将字符串拆分为给定长度的子字符串,其余为余数
给出如下字符串:
text <- "abcdefghijklmnopqrstuvwxyz"
我想将字符串剪切成子字符串,例如长度为10,并保留余数:
"abcdefghij"
"klmnopqrst"
"uvwxyz"
我知道创建子串的所有方法都不会给我6个字符的余数子串。我尝试过以前类似问题的答案,例如:
> substring(text, seq(1, nchar(text), 10), seq(10, nchar(text), 10))
[1] "abcdefghij" "klmnopqrst" ""
关于如何获得所需长度和任何剩余字符串的所有子串的任何建议都将非常感激。
3 个答案:
答案 0 :(得分:10)
尝试
strsplit(text, '(?<=.{10})', perl=TRUE)[[1]]
#[1] "abcdefghij" "klmnopqrst" "uvwxyz"
或者您可以使用library(stringi)更快的方法
library(stringi)
stri_extract_all_regex(text, '.{1,10}')[[1]]
#[1] "abcdefghij" "klmnopqrst" "uvwxyz"
答案 1 :(得分:8)
用于first中last和substring参数的向量可能超过字符串中的字符数而没有错误/警告/问题。所以你可以做到
text <- "abcdefghijklmnopqrstuvwxyz"
sq <- seq.int(to = nchar(text), by = 10)
substring(text, sq, sq + 9)
# [1] "abcdefghij" "klmnopqrst" "uvwxyz"
答案 2 :(得分:3)
这是一种使用strapplyc涉及一个相当简单的正则表达式的方法。它有效,因为.{1,10}总是匹配不超过10个字符的最长字符串:
library(gsubfn)
strapplyc(text, ".{1,10}", simplify = c)
,并提供:
[1] "abcdefghij" "klmnopqrst" "uvwxyz"
可视化这个正则表达式非常简单,它实际上并不需要可视化,但这里有一个:
.{1,10}
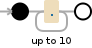
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?