout << "GPU," << denseSize << "," << exec_time << std::endl;
//}
//// Start defining the sparse matrices
//for(size_t sparseSize=10; sparseSize<=1000; sparseSize=sparseSize*10)
//{
// for(float sparsePerc=0.25; sparsePerc<=1.0; sparsePerc=2*sparsePerc)
// {
// // Other alternative: Use Eigen
// Eigen::SparseMatrix<float> eigen_A(sparseSize, sparseSize);
// // One alternative: Put the matrices into a contiguous block of memory (allows to use viennacl::fast_copy(), avoiding temporary memory)
// std::vector<ScalarType> stl_A(sparseSize * sparseSize);
// // Set up the ViennaCL sparse matrix
// viennacl::matrix<ScalarType> vcl_A(sparseSize, sparseSize);
// // Fill dense matrix in normal memory
// for (size_t i=0; i<sparseSize; ++i)
// {
// for (size_t j=0; j<sparseSize; ++j)
// {
// if (((rand()%100)/100.0) <= sparsePerc)
// {
// stl_A[i*sparseSize + j] = float(rand());
// eigen_A.insert(i,j) = stl_A[i*sparseSize + j];
// }
// }
// }
// // Perform the matrix*matrix product
// // On CPU
// Eigen::SparseMatrix<float> eigen_C(sparseSize, sparseSize);
// timer.start();
// eigen_C = (eigen_A * eigen_A).pruned();
// exec_time = timer.get();
// resultsFile << "CPU," << sparseSize << "," << sparsePerc << "," << exec_time << std::endl;
// std::cout << "CPU," << sparseSize << "," << sparsePerc << "," << exec_time << std::endl;
// // on GPU
// timer.start();
// // Copy to gpu memory
// // Using fastcopy I can get ~500x speed improvement
// viennacl::fast_copy(&(stl_A[0]),&(stl_A[0]) + stl_A.size(),vcl_A);
// viennacl::matrix<ScalarType> vcl_C(sparseSize, sparseSize);
// vcl_C = viennacl::linalg::prod(vcl_A, vcl_A);
// viennacl::backend::finish();
// exec_time = timer.get();
// resultsFile << "GPU," << sparseSize << "," << sparsePerc << "," << exec_time << std::endl;
// std::cout << "GPU," << sparseSize << "," << sparsePerc << "," << exec_time << std::endl;
// }
//}
resultsFile.close();
//
// That's it.
//
std::cout << "Press [ENTER] to exit " << std::endl;
std::cin.get();
return EXIT_SUCCESS;
}
{kind=link}