从字符串中提取除字括号中的单词之外的所有单词
同样,我完全陷入了创建正则表达式的过程中。
我有一个字符串模式,如:
str = ' wordA [] wordAB [xyz] wordABC [x] '
因此,括号[ ... ]或空括号[]中总会出现一个单词。单词的长度,前导和尾随空格以及括号内的字符数是随机的。随机的是这个序列重复的频率。
我想提取没有括号的单词:
output =
'wordA' 'wordBC' 'wordABC'
我认为问题是方括号,因为它们是正则表达式的功能字符。我试过像
这样的东西output = regexp(str,'^\[.+\]$','split')
并且变化没有成功。
任何提示?
1 个答案:
答案 0 :(得分:2)
我们可以使用\w+正则表达式选择所有单词。但它会选择所有单词(包括括号中的那些单词)。括号外的单词在它们之前和之后都有空格,因此我们可以添加正面的lookbehind (?<=\s) - 确保单词前面有空格,并且正向前瞻(?=\s) - 确保后面有空格字。另外,第一个单词之前没有空格,因此我们需要包含条件以包含字符串的开头,为我们提供正面的后置(?<=\s|^)。最后我们有完整的正则表达式:
(?<=\s|^)\w+(?=\s)

如果您有wordA[]字符串(无空格),则需要将[添加到正向前瞻。
(?<=\s|^)\w+(?=\s|\[)
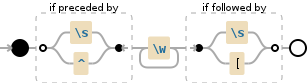
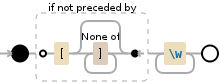
如果您有wordA [ xyz ]个字符串(括号内的空格),则上述正则表达式不起作用,我们需要不同的策略 - 找到之前没有[的字词。但是,我们不能只在没有[在他们之前]的情况下说单词,因为它与yz中的[xyz]相匹配,我们需要说我们需要的文字不是由[引导的和]以外的符号。
(?<!\[[^]]*)\w+
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?