在多行之间包含字符的正则表达式
我有以下文字:
BEGIN:
>>DocTypeName: Zoning Letter
>>DocDate: 4/16/2014
Loan Number: 355211
Ad Hoc: ZONING VERIFICATION LETTER
Document Handle: 712826
>>DiskgroupNum: 102
>>VolumeNum: 367
>>NumOfPages: 0
>>FileSize: 261711
>>DocRevNum: 0
>>Rendition: 1
>>PhysicalPageNum: 0
>>ItemPageNum: 0
>>FileTypeNum: 16
>>ImageType: 0
>>Compress: 2
>>Xdpi: 0
>>Ydpi: 0
>>FileName: \V367\2855\1558564.PDF
BEGIN:
>>DocTypeName: Zoning Letter
>>DocDate: 4/16/2014
Loan Number: 355211
Ad Hoc: ZONING CODES COMPLIANCE LETTER
Document Handle: 712825
>>DiskgroupNum: 102
>>VolumeNum: 367
>>NumOfPages: 0
>>FileSize: 19441
>>DocRevNum: 0
>>Rendition: 1
>>PhysicalPageNum: 0
>>ItemPageNum: 0
>>FileTypeNum: 16
>>ImageType: 0
>>Compress: 2
>>Xdpi: 0
>>Ydpi: 0
>>FileName: \V367\2855\1558563.pdf
我需要使用正则表达式(将在C#程序中使用)将其转换为对CSV有效的内容。最重要的数据是来自每个部分的文档句柄和文件名(路径)(作为“BEGIN:”下的部分)我正在为其他人工作,所以我想尽可能多地保留他们认为他们需要一些其他数据的事件。这是我最初的尝试:
\r\n(?!BEGIN).*\:
但是,并非每个部分都有一个“Ad Hoc:”组件,它会在拉入Excel时抛出单元格对齐。我确切知道的Ad Hoc不是最终结果所需数据的一部分。
最好的情况是只选择并删除每个“Ad Hoc”和“Handle:”之间的所有内容,用分隔符(;)替换。然后,我会将其与上面的正则表达式一起管道。
我唯一的另一个要求是,这必须全部在一个正则表达式声明中 - 否则在我编写的程序中,我将不得不设置某种循环或业务,我还没准备做
3 个答案:
答案 0 :(得分:1)
您可以使用正则表达式,但我不会说它比在手动循环中更容易。
(?<=BEGIN:\r\n)(?:.*:\s*(?:(?<value>(?<!Ad Hoc:\s*).*)|.*)(?:\r\n)?)*?(?=BEGIN:|$)

示例代码:
foreach (Match m in Regex.Matches(text, @"(?<=BEGIN:\r\n)(?:.*:\s*(?:(?<value>(?<!Ad Hoc:\s*).*)|.*)(?:\r\n)?)*?(?=BEGIN:|$)"))
{
Console.WriteLine(string.Join(",", m.Groups["value"].Captures.Cast<Capture>().Select(c => c.Value)));
}
输出:
Zoning Letter,4/16/2014,355211,712826,102,367,0,261711,0,1,0,0,16,0,2,0,0,\V367\2855\1558564.PDF
Zoning Letter,4/16/2014,355211,712825,102,367,0,19441,0,1,0,0,16,0,2,0,0,\V367\2855\1558563.pdf
答案 1 :(得分:1)
基于我从问题下面的评论中理解的内容,问题中给出的示例数据应该转换为两个文本行,如下所示:
Zoning Letter;4/16/2014;355211;712826;102;367;0;261711;0;1;0;0;16;0;2;0;0;\V367\2855\1558564.PDF
Zoning Letter;4/16/2014;355211;712825;102;367;0;19441;0;1;0;0;16;0;2;0;0;\V367\2855\1558563.pdf
为了在避免循环的同时实现这个结果(虽然我想知道你为什么要避免循环 - 它们是基本的和全方位存在的构造),我建议应用两个(或三个,见下面的第3节)正则表达式替换
的 1。删除&#34;标签:&#34;并使用&#34;;&#34;
第一个正则表达式将删除&#34;前面的标签:&#34;包括&#34;:&#34;和任何前面的换行符分号。但是,它将不删除或替换&#34; BEGIN:&#34;前面的换行符,并且它也不会触及&#34; BEGIN:&#34;本身。
@"(([\r\n]+\s*Ad\sHoc:.*?[\r\n]+)|([\r\n]+(?!\s*BEGIN))).*?:\s*"
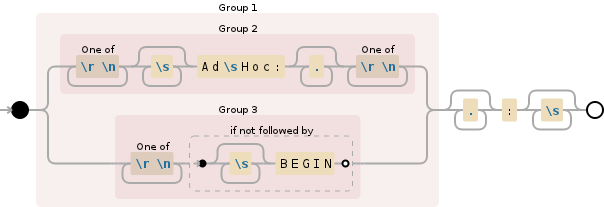
这个正则表达式是两个正则表达式的OR组合(在上面的可视化中很容易看到):
[\r\n]+\s*Ad\sHoc:.*?[\r\n]+.*?:\s*
将匹配Ad Hoc:&#34;包括任何&#34;标签的行:&#34;以下行中的字符串,
([\r\n]+(?!\s*BEGIN)).*?:\s*
将匹配任何&#34;标签:&#34;包括在它前面的换行符,除了&#34; BEGIN:&#34;标签
将此正则表达式应用于您的示例并将所有匹配项替换为&#34;;&#34;将导致以下结果:
BEGIN:;Zoning Letter;4/16/2014;355211;712826;102;367;0;261711;0;1;0;0;16;0;2;0;0;\V367\2855\1558564.PDF
BEGIN:;Zoning Letter;4/16/2014;355211;712825;102;367;0;19441;0;1;0;0;16;0;2;0;0;\V367\2855\1558563.pdf
注意&#34; BEGIN:;&#34;我们现在要照顾。
的 2。消除&#34; BEGIN:&#34;标签
在查看第一个正则表达式替换的结果时,这是一个相当简单的模式。
"(?m)^BEGIN:;"
您可能认为可以通过字符串替换来完成此操作 - 在编写我的答案的第一个版本时也是如此。但是,当&#34; BEGIN:;&#34;可以是任何其他文本字段的内容的一部分。通过指定仅在行开头匹配的正则表达式来更好地保证正确和安全。
第3。代码示例,包括消除源文本中的空行
如果源文本中包含空格的空行,则上面显示的正则表达式可能无法正常工作。解决方案是事先进行另一个正则表达式替换,这会将空行(包括空格)减少为单个换行符(如果您确定源数据不包含空行,则可以省略此步骤。)
一个完整的代码示例,它会产生我在答案开头提到的结果,可能如下所示:
string sourceData = ... your text with the source data ...
Regex reEmptyLines = new Regex(@"[\s\r\n]+[\r\n]", RegexOptions.Compiled);
Regex reSemicolons = new Regex(@"(([\r\n]+\s*Ad\sHoc:.*?[\r\n]+)|([\r\n]+(?!\s*BEGIN))).*?:\s*", RegexOptions.Compiled);
Regex reBegin = new Regex("(?m)^BEGIN:;", RegexOptions.Compiled);
string processed =
reBegin.Replace(
reSemicolons.Replace(
reEmptyLines.Replace(sourceData, "\r\n"),
";"
),
string.Empty
);
答案 2 :(得分:0)
这是怎么回事:
BEGIN:((?:(?!BEGIN:).)*)
这将匹配第一个BEGIN和下一个BEGIN之间的所有内容。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?