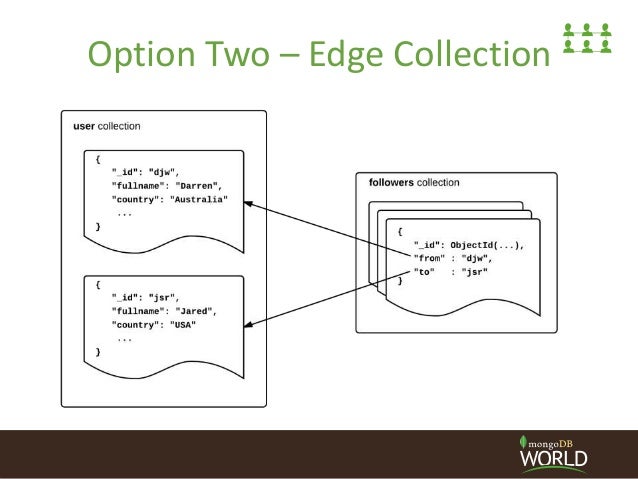
жҲ‘е·Із»ҸдёәдәҶдёӢйқўзҡ„дҫӢеӯҗиҖҢеҶҷдәҶз”ЁжҲ·пјҢдҝұд№җйғЁе’ҢзІүдёқгҖӮ жҲ‘жғіжүҫеҲ°жқҘиҮӘд»ҘдёӢпјҶпјғ34;зқҖеҗҚдҝұд№җйғЁпјҶпјғ34;зҡ„з”ЁжҲ·йӣҶеҗҲдёӯзҡ„жүҖжңүз”ЁжҲ·ж–ҮжЎЈгҖӮ жҲ‘жҖҺж ·жүҚиғҪжүҫеҲ°иҝҷдәӣпјҹе“Әз§Қж–№ејҸжңҖеҝ«пјҹ
жңүе…іпјҶпјғ39; what do I want to do - Edge collectionsпјҶпјғ39;зҡ„жӣҙеӨҡдҝЎжҒҜ
з”ЁжҲ·йӣҶеҗҲ
{
"_id": "1",
"fullname": "Jared",
"country": "USA"
}
дҝұд№җйғЁзі»еҲ—
{
"_id": "12",
"name": "A famous club"
}
зІүдёқ收и—Ҹ
{
"_id": "159",
"user_id": "1",
"club_id": "12"
}
PSпјҡжҲ‘еҸҜд»ҘеғҸдёӢйқўиҝҷж ·дҪҝз”ЁMongooseиҺ·еҸ–ж–Ү件гҖӮдҪҶжҳҜпјҢдҪҝз”Ё150.000жқЎи®°еҪ•еҲӣе»әfollowersж•°з»„еӨ§зәҰйңҖиҰҒ8з§’гҖӮ第дәҢдёӘfindжҹҘиҜў - дҪҝз”Ёе…іжіЁиҖ…ж•°з»„жҹҘиҜў - йңҖиҰҒзәҰ40з§’гҖӮиҝҷжҳҜжӯЈеёёзҡ„еҗ—пјҹ
Clubs.find(
{ club_id: "12" },
'-_id user_id', // select only one field to better perf.
function(err, docs){
var followers = [];
docs.forEach(function(item){
followers.push(item.user_id)
})
Users.find(
{ _id:{ $in: followers } },
function(error, users) {
console.log(users) // RESULTS
})
})
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ0)
жІЎжңүз¬ҰеҗҲжқЎд»¶зҡ„е…¬ејҸжқҘж“ҚзәөMongoDBдёҠзҡ„еӨҡеҜ№еӨҡе…ізі»гҖӮжүҖд»ҘжҲ‘е°ҶйӣҶеҗҲеҗҲ并дёәеөҢе…ҘејҸж–ҮжЎЈпјҢеҰӮдёӢжүҖзӨәгҖӮдҪҶеңЁиҝҷз§Қжғ…еҶөдёӢпјҢжңҖйҮҚиҰҒзҡ„жҳҜеҲӣе»әзҙўеј•гҖӮдҫӢеҰӮпјҢеҰӮжһңжӮЁжғіжҢүfollowingClubsиҝӣиЎҢжҹҘиҜўпјҢеҲҷеә”дҪҝз”ЁMongooseеҲӣе»әзұ»дјјschema.index({ 'followingClubs._id':1 })зҡ„зҙўеј•гҖӮеҰӮжһңжӮЁжғіжҹҘиҜўcountryе’ҢfollowingClubsпјҢеҲҷеә”еҲӣе»әеҸҰдёҖдёӘзҙўеј•пјҢдҫӢеҰӮschema.index({ 'country':1, 'followingClubs._id':1 })
дҪҝз”ЁеөҢе…ҘејҸж–ҮжЎЈж—¶иҜ·жіЁж„Ҹпјҡhttp://askasya.com/post/largeembeddedarrays
然еҗҺдҪ е°ұеҸҜд»Ҙеҝ«йҖҹеҫ—еҲ°дҪ зҡ„ж–Ү件гҖӮжҲ‘иҜ•еӣҫз”Ёиҝҷз§Қж–№ејҸи®Ўз®—150.000дёӘи®°еҪ•пјҢеҸӘиҠұдәҶ1з§’й’ҹгҖӮиҝҷеҜ№жҲ‘жқҘиҜҙе·Із»Ҹи¶іеӨҹ......
psпјҡжҲ‘们дёҚиҰҒеҝҳи®°еңЁжҲ‘зҡ„жөӢиҜ•дёӯпјҢжҲ‘зҡ„UsersйӣҶеҗҲд»ҺжңӘз»ҸеҺҶиҝҮд»»дҪ•ж•°жҚ®зўҺзүҮгҖӮеӣ жӯӨжҲ‘зҡ„жҹҘиҜўеҸҜиғҪиЎЁзҺ°еҮәиүҜеҘҪзҡ„иЎЁзҺ°зү№еҲ«жҳҜfollowingClubsеөҢе…Ҙж–ҮжЎЈж•°з»„гҖӮ
з”ЁжҲ·йӣҶеҗҲ
{
"_id": "1",
"fullname": "Jared",
"country": "USA",
"followingClubs": [ {"_id": "12"} ]
}
дҝұд№җйғЁзі»еҲ—
{
"_id": "12",
"name": "A famous club"
}
{kind=link}