用于确定两个Glob模式(或正则表达式)的匹配是否相交的算法
我正在寻找与Redis KEYS command accepts类似的匹配的glob样式模式。引用:
- h?llo匹配hello,hallo和hxllo
- h * llo匹配hllo和heeeello
- h [ae] llo匹配hello和hallo,但不匹配hillo
但是我没有匹配文本字符串,而是将模式与另一个模式匹配,所有运算符都在两端都有意义。
例如,这些模式应该在同一行中相互匹配:
prefix* prefix:extended*
*suffix *:extended:suffix
left*right left*middle*right
a*b*c a*b*d*b*c
hello* *ok
pre[ab]fix* pre[bc]fix*
这些不应该匹配:
prefix* wrong:prefix:*
*suffix *suffix:wrong
left*right right*middle*left
pre[ab]fix* pre[xy]fix*
?*b*? bcb
所以我想知道......
- 如果可以这样做(实施验证算法),如果有的话?
- 如果不可能,可以使用正则表达式的哪个子集? (即禁止*通配符?)
- 如果确实有可能,什么是有效的算法?
- 所需的时间复杂度是多少?
编辑:找到this other question on RegEx subset,但这与hello*和*ok匹配的字段不是彼此的子集/超集的字词不完全相同但他们相交了。
所以我在数学上猜,这可能是用来表示的;是否有可能确定地检查一个模式匹配的一组单词,与另一个模式匹配的一组单词相交,导致非空集?
编辑:朋友@neizod制定了此排除表,可以整齐地显示可能的潜在/部分解决方案:Elimination rule
编辑:将为那些也可以提供工作代码(使用任何语言)和测试案例的人增加额外的奖励。
编辑:添加了?* b *? @DanielGimenez在评论中发现的测试用例。
5 个答案:
答案 0 :(得分:19)
现在见证了这个完全的ARMED和OPERATIONAL战斗站的火力!
(我在这个答案上做得太多了,我的大脑坏了;应该有一个徽章。)
为了确定两个模式是否相交,我创建了一个递归回溯解析器 - 当遇到 Kleene stars 时,会创建一个新堆栈,以便在它失败时在将来,所有内容都会回滚,并且 明星 会消耗下一个字符。
你可以查看这个答案的历史,以确定如何达到这一点以及为什么有必要,但基本上仅通过向前看一个标记来确定一个交叉点是不够的,这就是我以前做过的事情。
这种情况打破了旧答案[abcd]d => *d。 设置 与 明星 后的d相匹配,因此左侧仍有令牌,而右边则是完整的。但是,这两种模式在ad,bd,cd和dd上相交,因此需要修复。我的几乎 O(N)的答案被抛弃了。
词法
lexing过程是微不足道的,除了处理转义字符并删除多余的 明星 。代币分为 集 , 明星 , 野生字符(?) 和 字符 。这与我以前的版本不同,其中一个标记是一串字符而不是单个字符。随着越来越多的案例出现,以字符串作为代币更多的是障碍而不是优势。
分析器
解析器的大多数功能都非常简单。给定左侧类型的开关调用一个函数,该函数是一个开关,用于确定将其与右侧类型进行比较的适当函数。比较的结果将两个开关冒泡到原来的被调用者,通常是解析器的主循环。
解析星星
简单性以 明星 结束。遇到这种情况时会占用一切。首先,它将其边的下一个标记与另一边的标记进行比较,推进另一边,直到找到匹配为止。
找到匹配后,它会检查一切是否匹配到两种模式的结尾。如果是,那么图案相交。否则,它将另一方的下一个标记从它与之对比的原始标记前进并重复该过程。
当遇到两个 anys 时,从彼此的下一个标记开始,进入他们自己的替代分支。
function intersects(left, right) {
var lt, rt,
result = new CompareResult(null, null, true);
lt = (!left || left instanceof Token) ? left : tokenize(left);
rt = (!right || right instanceof Token) ? right : tokenize(right);
while (result.isGood && (lt || rt)) {
result = tokensCompare(lt, rt);
lt = result.leftNext;
rt = result.rightNext;
}
return result;
}
function tokensCompare(lt, rt) {
if (!lt && rt) return tokensCompare(rt, lt).swapTokens();
switch (lt.type) {
case TokenType.Char: return charCompare(lt, rt);
case TokenType.Single: return singleCompare(lt, rt);
case TokenType.Set: return setCompare(lt, rt);
case TokenType.AnyString: return anyCompare(lt, rt);
}
}
function anyCompare(tAny, tOther) {
if (!tOther) return new CompareResult(tAny.next, null);
var result = CompareResult.BadResult;
while (tOther && !result.isGood) {
while (tOther && !result.isGood) {
switch (tOther.type) {
case TokenType.Char: result = charCompare(tOther, tAny.next).swapTokens(); break;
case TokenType.Single: result = singleCompare(tOther, tAny.next).swapTokens(); break;
case TokenType.Set: result = setCompare(tOther, tAny.next).swapTokens(); break;
case TokenType.AnyString:
// the anyCompare from the intersects will take over the processing.
result = intersects(tAny, tOther.next);
if (result.isGood) return result;
return intersects(tOther, tAny.next).swapTokens();
}
if (!result.isGood) tOther = tOther.next;
}
if (result.isGood) {
// we've found a starting point, but now we want to make sure this will always work.
result = intersects(result.leftNext, result.rightNext);
if (!result.isGood) tOther = tOther.next;
}
}
// If we never got a good result that means we've eaten everything.
if (!result.isGood) result = new CompareResult(tAny.next, null, true);
return result;
}
function charCompare(tChar, tOther) {
if (!tOther) return CompareResult.BadResult;
switch (tOther.type) {
case TokenType.Char: return charCharCompare(tChar, tOther);
case TokenType.Single: return new CompareResult(tChar.next, tOther.next);
case TokenType.Set: return setCharCompare(tOther, tChar).swapTokens();
case TokenType.AnyString: return anyCompare(tOther, tChar).swapTokens();
}
}
function singleCompare(tSingle, tOther) {
if (!tOther) return CompareResult.BadResult;
switch (tOther.type) {
case TokenType.Char: return new CompareResult(tSingle.next, tOther.next);
case TokenType.Single: return new CompareResult(tSingle.next, tOther.next);
case TokenType.Set: return new CompareResult(tSingle.next, tOther.next);
case TokenType.AnyString: return anyCompare(tOther, tSingle).swapTokens();
}
}
function setCompare(tSet, tOther) {
if (!tOther) return CompareResult.BadResult;
switch (tOther.type) {
case TokenType.Char: return setCharCompare(tSet, tOther);
case TokenType.Single: return new CompareResult(tSet.next, tOther.next);
case TokenType.Set: return setSetCompare(tSet, tOther);
case TokenType.AnyString: return anyCompare(tOther, tSet).swapTokens();
}
}
function anySingleCompare(tAny, tSingle) {
var nextResult = (tAny.next) ? singleCompare(tSingle, tAny.next).swapTokens() :
new CompareResult(tAny, tSingle.next);
return (nextResult.isGood) ? nextResult: new CompareResult(tAny, tSingle.next);
}
function anyCharCompare(tAny, tChar) {
var nextResult = (tAny.next) ? charCompare(tChar, tAny.next).swapTokens() :
new CompareResult(tAny, tChar.next);
return (nextResult.isGood) ? nextResult : new CompareResult(tAny, tChar.next);
}
function charCharCompare(litA, litB) {
return (litA.val === litB.val) ?
new CompareResult(litA.next, litB.next) : CompareResult.BadResult;
}
function setCharCompare(tSet, tChar) {
return (tSet.val.indexOf(tChar.val) > -1) ?
new CompareResult(tSet.next, tChar.next) : CompareResult.BadResult;
}
function setSetCompare(tSetA, tSetB) {
var setA = tSetA.val,
setB = tSetB.val;
for (var i = 0, il = setA.length; i < il; i++) {
if (setB.indexOf(setA.charAt(i)) > -1) return new CompareResult(tSetA.next, tSetB.next);
}
return CompareResult.BadResult;
}
jsFiddle
时间复杂度
任何带有“递归回溯”字样的东西至少是O(N 2 )。
可维护性和可读性
我故意用一个单一的开关将任何分支分成自己的函数。当一个字符串就足够时,我会使用命名常量。这样做会使代码更长,更冗长,但我认为这样可以更容易理解。
测试
您可以查看小提琴中的所有测试。您可以在Fiddle输出中查看注释以收集它们的用途。每种令牌类型都针对每种令牌类型进行了测试,但我没有在一次测试中尝试过所有可能的比较。我还想出了一些像下面那样的随机强硬的东西。
abc[def]?fghi?*nop*[tuv]uv[wxy]?yz =&gt; a?[cde]defg*?ilmn[opq]*tu*[xyz]*
如果有人想自己测试一下,我在 jsFiddle 上添加了一个界面。添加递归后,日志记录就会中断。
我认为我没有尝试过足够的负面测试,尤其是我创建的最新版本。
优化
目前解决方案是一个强力解决方案,但足以处理任何情况。我想在某些时候回到这一点,通过一些简单的优化来改善时间复杂度。
在开始时检查以减少比较可能会增加某些常见方案的处理时间。例如,如果一个模式以 星 开头,一个以一个结尾,那么我们就知道它们会相交。我还可以检查模式开始和结束时的所有字符,如果两个模式匹配,则删除它们。这样,它们将被排除在未来的任何递归之外。
致谢
我最初使用 @m.buettner的测试来测试我的代码,然后再找到我自己的代码。我还通过他的代码来帮助我更好地理解这个问题。
答案 1 :(得分:7)
使用非常简化的模式语言,问题中的pastebin链接和jpmc26的注释几乎就在那里:主要问题是,输入字符串的文字左右两端是否匹配。如果它们都这样,并且两者都包含至少一个*,则字符串匹配(因为您始终可以将文本文本中的其他字符串与该星形匹配)。有一种特殊情况:如果只有一个是空的(在删除前缀和后缀之后),如果另一个完全由* s组成,它们仍然可以匹配。
当然,在检查字符串的末尾是否匹配时,您还需要考虑单字符通配符?和字符类。单字符通配符很简单:它不会失败,因为它总是匹配其他字符。如果它是一个字符类,而另一个只是一个字符,则需要检查该字符是否在该类中。如果它们都是类,则需要检查类的交集(这是一个简单的集合交集)。
以下是JavaScript中的所有内容(查看代码注释,了解我上面概述的算法如何映射到代码):
var trueInput = [
{ left: 'prefix*', right: 'prefix:extended*' },
{ left: '*suffix', right: '*:extended:suffix' },
{ left: 'left*right', right: 'left*middle*right' },
{ left: 'a*b*c', right: 'a*b*d*b*c' },
{ left: 'hello*', right: '*ok' },
{ left: '*', right: '*'},
{ left: '*', right: '**'},
{ left: '*', right: ''},
{ left: '', right: ''},
{ left: 'abc', right: 'a*c'},
{ left: 'a*c', right: 'a*c'},
{ left: 'a[bc]d', right: 'acd'},
{ left: 'a[bc]d', right: 'a[ce]d'},
{ left: 'a?d', right: 'acd'},
{ left: 'a[bc]d*wyz', right: 'abd*w[xy]z'},
];
var falseInput = [
{ left: 'prefix*', right: 'wrong:prefix:*' },
{ left: '*suffix', right: '*suffix:wrong' },
{ left: 'left*right', right: 'right*middle*left' },
{ left: 'abc', right: 'abcde'},
{ left: 'abcde', right: 'abc'},
{ left: 'a[bc]d', right: 'aed'},
{ left: 'a[bc]d', right: 'a[fe]d'},
{ left: 'a?e', right: 'acd'},
{ left: 'a[bc]d*wyz', right: 'abc*w[ab]z'},
];
// Expects either a single-character string (for literal strings
// and single-character wildcards) or an array (for character
// classes).
var characterIntersect = function(a,b) {
// If one is a wildcard, there is an intersection.
if (a === '?' || b === '?')
return true;
// If both are characters, they must be the same.
if (typeof a === 'string' && typeof b === 'string')
return a === b;
// If one is a character class, we check that the other
// is contained in the class.
if (a instanceof Array && typeof b === 'string')
return (a.indexOf(b) > -1);
if (b instanceof Array && typeof a === 'string')
return (b.indexOf(a) > -1);
// Now both have to be arrays, so we need to check whether
// they intersect.
return a.filter(function(character) {
return (b.indexOf(character) > -1);
}).length > 0;
};
var patternIntersect = function(a,b) {
// Turn the strings into character arrays because they are
// easier to deal with.
a = a.split("");
b = b.split("");
// Check the beginnings of the string (up until the first *
// in either of them).
while (a.length && b.length && a[0] !== '*' && b[0] !== '*')
{
// Remove the first character from each. If it's a [,
// extract an array of all characters in the class.
aChar = a.shift();
if (aChar == '[')
{
aChar = a.splice(0, a.indexOf(']'));
a.shift(); // remove the ]
}
bChar = b.shift();
if (bChar == '[')
{
bChar = b.splice(0, b.indexOf(']'));
b.shift(); // remove the ]
}
// Check if the two characters or classes overlap.
if (!characterIntersect(aChar, bChar))
return false;
}
// Same thing, but for the end of the string.
while (a.length && b.length && a[a.length-1] !== '*' && b[b.length-1] !== '*')
{
aChar = a.pop();
if (aChar == ']')
{
aChar = a.splice(a.indexOf('[')+1, Number.MAX_VALUE);
a.pop(); // remove the [
}
bChar = b.pop();
if (bChar == ']')
{
bChar = b.splice(b.indexOf('[')+1, Number.MAX_VALUE);
b.pop(); // remove the [
}
if (!characterIntersect(aChar, bChar))
return false;
}
// If one string is empty, the other has to be empty, too, or
// consist only of stars.
if (!a.length && /[^*]/.test(b.join('')) ||
!b.length && /[^*]/.test(b.join('')))
return false;
// The only case not covered above is that both strings contain
// a * in which case they certainly overlap.
return true;
};
console.log('Should be all true:');
console.log(trueInput.map(function(pair) {
return patternIntersect(pair.left, pair.right);
}));
console.log('Should be all false:');
console.log(falseInput.map(function(pair) {
return patternIntersect(pair.left, pair.right);
}));
它不是最新的实现,但它有效并且(希望)仍然非常易读。检查开头和结尾有相当多的代码重复(在检查开头后可以通过简单的reverse来缓解 - 但我认为这只是模糊了事情)。并且可能有很多其他位可以大大改进,但我认为逻辑已经到位。
还有一些评论:实现假设模式格式正确(没有不匹配的开始或结束括号)。另外,我从this answer获取了数组交集代码,因为它很紧凑 - 如果有必要,你当然可以提高效率。
无论这些实现细节如何,我想我也可以回答你的复杂性问题:外部循环同时遍历两个字符串,一次一个字符。这就是线性复杂性。除了字符类测试之外,循环内的所有内容都可以在恒定时间内完成。如果一个字符是字符类而另一个字符不是,则需要线性时间(以类的大小作为参数)来检查字符是否在类中。但这并不能使它成为二次方,因为类中的每个字符意味着外循环的一次迭代次数减少。所以这仍然是线性的。因此,最昂贵的是两个字符类的交集。这可能比线性时间更复杂,但最糟糕的可能是O(N log N):毕竟,你可以对两个字符类进行排序,然后在线性时间内找到一个交集。我想你甚至可以通过将字符类中的字符散列到它们的Unicode代码点(JS中的.charCodeAt(0))或其他一些数字来获得整体线性时间复杂度 - 并且在散列集中找到一个交集是线性时间可能。所以,如果你真的想,我认为你应该能够进入O(N)。
什么是N?上限是两种模式长度的总和,但在大多数情况下,它实际上会更少(取决于前缀的长度和两种模式的后缀)。
请指出我的算法缺失的任何边缘情况。如果他们改进或至少不会降低代码的清晰度,我也对建议的改进感到高兴。
Here is a live demo on JSBin(感谢chakrit将其粘贴在那里)。
编辑:正如Daniel指出的那样,我的算法错过了一个概念性的边缘情况。如果(消除开头和结尾之前或之后)一个字符串不包含*而另一个字符串不包含,则存在两个仍然发生冲突的情况。不幸的是,我现在还没有时间来调整我的代码片段来解决这个问题,但我可以概述一下如何解决它。
消除字符串的两端后,如果两个字符串都为空或两者都至少包含*,则它们将始终匹配(完成消除后查看可能的* - 分布以查看此)。唯一不重要的情况是,如果一个字符串仍然包含*,但另一个字符串不是(无论是否为空)。我们现在需要做的是从左到右再次走两根弦。让我调用包含* A的字符串以及不包含* B的字符串。
我们从左向右走A,跳过所有*(仅关注?,字符类和文字字符)。对于每个相关的令牌,我们从左到右检查,如果它可以在B中匹配(在第一次出现时停止)并将我们的B光标前进到该位置。如果我们在A中找到一个无法在B中找到的令牌,则它们不匹配。如果我们设法为A中的每个标记找到匹配项,则它们匹配。这样,我们仍然使用线性时间,因为不涉及回溯。这是两个例子。这两个应匹配:
A: *a*[bc]*?*d* --- B: db?bdfdc
^ ^
A: *a*[bc]*?*d* --- B: db?bdfdc
^ ^
A: *a*[bc]*?*d* --- B: db?bdfdc
^ ^
A: *a*[bc]*?*d* --- B: db?bdfdc
^ ^
这两个不匹配:
A: *a*[bc]*?*d* --- B: dbabdfc
^ ^
A: *a*[bc]*?*d* --- B: dbabdfc
^ ^
A: *a*[bc]*?*d* --- B: dbabdfc
^ ^
A: *a*[bc]*?*d* --- B: dbabdfc
!
失败,因为?在第二个d之前无法匹配,之后B中没有其他d来容纳A中的最后一个d
如果我花时间将字符串正确地解析为令牌对象,那么这可能很容易添加到我当前的实现中。但是现在,我不得不再次解析这些角色类。我希望这个补充的书面大纲是足够的帮助。
PS:当然,我的实现也没有考虑转义元字符,并且可能会在*字符类内部窒息。
答案 2 :(得分:6)
这些特殊模式的功能远远不如完整的正则表达式,但我会指出,即使使用常规正则表达式, 也可以做到你想做的事情。这些必须是“真正的”正则表达式,即那些仅使用Kleene星,交替(|运算)和连接任何固定字母加上空字符串和空集的正则表达式。当然你也可以在这些操作上使用任何语法糖:一个或多个(+),可选(?)。字符集只是一种特殊的交替[a-c] == a | b | c。
该算法原则上很简单:使用标准结构将每个正则表达式转换为DFA:Thompson后跟powerset。然后使用叉积构造计算两个原件的交点DFA。最后检查此交叉点DFA以确定它是否接受至少一个字符串。这只是从开始状态开始的dfs,看看是否可以达到接受状态。
如果您不熟悉这些算法,可以轻松找到Internet引用。
如果交集DFA接受至少一个字符串,则原始正则表达式之间存在匹配,并且dfs发现的路径提供满足两者的字符串。否则没有匹配。
答案 3 :(得分:5)
好问题!
这里的主要复杂性是处理字符类([...])。我的方法是用正则表达式替换每个表达式,该正则表达式查找 指定字符之一(或?)或包含at的另一个字符类至少一个指定的字符。因此对于[xyz],这将是:([xyz?]|\[[^\]]*[xyz].*?\]) - 见下文:
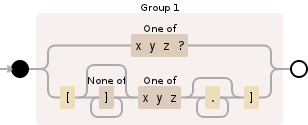
然后对于“前缀”(第一个*之前的所有内容),将^放在开头或“后缀”(后一个*之后的所有内容),放置{{1最后。
进一步详情: -
- 还需要将
$的所有实例替换为?,以使其与字符类或单个字符匹配(不包括左方括号)。 - 还需要替换不在字符类中且不是
(\[.*?\]|[^\\]])的每个单独字符,以使其匹配相同的字符?或包含该字符的字符类。例如。?将成为a。 (有点啰嗦,但结果证明是必要的 - 见下面的评论)。 - 测试应该按照以下两种方式进行:测试前缀#1转换为正则表达式对前缀#2然后测试前缀#2转换为正则表达式对前缀# 1。如果匹配,前缀可以说是“相交”。
- 对后缀重复步骤(3.):对于肯定结果, 前缀和后缀必须相交。
编辑:除上述内容外,还有一种特殊情况,其中一个模式至少包含一个([a?]|\[[^\]]*a.*?\])但另一个模式不包含*。在这种情况下,应将*的整个模式转换为正则表达式:*应与任何内容匹配,但条件是它只包含整个字符类。这可以通过将*的所有实例替换为(\[.*?\]|[^\\]])来完成。
为了避免这个答案变得笨重,我不会发布完整的代码,但是这里有一个单元测试的工作演示:http://jsfiddle.net/mb3Hn/4/
编辑#2 - 已知不完整:在当前形式中,演示不支持转义字符(例如\[)。这不是一个很好的借口,但我只是在当天晚些时候才注意到这些 - 他们在问题中没有提到,只有link。为了处理它们,需要一些额外的正则表达式复杂性,例如,检查[之前是否存在反斜杠。 negative lookbehind这应该是相当轻松的,但遗憾的是Javascript不支持它。有一些解决方法,例如将字符串和正则表达式反转为负前瞻但我不喜欢使用这种额外的复杂性来降低代码的可读性,并且不确定它对OP的重要性,因此将其作为“练习”读者“。回想起来,应该选择一种更全面的正则表达式支持的语言!
答案 4 :(得分:0)
使用greenery确定正则表达式是否与另一个正则表达式的子集匹配:
首先,pip3 install https://github.com/ferno/greenery/archive/master.zip。
然后:
from greenery.lego import parse as p
a_z = p("[a-z]")
b_x = p("[b-x]")
assert a_z | b_x == a_z
m_n = p("m|n")
zero_nine = p("[0-9]")
assert not m_n | zero_nine == m_n
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?