当匹配满足另一个匹配时,正则表达式中的匹配限制
我有一个类似于以下内容的字符串
id=16&xxx&sid=3
xxx&sid=3&id=5
xxx&xxx&id=6
sid=5&xxxx
基本上,有id和sid,我想用正则表达式解析它们的值,但问题是以“id”结尾
我有以下正则表达式
ssid=(\d{1,})
id=(\d{1,})
我可以对第二个表达式id=(\d{1,})做什么,它认为ss(id)= x匹配。
考虑到我不知道表达之前会发生什么,我该怎么做才能解决这个问题?
我怎么能做一些事情,只要它不在ss之前就认为是匹配
3 个答案:
答案 0 :(得分:2)
除非前面带有s ,否则
/(?:^|[^s])id=(\d+)/将匹配
正则表达式的第一部分:(?:^|[^s])表示“匹配字符串的开头或除了s之外的任何东西”
您还会注意到我将\d{1,}切换为\d+,因为他们做同样的事情
更新
因为它不是“sid”你试图避免,而是“ssid”,请改用它:
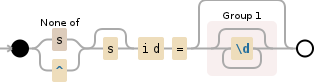
/(?:^|[^s])s?id=(\d+)/
这将匹配sid,但不匹配ssid,如果这是你需要的
答案 1 :(得分:1)
答案 2 :(得分:1)
由于这看起来像URL的查询参数列表,我认为它是一个。
我认为单个正则表达式不是最佳匹配解决方案。最明确和最明显的解决方案是:
- 在
&上拆分字符串
- 在
=上拆分每个部分,创建地图 - 在该地图中查找您需要的按键
这样,您可以稍后使用该字符串中的更多参数。它还有助于以后阅读代码并直观地验证其正确性。
这通常扩展到URL处理。更好地将其解析为可读结构(无论您的语言是什么),并使用各个部分的访问功能。由于URL部分的正确转义和取消错误并非易事,因此应该有一个小库。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?