LinkedHashMap的内部实现与HashMap实现有何不同?
我读到HashMap具有以下实现:
main array
↓
[Entry] → Entry → Entry ← linked-list implementation
[Entry]
[Entry] → Entry
[Entry]
[null ]
因此,它有一个Entry对象数组。
问题:
-
我想知道如果相同的hashCode但不同的对象,这个数组的索引如何存储多个Entry对象。
-
这与
LinkedHashMap实施有什么不同?它是map的双链表实现,但是它是否像上面那样维护一个数组,它如何存储指向下一个和前一个元素的指针?
5 个答案:
答案 0 :(得分:55)
HashMap不维护插入顺序,因此不会维护任何双向链表。
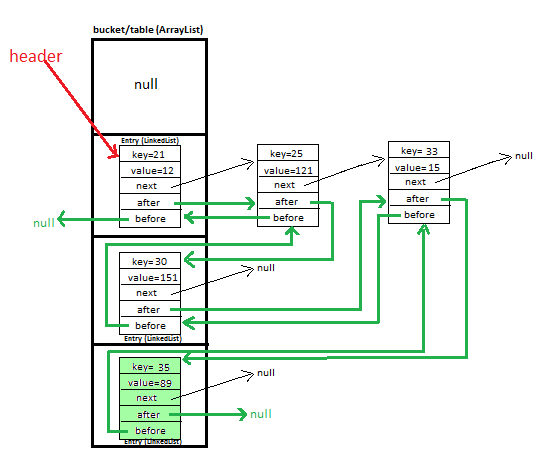
LinkedHashMap最突出的特点是它维护键值对的插入顺序。 LinkedHashMap使用双重链接列表来执行此操作。
LinkedHashMap的输入如下所示 -
static class Entry<K, V> {
K key;
V value;
Entry<K,V> next;
Entry<K,V> before, after; //For maintaining insertion order
public Entry(K key, V value, Entry<K,V> next){
this.key = key;
this.value = value;
this.next = next;
}
}
通过使用之前和之后 - 我们跟踪LinkedHashMap中新添加的条目,这有助于我们维护插入顺序。
在参考之前的参赛作品之前 after引用LinkedHashMap中的下一个条目。
有关图表和分步说明,请参阅http://www.javamadesoeasy.com/2015/02/linkedhashmap-custom-implementation.html
谢谢.. !!
答案 1 :(得分:42)
因此,它有一个
Entry个对象的数组。
不完全是。它有一个Entry对象链的数组。 HashMap.Entry对象有一个next字段,允许将Entry个对象链接为链接列表。
我想知道如果相同的hashCode但是不同的对象,这个数组的索引如何存储多个
Entry个对象。
因为(如问题中的图片所示)Entry个对象被链接。
这与
LinkedHashMap实施有什么不同?它是map的双链表实现,但它是否像上面那样维护一个数组,它如何存储指向下一个和前一个元素的指针?
在LinkedHashMap实施中,LinkedHashMap.Entry类通过添加HashMap.Entry和before字段来扩展after类。这些字段用于将LinkedHashMap.Entry个对象组合成一个记录插入顺序的独立双向链表。因此,在LinkedHashMap类中,条目对象位于两个不同的链中:
-
通过主哈希数组访问的单链接哈希链,
-
一个单独的双向链接列表,列出了在条目插入顺序中保留的所有条目。
答案 2 :(得分:10)
自己拿一个look。为了将来参考,你可以谷歌:
java LinkedHashMap source
HashMap使用LinkedList来处理绑定,但HashMap和LinkedHashMap之间的区别在于LinkedHashMap具有可预测的迭代顺序,这是实现的通过一个额外的双向链表,通常保持键的插入顺序。例外情况是重新插入密钥时,在这种情况下它会返回到列表中的原始位置。
作为参考,迭代LinkedHashMap比迭代HashMap更有效,但LinkedHashMap的内存效率更低。
如果从上面的解释中不清楚,散列过程是相同的,那么你可以获得正常散列的好处,但是你也可以获得上面所述的迭代优势,因为你正在使用双倍的链接列表,用于维护Entry个对象的顺序,这与在冲突哈希期间使用的链表无关,如果不明确的话......
编辑:(响应OP的评论):
HashMap由数组支持,其中一些插槽包含Entry个对象链以处理冲突。要遍历所有(键,值)对,您需要遍历数组中的所有插槽,然后通过LinkedLists;因此,您的总时间将与容量成比例。
使用LinkedHashMap时,您需要做的只是遍历双向链表,因此总时间与大小成正比。
答案 3 :(得分:1)
由于其他答案都没有实际解释如何实现这样的事情,我会给它一个机会。
一种方法是在用户看不到的值(key-&gt;值对)中有一些额外的信息,这些信息引用了插入到哈希映射中的上一个和下一个元素。好处是您仍然可以在常量时间中删除元素从散列图中删除是恒定时间,并且在这种情况下从链接列表中删除是因为您有对该条目的引用。您仍然可以在常量时间插入,因为哈希映射插入是常量,链表不是正常的,但在这种情况下,您可以持续访问链表中的某个点,这样您就可以在常量时间插入,最后检索是恒定时间因为你只需处理它的结构的哈希映射部分。
请记住,像这样的数据结构并非没有成本。由于所有额外的引用,哈希映射的大小将显着增加。每个主要方法都会稍微慢一些(如果重复调用则可能很重要)。并且数据结构的间接性(不确定这是一个真正的术语:P)是否会增加,尽管这可能不是那么大,因为引用可以保证指向哈希映射中的内容。
由于这种结构的唯一优点是在使用它时保持顺序要小心。另外,在阅读答案时请记住,我不知道这是它实施的方式,但如果给出任务,我就是这样做的。
在oracle docs上有一个引述确认了我的一些猜测。
这个实现与HashMap的不同之处在于它维护着一个运行所有条目的双向链表。
来自同一网站的另一个相关引用。
此类提供所有可选的Map操作,并允许null元素。与HashMap一样,它为基本操作(添加,包含和删除)提供了恒定时间性能,假设哈希函数在桶之间正确地分散元素。由于维护链表的额外费用,性能可能略低于HashMap的性能,但有一个例外:对LinkedHashMap的集合视图进行迭代需要与映射大小成比例的时间,无论其容量如何。对HashMap的迭代可能更昂贵,需要与其容量成比例的时间。
答案 4 :(得分:-1)
hashCode将通过散列函数映射到任何存储桶。如果hashCode中发生冲突而不是HashMap通过链接解决此冲突,即它会将值添加到链表中。以下是执行此操作的代码:
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
392 Object k;
393 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
394 `enter code here` V oldValue = e.value;
395 e.value = value;
396 e.recordAccess(this);
397 return oldValue;
398 }
399 }
您可以清楚地看到它遍历链接列表,如果找到密钥,则替换旧值,并将新的else附加到链接列表。
但LinkedHashMap和HashMap之间的差异是LinkedHashMap维持广告订单。来自docs:
此链接列表定义迭代排序,通常是键插入映射的顺序(插入顺序)。请注意,如果将键重新插入地图,则插入顺序不会受到影响。 (如果m.containsKey(k)在调用之前立即返回true,则调用m.put(k,v)时,将密钥k重新插入映射m。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?