将图形数据表示为键值对象
我开始深入研究图形数据库,但我不知道这些图形是如何在内部存储的。假设我有这张图(取自Wikipedia):
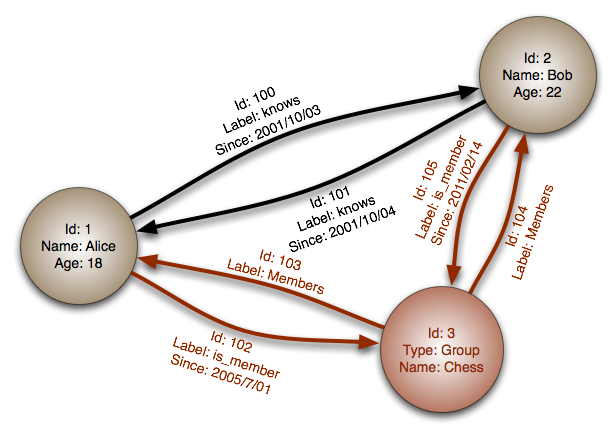
如何将此图表序列化为键值对象?(例如Python词典)
我想象两个dicts,一个用于顶点,一个用于边缘:
{'vertices':
{'1': {'Name': 'Alice', 'Age': 18},
'2': {'Name': 'Bob', 'Age': 22},
'3': {'Type': 'Group', 'Name': 'Chess'}},
'edges':
{'100': {'Label': 'knows', 'Since': '2001/10/03'},
'101': {'Label': 'knows', 'Since': '2001/10/04'},
'102': {'Label': 'is_member', 'Since': '2005/7/01'},
'103': {'Label': 'Members'},
'104': {'Label': 'Members'},
'105': {'Label': 'is_member', 'Since': '2011/02/14'}},
'connections': [['1', '2', '100'], ['2', '1', '101'],
['1', '3', '102'], ['3', '1', '103'],
['3', '2', '104'], ['2', '3', '105']]}
但我不确定,这是否是最实用的实施方案。也许“连接”应该在“顶点”字典内。那么,使用键值对象实现图数据存储的最佳方法是什么?我可以在哪里以及在哪里阅读更多相关信息?
可能相关但不重复:How to represent a strange graph in some data structure
6 个答案:
答案 0 :(得分:11)
正常模式是没有单独的connections结构,而是将该信息放在edges结构中。这给出了类似的东西:
{
'vertices': {
'1': {'Name': 'Alice', 'Age': 18},
'2': {'Name': 'Bob', 'Age': 22},
'3': {'Type': 'Group', 'Name': 'Chess'} },
'edges': [
{'from': '1', 'to': '2', 'Label': 'knows', 'Since': '2001/10/03'},
{'from': '2', 'to': '1', 'Label': 'knows', 'Since': '2001/10/04'},
{'from': '1', 'to': '3', 'Label': 'is_member', 'Since': '2005/7/01'},
{'from': '3', 'to': '1', 'Label': 'Members'},
{'from': '3', 'to': '2', 'Label': 'Members'},
{'from': '2', 'to': '3', 'Label': 'is_member', 'Since': '2011/02/14'} ] }
答案 1 :(得分:5)
似乎没问题 - 每个对象都有它,没有重复。它对“阅读和处理目的”有好处。但没有'最佳'代表。它总是取决于你的目的。你想要能够通过名称快速找到顶点吗?或按日期划分边缘?或者你想快速测试两个顶点是否连接?或者相反 - 您想快速修改图表的某些部分?每个目的都需要不同的数据库表数据结构
答案 2 :(得分:4)
这些图如何在内部存储
如何将此图序列化为键值对象
这些问题不同,需要不同的答案。
在前一种情况下,主要要求可能是有效执行复杂的查询。
我建议研究现有的工业强度解决方案。
用NoSQL术语来说,这些嵌套的键值对象是文档。因此,人们可以研究图如何存储在“分层”多模型数据库中,这些数据库是:
- 支持图形数据模型,和
- 使用基础文档数据模型。
此类数据库的示例是ArangoDB,OrientDB,Azure CosmosDB。
您还可以将“文档数据模型”替换为“宽列数据模型”,因为可以将宽列数据模型视为二维键值模型。
此类数据库的示例是DataStax Enterprise Graph或Grakn。
例如,在ArangoDB中,边stored作为常规文档,但是在特殊集合中。
很显然,所使用的数据结构可能会附带其他索引等(or not)。
那么,使用键值对象实现图形数据存储的最佳方法是什么?
我在哪里以及在哪里可以了解到更多信息?
我建议另一篇来自ArangoDB的文章:
答案 3 :(得分:1)
我不会对Eamonn的答案进行任何更改。
每个顶点和边缘都有3个元素。.id,标签和属性
{
'vertices': {
'1': {'Label' : Person, 'Properties' : { 'Name': 'Alice', 'Age': 18}},
'2': {'Label' : Person, 'Properties' : {'Name': 'Bob', 'Age': 22}},
'3': {'Label': 'Group', 'Properties' : { 'Name': 'Chess'} },
'edges': [
'4' : {'from': '1', 'to': '2', 'Label': 'knows', 'Properties':{'Since': '2001/10/03' , 'Until' : '2001/10/03'}},
'5' : {'from': '2', 'to': '1', 'Label': 'knows', 'Properties':{'Since': '2001/10/04', 'Until' : '2001/10/05'}}
]
}
通过这种方式,您可以按顶点/边缘及其标签和属性进行查询。
答案 4 :(得分:1)
我会像这样序列化它,除了您应该根据查找的内容选择密钥。我以为您使用的是ID,但也许使用名称会更好。
{
'members': {
'1': {
'id': '1',
'name': 'Alice',
'age': 18,
'groups': {
'3': {
'path': 'groups.3',
'since': '2005-07-01'
}
},
'knows': {
'2': {
'path': 'members.2',
'since': '2001-10-03'
}
}
},
'2': {
'id': '2',
'name': 'Bob',
'age': 22,
'groups': {
'3': {
'path': 'groups.3',
'since': '2011-02-14'
}
},
'knows': {
'1': {
'path': 'members.1',
'since': '2001-10-04'
}
}
}
},
'groups': {
'3': {
'id': '3',
'name': 'Chess',
'members': {
'1': { 'path': 'members.1' },
'2': { 'path': 'members.2' }
}
}
}
}
如果您有一种序列化对图形其他部分的引用的方法,那么可以直接将图形序列化为键-值对,这就是我使用'path'的目的。如果我将其反序列化为字典,则可以考虑将路径值替换为它们所引用的实际字典。请记住,这可能会导致循环引用,如果将其序列化为json或其他内容,可能会导致问题。
答案 5 :(得分:1)
我也将在结构中添加一个邻接。我的看法就是这样,
{
'vertices': {
'1': {'Name': 'Alice', 'Age': 18},
'2': {'Name': 'Bob', 'Age': 22},
'3': {'Type': 'Group', 'Name': 'Chess'}
},
'edges': {
'100' : {'from': '1', 'to': '2', 'Label': 'knows', 'Since': '2001/10/03'},
'101': {'from': '2', 'to': '1', 'Label': 'knows', 'Since': '2001/10/04'},
....
},
'adjacency': {
'1': ['101', '102'],
...
}
}
这样,我可以轻松地找到哪些顶点与顶点相邻,而无需遍历所有的顶点。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?