总结我对主题的理解'虚拟编码'通常被理解为将K可能值编码为名义属性为K-1二进制虚拟对象。 K值的使用会导致冗余并且会产生负面影响,例如:关于逻辑回归,据我所知。到目前为止,一切都很清楚。
然而,我不清楚两个问题:
1)考虑到上述问题,我很困惑WEKA中的'Logistic'分类器实际上使用了K个假人(见图)。 为什么会出现这种情况?
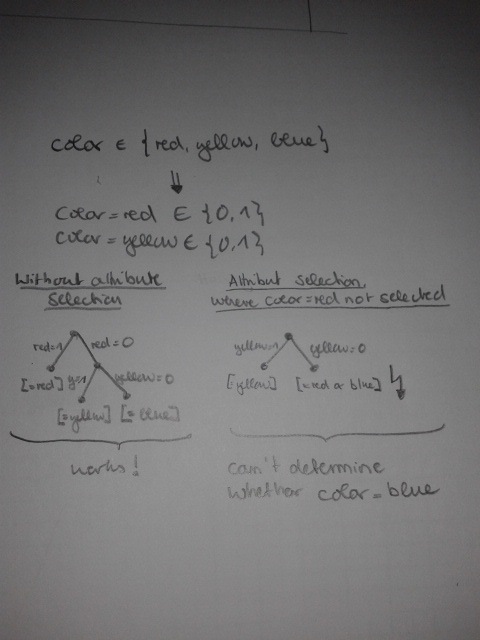
2)一旦考虑属性选择就会出现问题。如果所有虚拟对象实际用于模型,则隐含地包括剩余属性值作为所有虚拟对象为零的情况,如果缺少一个虚拟对象(未在属性选择中选择),则不再包括它。我上传的草图很容易理解这个问题。 如何处理该问题?
其次
图片 的
WEKA输出: Logistic算法在UCI数据集German Credit上运行,其中第一个属性的可能值为A11,A12,A13,A14。所有这些都包含在逻辑回归模型中。 http://abload.de/img/bildschirmfoto2013-089out9.png
决策树示例:草图显示在属性选择后在具有虚拟编码实例的数据集上运行决策树时的问题。 http://abload.de/img/sketchziu5s.jpg
答案 0 :(得分:1)
当您使用k个假人而不是k-1个假人时,输出通常更易于阅读,解释和使用。我想这就是为什么每个人似乎都在使用k假人。 但是,是的,因为k值总和为1,所以存在可能导致问题的相关性。但数据集中的相关性很常见,你永远不会完全摆脱它们!
我认为功能选择和虚拟编码不合适。它等于从属性中删除一些值。你为什么坚持做功能选择?
您确实应该使用加权,或考虑可以处理此类数据的更高级算法。事实上,虚拟变量可能会导致同样的麻烦,因为它们是二进制的,而且很多算法(例如k-means)对二进制变量没有多大意义。
对于决策树:不执行,输出属性上的功能选择 ... 另外,由于决策树已经选择了特征,所以无论如何都要做到这一点......将它留给决策树来决定用于分割的属性。这样,它也可以学习依赖性。
{kind=link}
{kind=link}