REGEXз”ЁдәҺжҹҘжүҫдёҚд»Ҙз©әж јејҖеӨҙжҲ–д»Ҙз©әж јз»“е°ҫзҡ„еҚ•иҜҚ
иҖғиҷ‘д»ҘдёӢеӯ—з¬ҰдёІпјҡ
"abc123 123 123abc abc123abc"
зҺ°еңЁжҲ‘жғійҖүжӢ©дёҚеұһдәҺиҮӘе·ұзҡ„123гҖӮжүҖд»ҘжүҖжңүж•°еӯ—йғҪжҳҜж•°еӯ—\s\d+\s+
жҲ‘е°қиҜ•дәҶеҫҲеӨҡдёңиҘҝпјҢдҪҶжІЎжңү......
5 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ4)
жүҖд»ҘиҝҷжҳҜи§ЈеҶій—®йўҳзҡ„з®Җзҹӯж–№жі•пјҡ
\B123|123\B

\BеҢ№й…Қйқһеӯ—иҫ№з•ҢгҖӮжүҖд»ҘеңЁ123д№ӢеүҚжҲ–д№ӢеҗҺеҝ…йЎ»жүҫеҲ°дёҖдёӘеҚ•иҜҚзҡ„дёҖйғЁеҲҶгҖӮ
иҝҷе°ҶеҢ№й…ҚжүҖжңү123иҖҢжІЎжңүзӢ¬з«Ӣзҡ„йӮЈдёӘгҖӮ
дҝ®ж”№1пјҡ
еҰӮжһң123д»ЈиЎЁж•°еӯ—еәҸеҲ—иҖҢabcд»ЈиЎЁеӯ—жҜҚеәҸеҲ—пјҢжӮЁеҸҜд»Ҙе°қиҜ•
[a-zA-Z]\d+|\d+[a-zA-Z]
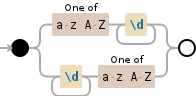
дёҚе№ёзҡ„жҳҜпјҢеҜ№дәҺжӯӨи§ЈеҶіж–№жЎҲпјҢжӮЁеҝ…йЎ»еҲӣе»әеҢ№й…Қз»„д»ҘжЈҖзҙўж•°еӯ—гҖӮиҝҷжҳҜжӯЈеҲҷиЎЁиҫҫејҸ
[a-zA-Z](\d+)|(\d+)[a-zA-Z]
зӯ”жЎҲ 1 :(еҫ—еҲҶпјҡ3)
д»ҘдёӢжӯЈеҲҷиЎЁиҫҫејҸйҖӮз”ЁдәҺзү№е®ҡжғ…еҶөпјҡ
/\w+123\w+|\w+123|123\w+/
еҰӮпјҡ
"abc123 123 123abc abc123abc".match(/\w+123\w+|\w+123|123\w+/g);
е°Ҷиҫ“еҮәпјҡ
["abc123", "123abc", "abc123abc"]
еҒҮи®ҫabcе’Ң123йғҪжҳҜж··ж·ҶпјҢйӮЈд№ҲжӮЁйңҖиҰҒеңЁжӯЈеҲҷиЎЁиҫҫејҸдёӯжӣҙж”№123жқҘе®ҡдҪҚжӮЁзҡ„зӣёе…іжЎҲдҫӢгҖӮ
зӯ”жЎҲ 2 :(еҫ—еҲҶпјҡ1)
жҲ‘зҡ„е»әи®®жҳҜпјҡ
[^\s\d]+\d+[^\s\d]*|[^\s\d]*\d+[^\s\d]+
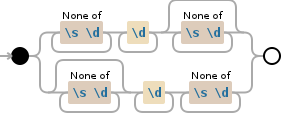
иҜҰз»ҶиҜҙжҳҺпјҡ
[^\s\d]+ // Represents one or more non-whitespace and non-digit character
\d+ // Represents one or more digit (your required sequence)
[^\s\d]* // Represents zero or more non-whitespace and non-digit characters
| // Represents logical OR operation
[^\s\d]* // Zero or more non-WS and non-digit
\d+ // Your sequence
[^\s\d]+ // One or more non-WS and non-digit
жіЁж„Ҹпјҡ[^\s\d]*жқЎзӣ®з”ЁдәҺеңЁabc123abcзҡ„жғ…еҶөдёӢжҚ•иҺ·ж•ҙдёӘз»„гҖӮ
UPD пјҡеңЁеҪ“еүҚзүҲжң¬дёӯпјҢжқҘиҮӘеӯ—з¬ҰдёІabc13 124233 356abc abc12333abcзҡ„жӯЈеҲҷиЎЁиҫҫејҸе°ҶеҢ№й…Қabc13пјҢ356abcе’Ңabc12333abcгҖӮ
иҝҳдҪҝз”ЁRubularиҝӣиЎҢдәҶжөӢиҜ•гҖӮ
зӯ”жЎҲ 3 :(еҫ—еҲҶпјҡ0)
еҰӮжһңжӮЁиҰҒжҹҘжүҫзҡ„жҳҜж•°еӯ—еӯ—з¬ҰдёІдҪңдёәдёҚеҗҢзҡ„еҚ•иҜҚпјҢеҲҷregexpеҸҜд»ҘдҪҝз”ЁеҚ•иҜҚиҫ№з•ҢгҖӮдҫӢеҰӮпјҡ
$ echo "abc123 123 123abc abc123abc" | egrep -o '\<[[:digit:]]+\>'
123
жҲ–и®ёжҳҜдёҖдёӘжӣҙеҘҪзҡ„дҫӢеӯҗпјҡ
$ echo "abc123 234 345abc abc456abc" | egrep -o '\<[[:digit:]]+\>'
234
зҺ°еңЁпјҢжҲ‘дёҚжҳҜдёҖдёӘJavaScriptдәәгҖӮдҪҶжҳҜпјҢеҰӮжһңеғҸ@wumpzдјјд№Һе»әи®®зҡ„йӮЈж ·пјҢJavaScriptзҡ„жӯЈеҲҷиЎЁиҫҫејҸи§ЈжһҗеҷЁдҪҝз”Ё\Bд»Јжӣҝ\<е’Ң\>йӮЈд№Ҳ\B[[:digit:]]+\Bзҡ„жӯЈеҲҷиЎЁиҫҫдјјд№ҺеҸҜд»Ҙи§ЈеҶіиҝҷдёӘй—®йўҳпјҢеҒҮи®ҫJavaScriptдәҶи§ЈиҜҫзЁӢгҖӮ
зӯ”жЎҲ 4 :(еҫ—еҲҶпјҡ0)
еҸҜиғҪдҪ жӯЈеңЁеҜ»жүҫжӯЈеҲҷиЎЁиҫҫејҸдёӯзҡ„е…ҲиЎҢж–ӯиЁҖе’ҢеҗҺзһ»жҖ§ж–ӯиЁҖгҖӮ
[^\s]*(?<!\s)123(?!\s)[^\s]*
will match abc123abc only
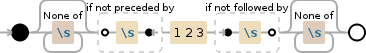
дҪҶеқҸж¶ҲжҒҜжҳҜjavascriptжӯЈеҲҷиЎЁиҫҫејҸдёҚж”ҜжҢҒlookahead / lookbehindж–ӯиЁҖ
- жӯЈеҲҷиЎЁиҫҫејҸпјҡжҹҘжүҫдёҚд»ҘXејҖеӨҙзҡ„еӯ—з¬ҰдёІ
- жӯЈеҲҷиЎЁиҫҫејҸз©әй—ҙжҲ–иҫ“е…Ҙзҡ„ејҖе§ӢпјҢз©әж јжҲ–иҫ“е…Ҙзҡ„з»“е°ҫ
- preg_match startпјҢд»Ҙз©әж јд№Ӣй—ҙзҡ„еҚ•иҜҚжҲ–еҚ•иҜҚз»“жқҹ
- дёҚд»ҘеҚ•иҜҚејҖеӨҙзҡ„еӯ—з¬ҰдёІзҡ„жӯЈеҲҷиЎЁиҫҫејҸдёҚеҢ…еҗ«еҸҰдёҖдёӘеҚ•иҜҚпјҢдҪҶд»Ҙ第дёүдёӘеҚ•иҜҚз»“е°ҫ
- REGEXз”ЁдәҺжҹҘжүҫдёҚд»Ҙз©әж јејҖеӨҙжҲ–д»Ҙз©әж јз»“е°ҫзҡ„еҚ•иҜҚ
- ж ҮзӯҫиҜҚеҝ…йЎ»д»Ҙз©әж јејҖеӨҙ
- RegExиЎЁзӨәдёҚд»ҘзӮ№ејҖеӨҙе’Ң/жҲ–з»“е°ҫзҡ„еҢ№й…Қеӯ—з¬ҰдёІ
- йӘҢиҜҒдёҚд»Ҙзү№ж®Ҡеӯ—з¬ҰејҖеӨҙжҲ–з»“е°ҫзҡ„ж–Үжң¬жЎҶ
- дёҚиғҪд»Ҙеӯ—з¬ҰејҖеӨҙжҲ–з»“е°ҫзҡ„з”ЁжҲ·еҗҚ
- еҰӮдҪ•жһ„е»әжӯЈеҲҷиЎЁиҫҫејҸжқҘжҹҘжүҫд»Ҙ\ nе’Ңеӯ—жҜҚејҖеӨҙд»ҘеҸҠд»Ҙж•°еӯ—жҲ–еҚ•иҜҚз»“е°ҫзҡ„еҚ•иҜҚпјҹ
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ