д»ҠеӨ©пјҢжҲ‘йңҖиҰҒи®ҫи®ЎдёҖдёӘе®һдҪ“пјҢиҜҘе®һдҪ“жҢҒжңүеҜ№е®ғзҡ„иҒҡеҗҲж №зҡ„еј•з”ЁгҖӮдёәдәҶзЎ®дҝқе®һдҪ“зҡ„е®һдҫӢеј•з”ЁдёҺе…¶еҢ…еҗ«зҡ„иҒҡеҗҲж №зӣёеҗҢзҡ„иҒҡеҗҲж №пјҢжҲ‘еҒҡдәҶдёҖдәӣйҷҗеҲ¶пјҢеҸӘжңүиҒҡеҗҲж №жүҚиғҪеҲӣе»әе®һдҪ“гҖӮ
public class Aggregate {
public int Id { get; }
public IEnumerable<Entities> Entities { get; }
public Entity CreateEntity(params);
}
public class Entity {
public int Id { get; }
public Aggregate Parent { get; }
}
зӘҒ然й—ҙпјҢдёҖдёӘе…ідәҺиҒҡеҗҲзҡ„дёҖдёӘйқһеёёйҮҚиҰҒзҡ„жҰӮеҝөжү“еҮ»дәҶжҲ‘пјҡиҒҡеҗҲзү©дёҚдјҡзҘһеҘҮең°еҮәзҺ°гҖӮжІЎжңүпјҶпјғ39; new AggregateпјҲidпјү;пјҶпјғ39;еңЁDDDдё–з•ҢгҖӮ
жүҖд»ҘпјҢзҺ°еңЁжҲ‘й—®......и°ҒиҙҹиҙЈеҲӣе»әе®ғ们пјҹжҲ‘зҹҘйҒ“жңүе·ҘеҺӮзӯүпјҢдҪҶиҖғиҷ‘еҲ°иҒҡеҗҲзҡ„иә«д»ҪеҸҜиғҪжҳҜж•°жҚ®еә“дә§з”ҹзҡ„д»ЈзҗҶпјҢеӯҳеӮЁеә“иҙҹиҙЈиҒҡеҗҲеҲӣе»әжҳҜеҗҰеҗҲзҗҶе‘ўпјҹ
public class MyAggregate {
public int Id { get; private set; }
protected MyAggregate() {}
public MyAggregate(int id) {
Id = id;
}
}
public interface IMyAggregateRepository {
MyAggregate Create();
void DeleteById(int id);
void Update(MyAggregate aggregate);
MyAggregate GetById(int id);
// no Add() method on this layer!
}
private class EfMyAggregateRepository : IAggregateRepository {
public EfMyAggregateRepository(DbContext context) {
...
}
public MyAggregate Create() {
var pto = context.Create<MyAggregate>();
context.Set<MyAggregate>().Attach(pto);
return pto;
}
}
иҝҷж ·пјҢж•°жҚ®еә“пјҲжҲ–дҫӢеҰӮEFпјүе°ұеҸҜд»ҘиҮӘеҠЁз”ҹжҲҗеҜҶй’ҘпјҢд№ҹеҸҜд»ҘеңЁеӯҳеӮЁеә“дёӯе®ҡд№үйӘҢиҜҒ规еҲҷпјҢеҰӮжһңжӯЈеңЁдҝ®ж”№пјҲе’Ңжӣҙж–°пјүзӯүе®һдҪ“д№ҹйҖӮз”ЁгҖӮ
жҲ–иҖ…жҲ‘зҺ°еңЁж··еңЁдёҖиө·еҗ—пјҹиҝҷжӣҙеғҸжҳҜжңҚеҠЎ/е·ҘеҺӮзҡ„д»»еҠЎеҗ—пјҹ
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ7)
еӯҳеӮЁеә“еҸӘжҳҜжҠҪиұЎжҢҒд№…жҖ§пјҢеҪ“е®ғжҒўеӨҚпјҲд№ҹи®ёпјҢеӯҳеӮЁжң¬иә«еҸҜд»ҘжҒўеӨҚпјүиҒҡеҗҲж №ж—¶пјҢе®ғдёҚдјҡеҲӣе»әе®ғгҖӮеӯҳеӮЁеә“зҡ„зӣ®зҡ„дёҚжҳҜеҲӣе»әеҜ№иұЎгҖӮ
е·ҘеҺӮзҡ„зӣ®зҡ„жҳҜеҲӣе»әеҜ№иұЎпјҢдҪҶжҳҜеҪ“еҲӣе»әдёҚз®ҖеҚ•ж—¶дҪҝз”Ёе·ҘеҺӮпјҲеҰӮж–°зҡ„myobjectпјҲпјүпјү并且е®ғеҸ–еҶідәҺжҹҗдәӣ规еҲҷжҲ–иҖ…жӮЁдёҚзҹҘйҒ“иҰҒжұӮе“Әз§Қе…·дҪ“зұ»еһӢпјҲжҠҪиұЎе·ҘеҺӮпјүгҖӮ
е…ідәҺиҒҡеҗҲж №еҝ…йЎ»жқҘиҮӘжҹҗдёӘең°ж–№пјҢжҲ‘дёҚеҗҢж„ҸгҖӮ他们дёҚеҝ…йЎ»пјҢдҪҶд»ҺиҜӯд№үзҡ„и§’еәҰжқҘзңӢе®ғжҳҜжңүж„Ҹд№үзҡ„гҖӮжҲ‘дёҖзӣҙеҒҡвҖңж–°зҡ„MyAggregateпјҲidпјүвҖқпјҢиҝҷдёҚжҳҜй—®йўҳпјҢжІЎжңүеҝ…иҰҒж №жҚ®дёҖдәӣжӯҰж–ӯзҡ„规еҲҷејәиҝ«дәӢжғ…пјҢеҸӘеӣ дёәжңүдәәиҝҷд№ҲиҜҙгҖӮеҰӮжһңдҪ жңүе……еҲҶзҡ„зҗҶз”ұпјҲи®ҫи®ЎпјҢжҠҖжңҜпјүпјҢйӮЈе°ұеҺ»еҒҡеҗ§гҖӮеҰӮжһңжІЎжңүпјҢиҜ·дёҚиҰҒдҪҝдҪ зҡ„з”ҹжҙ»еӨҚжқӮеҢ–гҖӮ
зӯ”жЎҲ 1 :(еҫ—еҲҶпјҡ0)
еңЁе®һйҷ…еә”з”ЁдёӯпјҢдёҚйңҖиҰҒжҳҫејҸAggregateе®һзҺ°гҖӮ AggregateжҳҜдёҺentitiesз»‘е®ҡзҡ„зӣёе…іaggregation relationзҡ„йӣҶеҗҲпјҢе…¶дёӯдёҖдёӘдё»entityеҗҚдёәAggregate Root гҖӮ
жӮЁеҸӘйңҖзЎ®е®ҡentities aggregate rootsжҳҜд»Җд№ҲпјҢ然еҗҺдҪҝз”Ёaggregate root encapsulation and other rulesи®ҫи®ЎжӮЁзҡ„зұ»е’ҢиҒҡеҗҲи®ҫеӨҮгҖӮ
иҖғиҷ‘еҲ°иҝҷдёҖзӮ№пјҢжҲ‘е»әи®®йҒөеҫӘжҺҘеҸЈе’Ңзұ»
interface IAggregateRoot<TKey>
{
TKey Key { get; }
}
//entity which is aggregate root
class Car : IAggregateRoot<int>
{
int Key { get; }
Ienumerable<Door> Doors { get; }
}
//other entity, not aggregate root
class Door
{
string Colour { get; set; }
}
//generic interface with IAggregateRoot constraint
interface IRepository<TAggregateRoot, TKey> where TAggregateRoot : IAggregateRoot
{
TAggregateRoot Get(TKey key)
//other methods
}
factoriesе’ҢrepositoriesжҠҖжңҜдёҠйғҪдјҡеҲӣе»әaggregate rootsзҡ„е®һдҫӢе’Ңе…¶д»–жңүз•ҢиҒҡеҗҲentitiesзҡ„е®һдҫӢгҖӮдёӨиҖ…йғҪжһ„йҖ aggregateдҪҶе…·жңүдёҚеҗҢзҡ„иҜӯд№үгҖӮ
<ејә>еӯҳеӮЁеә“
Repositoryд»ҺжҢҒд№…еӯҳеӮЁдёӯжҒўеӨҚaggregateпјҲиҖғиҷ‘еӯҳеӮЁжЁЎеһӢпјү并еҒҮи®ҫиҒҡеҗҲеӨ„дәҺдёҖиҮҙзҠ¶жҖҒпјҢеҚідёҚиҝқеҸҚиҒҡеҗҲдёҚеҸҳйҮҸгҖӮ
еҰӮжһңеӯҳеңЁдёҚеҸҳиҝқ规пјҢеҲҷRepositoryеҝ…йЎ»жү§иЎҢжҹҗдәӣж“ҚдҪңпјҢеӣ дёәе·ІеҲӣе»әзҡ„иҒҡеҗҲдёҚдёҖиҮҙпјҲпјҹпјҒпјүгҖӮ
<ејә>е·ҘеҺӮ
FactoryжӣҙеғҸжҳҜе»әзӯ‘еёҲгҖӮе®ғжһ„йҖ aggregateпјҢдәҶи§Је®ғзҡ„дёҚеҸҳйҮҸгҖӮеңЁaggregateжһ„йҖ жңҹй—ҙaggregateеҸҜиғҪеӨ„дәҺдёҚдёҖиҮҙзҠ¶жҖҒпјҢдҪҶйҡҸзқҖaggregateжһ„йҖ иҝҮзЁӢзҡ„е®ҢжҲҗпјҢе®ғеҝ…йЎ»е°ҠйҮҚдёҚеҸҳйҮҸ并дҝқжҠӨе®ғ们гҖӮ
еҰӮжһңз”ұдәҺжҹҗдәӣеҺҹеӣ еҜјиҮҙдёҚеҸҳиҝқ规factoryж— жі•жһ„е»әaggregate并е°Ҷе…¶еҲ йҷӨгҖӮ
жңүж—¶еӯҳеӮЁеә“дҪҝз”Ёе·ҘеҺӮжқҘеҲӣе»әе®һдҫӢпјҢдҪҶеңЁеӨ§еӨҡж•°жғ…еҶөдёӢпјҢжҲ‘и®ӨдёәжңҖеҘҪе°Ҷе®ғ们е®Ңе…ЁеҲҶејҖгҖӮ
е·ҘеҺӮеҰӮдҪ•иҝҗдҪңзҡ„дёҖдёӘдҫӢеӯҗгҖӮ
еҒҮи®ҫCarзұ»зҡ„дёҚеҸҳйҮҸжҳҜ'CarеҸӘиғҪжңү2й—ЁжҲ–4й—Ё'гҖӮ
public interface ICar : IAggregateRoot<int>
{
int Key { get; }
IEnumerable<IDoor> Doors { get; }
SetDoors(IEnumerable<IDoor> doors);
}
public class Car : ICar
{
//take a look here, it's internal
internal IList<IDoor> Doors { get; set;}
public int Key { get; set; }
public IEnumerable<IDoor> Doors { get { return Doors; } }
//aggregate root always controls aggregate invariants
public SetDoors(IEnumerable<IDoor> doors)
{
if (doors.Count() != 2 || doors.Count() != 4)
throw new ApplicationException();
Doors = doors.ToList();
}
}
interface IDoor { }
class Door : IDoor { }
//generic interface with IAggregateRoot constraint
interface ICarFactory
{
ICar CreateCar(int doorsCount)
}
public class CarFactory : ICarFactory
{
public ICar CreateCar(int doorsCount)
{
if (doorsCount != 2 && doorsCount != 4)
throw new ApplicationException();
var car = new Car();
car.Key = 1;
car.Doors = new List<IDoor>();
car.Doors.Add(new Door());
//now car is inconsistent as it holds just one door
car.Doors.Add(new Door());
//now car is consistent
return car;
}
}
иҝҷжҳҜдёҖдёӘдәәдёәзҡ„дҫӢеӯҗпјҢдҪҶжңүж—¶еҖҷиҒҡеҗҲдёҚеҸҳйҮҸеӨӘеӨҚжқӮдәҶпјҢж— жі•еңЁжһ„йҖ иҝҮзЁӢдёӯе§Ӣз»Ҳж»Ўи¶іе®ғ们гҖӮ
зҺ°еңЁеҒҮи®ҫFactoryе’ҢAggregate Rootе…·жңүеҜҶеҲҮиҝһжҺҘпјҢеӣ дёәFactoryзҹҘйҒ“CarеҶ…йғЁеӯ—ж®өгҖӮ
жңҖеҗҺпјҢжҲ‘и®ӨдёәдҪ иҜҜи§ЈдәҶдёҖдәӣжҰӮеҝө并е»әи®®дҪ йҳ…иҜ»Evans DDDд№ҰгҖӮ
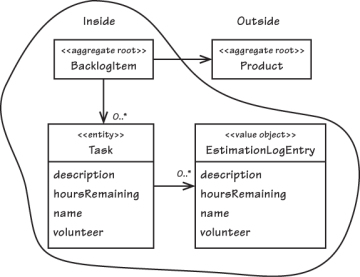
зј–иҫ‘пјҡеҸҜиғҪжҲ‘й”ҷиҝҮдәҶMyAggregateе®һйҷ…дёҠжҳҜMyAggregateRootзҡ„дәӢе®һгҖӮдҪҶеҜ№жҲ‘жқҘиҜҙпјҢж··еҗҲиҝҷдәӣжҰӮеҝөеҫҲеҘҮжҖӘгҖӮжӯӨеӨ–пјҢеңЁSOдёҠжңүдёҖдёӘй—®йўҳпјҢжҳҫејҸдәәе·ҘиҒҡеҗҲзұ»еҢ…еҗ«жүҖжңүиҒҡеҗҲеҶ…йғЁеҸӘжҳҜдёәдәҶжҳҫзӨәиҒҡеҗҲиҫ№з•ҢгҖӮжҲ‘жӣҙе–ңж¬ўеҸҜжҺҘеҸ—зҡ„AggregateRootжҰӮеҝөпјҢе°ұеғҸжҲ‘и§ҒиҝҮhttp://ptgmedia.pearsoncmg.com/images/chap10_9780321834577/elementLinks/10fig05.jpg
зҡ„еӨ§еӨҡж•°еӣҫиЎЁдёҖж ·зӯ”жЎҲ 2 :(еҫ—еҲҶпјҡ0)
В ВпјҶпјғ34;зӘҒ然й—ҙпјҢе…ідәҺиҒҡеҗҲзҡ„дёҖдёӘйқһеёёйҮҚиҰҒзҡ„жҰӮеҝөжү“еҮ»дәҶжҲ‘пјҡ В В иҒҡеҗҲзү©дёҚдјҡзҘһеҘҮең°еҮәзҺ°еңЁе…¶дёӯгҖӮпјҶпјғ34;
жӮЁеҝ…йЎ»жҳҺзҷҪпјҢйҖҡеёёдёҚдјҡзӣҙжҺҘе°ҶnewиҒҡеҗҲзӣҙжҺҘж·»еҠ еҲ°жӣҙеҜҶеҲҮе…іжіЁжіӣеңЁиҜӯиЁҖпјҲULпјүгҖӮ
дҫӢеҰӮпјҢдёҡеҠЎдё“家еҸҜиғҪдјҡиҜҙпјҶпјғ34;зҪ‘з«ҷи®ҝй—®иҖ…еә”иҜҘиғҪеӨҹжіЁеҶҢжҲҗдёәе®ўжҲ·пјҶпјғ34; иҖҢдёҚжҳҜnew Customer(visitorId, ...)жӮЁеҸҜиғҪдјҡжңүзұ»дјјCustomer customer = visitor.register(...)зҡ„еҶ…е®№{1}}гҖӮ
дҪҝз”ЁзәҜжҠҖжңҜе·ҘеҺӮ并дёҚиғҪеё®еҠ©и§ЈеҶіиҝҷдёӘй—®йўҳпјҢеӣ дёәиҝҷдәӣе·ҘдҪңдёҚжҳҜULзҡ„дёҖйғЁеҲҶпјҢеҸҜд»Ҙе®һзҺ°дёҖдёӘйқһеёёдёҚеҗҢзҡ„зӣ®ж ҮпјҢдҫӢеҰӮд»Һе®ўжҲ·зҡ„и§’еәҰз®ҖеҢ–еҲӣе»әиҝҮзЁӢжҲ–иҖ…и§ЈиҖҰе®ўжҲ·з«ҜжқҘиҮӘе…·дҪ“е®һж–ҪгҖӮ
В ВпјҶпјғ34;жІЎжңүпјҶпјғ39; new AggregateпјҲidпјү;пјҶпјғ39;еңЁDDDдё–з•ҢгҖӮпјҶпјғ34;
е®һйҷ…дёҠж №жң¬дёҚжҳҜзңҹзҡ„гҖӮеҰӮжһңжІЎжңүеҗҲжі•зҡ„еҹҹжҰӮеҝөеҸҜд»ҘеҲӣе»әиҒҡеҗҲпјҲеҚідҪҝжңүпјүпјҢзӣҙжҺҘnewиҒҡеҗҲе°ұеҸҜд»ҘдәҶгҖӮ
д»…д»…дёәдәҶйҒҝе…ҚnewиҖҢеј•е…ҘдёҖдёӘдёҚйңҖиҰҒзҡ„жҠҖжңҜе·ҘеҺӮеҸӘдјҡдҪҝи®ҫи®ЎеӨҚжқӮеҢ–гҖӮ
В ВпјҶпјғ34;иҖғиҷ‘еҲ°иҒҡеҗҲзҡ„иә«д»ҪеҸҜиғҪжҳҜд»ЈзҗҶдәә В В з”ұж•°жҚ®еә“з”ҹжҲҗпјҢиҝҷдёҚеҸҜиғҪжҳҜеҗҲзҗҶзҡ„ В В еӯҳеӮЁеә“иҙҹиҙЈиҒҡеҗҲеҲӣе»әпјҹпјҶпјғ34;
еӯҳеӮЁеә“зҡ„е·ҘдҪңжҳҜжҠҪиұЎеҮәжҢҒд№…жҖ§з»ҶиҠӮд»ҘеҸҠдёәиҒҡеҗҲжЈҖзҙўе®ҡд№үжҳҺзЎ®зҡ„еҗҲеҗҢпјҢиҖҢдёҚжҳҜеҲӣе»әиҒҡеҗҲгҖӮжҳҫ然пјҢз”ұдәҺиҒҡеҗҲеҝ…йЎ»д»ҺжҹҘиҜўиҝ”еӣһпјҢеӣ жӯӨе®ғ们зҡ„е®һдҫӢеҢ–еҝ…йЎ»еҸ‘з”ҹеңЁй“ҫдёӯзҡ„жҹҗдёӘең°ж–№пјҢдҪҶе®ғеҫҲеҸҜиғҪ被委жүҳз»ҷ其他组件пјҢдҫӢеҰӮе·ҘеҺӮпјҢORMзӯүгҖӮ
еҰӮжһңжӮЁйңҖиҰҒж•°жҚ®еә“з”ҹжҲҗзҡ„ж ҮиҜҶпјҢеҲҷеҸҜд»ҘеңЁеӯҳеӮЁеә“дёӯж”ҫзҪ®дёҖдёӘиҝ”еӣһжӯӨзұ»ж ҮиҜҶзҡ„ж“ҚдҪңгҖӮдҫӢеҰӮпјҢжӮЁеҸҜиғҪеңЁеӯҳеӮЁеә“дёҠжңүдёҖдёӘpublic int nextIdentity()ж–№жі•пјҢе®ғиҝ”еӣһж•°жҚ®еә“еәҸеҲ—зҡ„дёӢдёҖдёӘеҖјгҖӮ
йҒөеҫӘжҺҘеҸЈйҡ”зҰ»еҺҹеҲҷпјҲISPпјүпјҢжӮЁеҸҜд»ҘеҶіе®ҡдёәиҜҘд»»еҠЎеҲӣе»әдё“з”ЁжҺҘеҸЈпјҢдҫӢеҰӮCustomerIdentityGeneratorгҖӮ
{kind=link}