从字符串中提取url
我知道这个问题多次重复,但我找不到合适的答案。
如果我有一串网址,例如:
" www.google.comwww.yahoo.comwww.ebay.com" (假设链接之间没有空格)
我想单独提取每个并将它们放在数组中。我尝试使用正则表达式:
String[] sp= parts.split("\\www");
System.out.println(parts[0]);
这没有用!任何提示都表示赞赏
2 个答案:
答案 0 :(得分:2)
Regex
(www\.((?!www\.).)*)
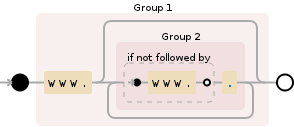
描述
选项:不区分大小写
Match the regular expression below and capture its match into backreference number 1 «(www\.((?!www\.).)*)»
Match the characters “www” literally «www»
Match the character “.” literally «\.»
Match the regular expression below and capture its match into backreference number 2 «((?!www\.).)*»
Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
Note: You repeated the capturing group itself. The group will capture only the last iteration. Put a capturing group around the repeated group to capture all iterations. «*»
Assert that it is impossible to match the regex below starting at this position (negative lookahead) «(?!www\.)»
Match the characters “www” literally «www»
Match the character “.” literally «\.»
Match any single character that is not a line break character «.»
爪哇
try {
String subjectString = "www.google.comwww.yahoo.comwww.ebay.com";
String[] splitArray = subjectString.split("(?i)(www\\.((?!www\\.).)*)");
} catch (PatternSyntaxException ex) {
// Syntax error in the regular expression
}
答案 1 :(得分:2)
你也可以使用基本的字符串方法将comwww分解为com www,然后简单地拆分空格:
String urlString = "www.google.comwww.yahoo.comwww.ebay.com";
String[] urlArray = urlString.replaceAll(".comwww.", ".com www.").split(" ");
System.out.println(Arrays.toString(urlArray)); // [www.google.com, www.yahoo.com, www.ebay.com]
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?