如何使用Python RegEx从字符串中提取数据?
我有这种格式的文件名:
INC_2AB_22BA_1300435674_218_19-May-2014_13-09-59.121._OK
INC_2EE_22RE_1560343444_119_11-Jun-2014_15-21-32.329._OK
INC_2CD_22HY_1652323334_312_21-Jan-2014_11-15-48.291._OK
我想在日期部分之前提取名称。例如,在第一个文件中需要 _19-May-2014_13-09-59.121._确定之前的任何内容都会产生 INC_2AB_22BA_1300435674_218
我尝试了回顾方法,但此刻无法解决这个问题。
必不可少,尝试匹配此模式_[0-9]-[aA-bB]-*
6 个答案:
答案 0 :(得分:3)
如果您的格式一致,您可以使用以下内容。
>>> s = 'INC_2AB_22BA_1300435674_218_19-May-2014_13-09-59.121._OK'
>>> '_'.join(s.split('_')[0:5])
'INC_2AB_22BA_1300435674_218'
答案 1 :(得分:2)
您可以尝试以下代码,
>>> import re
>>> s = """INC_2AB_22BA_1300435674_218_19-May-2014_13-09-59.121._OK
... INC_2EE_22RE_1560343444_119_11-Jun-2014_15-21-32.329._OK
... INC_2CD_22HY_1652323334_312_21-Jan-2014_11-15-48.291._OK"""
>>> m = re.findall(r'^.*?(?=_\d{2}-[A-Z][a-z]{2}-\d{4})', s, re.M)
>>> for i in m:
... print i
...
INC_2AB_22BA_1300435674_218
INC_2EE_22RE_1560343444_119
INC_2CD_22HY_1652323334_312
答案 2 :(得分:2)
试试这个:
.*(?=_\d{1,2}-[a-zA-Z]{3})
它使用前瞻断言来表示你所在日期的_00-Aaa格式。
答案 3 :(得分:1)
看起来这些线条有标准尺寸。只需使用
offset = len('INC_2AB_22BA_1300435674_218')`
for line in input:
print line[:offset]
答案 4 :(得分:0)
由于您所需的数据位于该行的开头,因此锚点搜索非常简单:
^(.*)(?:_\d{2}-[a-zA-Z]{3}-\d{4})
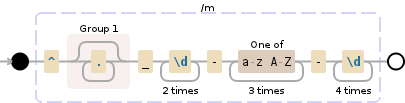
>>> import re
>>> txt='''\
... INC_2AB_22BA_1300435674_218_19-May-2014_13-09-59.121._OK
... INC_2EE_22RE_1560343444_119_11-Jun-2014_15-21-32.329._OK
... INC_2CD_22HY_1652323334_312_21-Jan-2014_11-15-48.291._OK'''
>>>
>>> re.findall(r'^(.*)(?:_\d{2}-[a-zA-Z]{3}-\d{4})', txt, re.M)
['INC_2AB_22BA_1300435674_218', 'INC_2EE_22RE_1560343444_119', 'INC_2CD_22HY_1652323334_312']
如果您想更加具体地在日期字段中匹配'Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec',您可以这样做:
>>> re.findall(r'^([^-]+)(?:_\d{2}-(?:Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)-\d{4})', txt, re.M)
...相同的输出
答案 5 :(得分:0)
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?