智能进度条ETA计算
在许多应用程序中,我们为文件下载,压缩任务,搜索等提供了一些进度条。我们经常使用进度条让用户知道正在发生的事情。如果我们知道一些细节,比如已完成了多少工作以及剩下多少工作,我们甚至可以通过推断从达到当前进度水平所需的时间来估算时间。
compression ETA screenshot http://jameslao.com/wp-content/uploads/2008/01/winrar-progress-bar.png
{kind=link}
但是我们也看到过这个时间留下“ETA”显示的节目只是滑稽的。它声称文件副本将在20秒内完成,然后一秒后它会说需要4天,然后再次闪烁20分钟。它不仅无益,而且令人困惑! ETA变化如此之大的原因是进度本身可能会有所不同,程序员的数学可能过于敏感。
苹果避免任何准确的预测,只是给出了模糊的估计,从而回避了这一点!
(来源:autodesk.com)
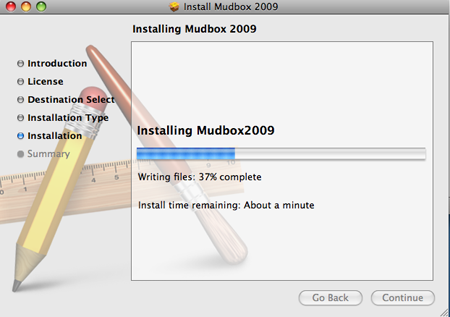{kind=link}
这也很烦人,我有时间快速休息,还是我的任务将在2秒内完成?如果预测太模糊,那么完全做出任何预测都是毫无意义的。
简单但错误的方法
作为第一次通过ETA计算,可能我们都只是做一个函数,如果p是已经完成的小数百分比,t是到目前为止所用的时间,我们输出t *(1-p)/ p为估计需要多长时间才能完成。这个简单的比例可以“正常”,但它也很糟糕,特别是在计算结束时。如果你的缓慢下载速度让副本慢慢地在一夜之间发生,最后在早上,一些东西开始运行,副本开始全速前进,速度提高了100倍,你完成90%的ETA可能会说“1小时”,10秒后来你达到了95%而且ETA会说“30分钟”,这显然是一个令人难以置信的糟糕猜测......在这种情况下,“10秒”是一个非常好的估计。
当发生这种情况时,您可能会考虑更改计算以使用最近速度而非平均速度来估算ETA。您可以获取过去10秒内的平均下载速率或完成率,并使用该速率来预测完成时间。这在之前的一夜之间下载过程中表现相当不错,因为它将在最后给出非常好的最终完成估算。但是这仍然存在很大问题..当你的速率在很短的时间内迅速变化时,它会导致你的ETA大幅反弹,你会得到“在20秒内完成,在2小时内完成,在2秒内完成,在30秒内完成”分钟“快速显示编程耻辱。
实际问题:
在给定计算的时间历史的情况下,计算任务估计完成时间的最佳方法是什么?我不是在寻找GUI工具包或Qt库的链接。我要求算法生成最合理,最准确的完成时间估算值。
你有数学公式的成功吗?某种平均值,可能是使用超过10秒的速率平均值,速率超过1分钟,速率超过1小时?某种人工过滤,例如“如果我的新估计值与之前的估计值相差太大,请将其调低,不要让它反弹太多”?某种奇特的历史分析,您可以将进度与时间进度相结合,找到速率的标准偏差,以便在完成时给出统计误差指标?
你尝试了什么,什么效果最好?
11 个答案:
答案 0 :(得分:31)
原始答案
创建此网站的公司apparently makes一个计划系统,可在员工编写代码的环境中回答此问题。它的工作方式是基于过去的蒙特卡罗模拟未来。
附录:蒙特卡洛的解释
这就是这种算法在你的情况下如何工作的方法:
您将任务建模为一系列微任务,比如1000个。假设一小时后你完成了100个。现在,您通过随机选择90个已完成的微任务,运行模拟剩下的900个步骤,添加它们的时间并乘以10.这里您有一个估计;重复N次,你有剩余时间的N估计值。请注意,这些估计值之间的平均值约为9小时 - 这里没有任何意外。但是,通过向用户呈现所得到的分发,您将诚实地向他传达可能性,例如, '概率为90%,这将需要另外3-15小时'
如果所讨论的任务可以被建模为一堆独立的,随机的微任务,则该算法根据定义产生完整的结果。只有当您知道任务如何偏离此模型时,您才能获得更好的答案:例如,安装程序通常具有下载/解包/安装任务列表,并且一个人的速度无法预测另一个。
附录:简化蒙特卡罗
我不是统计专家,但我认为如果你仔细研究这种方法中的模拟,它总会将正态分布作为大量独立随机变量的总和。因此,您根本不需要执行它。事实上,你甚至不需要存储所有已完成的时间,因为你只需要它们的总和和它们的平方和。
可能不是非常标准的符号,
sigma = sqrt ( sum_of_times_squared-sum_of_times^2 )
scaling = 900/100 // that is (totalSteps - elapsedSteps) / elapsedSteps
lowerBound = sum_of_times*scaling - 3*sigma*sqrt(scaling)
upperBound = sum_of_times*scaling + 3*sigma*sqrt(scaling)
有了这个,你可以输出一条消息,说明事物将从现在开始以[lowerBound,upperBound]之间以一些固定概率结束(应该是大约95%,但我可能错过了一些常数因素)。
答案 1 :(得分:13)
这是我发现的效果很好!对于任务的前50%,您假设速率是恒定的并且推断。时间预测非常稳定,不会反弹太多。
一旦你通过50%,你切换计算策略。你把剩下的工作的一小部分做(1-p),然后回顾你自己进步的历史,找到(通过二分搜索和线性插值)你花了多长时间去做(1-p) -p)百分比并使用 作为您的时间估算完成时间。
所以,如果你现在已完成71%,那么剩下29%。你回顾一下你的历史,并发现你多久以前(71-29 = 42%)完成。将时间报告为您的ETA。
这自然是适应性的。如果你有大量的工作要做,它只会看到完成X工作量所需的时间。最后当你完成99%时,它只使用非常新鲜的,非常近期的估计数据。
它当然不是完美的,但它会平滑地改变,并且在它最有用的时候特别准确。
答案 2 :(得分:8)
我通常使用Exponential Moving Average来计算平滑因子为0.1的操作速度,并使用它来计算剩余时间。这样,所有测量的速度都会对当前的速度产生影响,但是最近的测量结果比远处的测量效果要大得多。
在代码中它看起来像这样:
alpha = 0.1 # smoothing factor
...
speed = (speed * (1 - alpha)) + (currentSpeed * alpha)
如果您的任务规模统一,currentSpeed只是执行上一个任务所花费的时间。如果任务具有不同的大小并且您知道一个任务应该是i,e,是另一个任务的两倍,则可以将执行任务所花费的时间除以其相对大小以获得当前速度。使用speed,您可以通过将剩余时间乘以剩余任务的总大小来计算剩余时间(如果任务是统一的,则只计算其数量)。
希望我的解释很清楚,现在有点晚了。
答案 3 :(得分:7)
虽然所有示例都是有效的,但对于“下载时间”的具体情况,我认为查看现有的开源项目以查看它们的作用是个好主意。
据我所知,Mozilla Firefox是估算剩余时间的最佳选择。
Mozilla Firefox
Firefox会跟踪剩余时间的最后估计值,并通过使用此值和剩余时间的当前估计值,它会在时间上执行平滑功能。 请参阅ETA代码here。这使用先前计算的“{”速度here,并且是过去10次读数的平滑平均值。
这有点复杂,所以解释一下:
- 平均速度基于前一速度的90%和新速度的10%。
- 通过平滑的平均速度计算出估计的剩余时间。
- 使用此预计剩余时间,以及之前估计的剩余时间来创建新的估计剩余时间(以避免跳跃)
Google Chrome
Chrome似乎遍布整个地方,代码shows this。
我喜欢Chrome的一个方面是它们如何格式化剩余时间。 对于> 1小时它说'1小时左' 对于< 1小时说“剩下59分钟” 对于< 1分钟说'52秒左'
您可以看到它的格式here
<强> DownThemAll!的管理器
它没有使用任何聪明的东西,这意味着ETA会在整个地方跳跃。
pySmartDL(python下载器)
获取最近30次ETA计算的平均ETA。听起来像是一种合理的方式。
参见代码here / blob / 916f2592db326241a2bf4d8f2e0719c58b71e385 / pySmartDL / pySmartDL.py#L651)
<强>传送
在大多数情况下给出了相当不错的ETA(除非在开始时,正如预期的那样)。
在过去的5个读数中使用平滑因子,类似于Firefox但不太复杂。从根本上类似于Gooli的答案。
请参阅代码here
答案 4 :(得分:3)
在某些情况下,当您需要定期执行相同的任务时,最好将过去的完成时间用于平均值。
例如,我有一个应用程序通过其COM接口加载iTunes库。在项目数量方面,给定iTunes库的大小通常不会从发射到发射大幅增加,因此在这个示例中,可以跟踪最后三个加载时间和加载速率,然后对其进行平均。计算您当前的ETA。
这比瞬时测量更精确,也可能更加一致。
但是,此方法取决于任务的大小与之前的相对相似,因此这对于解压缩方法或其他任何给定字节流是要压缩的数据的其他方法都不起作用。
只需我0.02美元
答案 5 :(得分:3)
首先,它有助于生成正在运行的移动平均线。这会更加重视最近的事件。
要做到这一点,请保留一堆样本(循环缓冲区或列表),每一个进度和时间。保留最近的N秒样本。然后生成样本的加权平均值:
totalProgress += (curSample.progress - prevSample.progress) * scaleFactor
totalTime += (curSample.time - prevSample.time) * scaleFactor
其中scaleFactor从0 ... 1开始线性地作为过去时间的反函数(因此更重的是更近期的样本)。当然,你可以玩这个加权。
最后,您可以获得平均变化率:
averageProgressRate = (totalProgress / totalTime);
您可以使用它来通过将剩余进度除以此数字来计算出ETA。
然而,虽然这给你一个很好的趋势数,但你有另一个问题 - 抖动。如果由于自然变化,你的进展速度会移动一点(嘈杂) - 例如也许你用它来估算文件下载量 - 你会注意到噪音很容易导致你的ETA跳转,特别是如果它在未来很远(几分钟或更长时间)。
为避免抖动过多地影响您的ETA,您希望此平均变化率数对更新响应缓慢。解决这个问题的一种方法是保持averageProgressRate的缓存值,而不是立即将其更新为您刚刚计算的趋势数,而是将其模拟为具有质量的重物理对象,将模拟的“力”应用于缓慢将其移向趋势数。对于质量,它有一点惯性,不太可能受到抖动的影响。
这是一个粗略的样本:
// desiredAverageProgressRate is computed from the weighted average above
// m_averageProgressRate is a member variable also in progress units/sec
// lastTimeElapsed = the time delta in seconds (since last simulation)
// m_averageSpeed is a member variable in units/sec, used to hold the
// the velocity of m_averageProgressRate
const float frictionCoeff = 0.75f;
const float mass = 4.0f;
const float maxSpeedCoeff = 0.25f;
// lose 25% of our speed per sec, simulating friction
m_averageSeekSpeed *= pow(frictionCoeff, lastTimeElapsed);
float delta = desiredAvgProgressRate - m_averageProgressRate;
// update the velocity
float oldSpeed = m_averageSeekSpeed;
float accel = delta / mass;
m_averageSeekSpeed += accel * lastTimeElapsed; // v += at
// clamp the top speed to 25% of our current value
float sign = (m_averageSeekSpeed > 0.0f ? 1.0f : -1.0f);
float maxVal = m_averageProgressRate * maxSpeedCoeff;
if (fabs(m_averageSeekSpeed) > maxVal)
{
m_averageSeekSpeed = sign * maxVal;
}
// make sure they have the same sign
if ((m_averageSeekSpeed > 0.0f) == (delta > 0.0f))
{
float adjust = (oldSpeed + m_averageSeekSpeed) * 0.5f * lastTimeElapsed;
// don't overshoot.
if (fabs(adjust) > fabs(delta))
{
adjust = delta;
// apply damping
m_averageSeekSpeed *= 0.25f;
}
m_averageProgressRate += adjust;
}
答案 6 :(得分:2)
你的问题很好。如果问题可以分解为具有精确计算的离散单元,则通常效果最佳。不幸的是,即使您正在安装50个组件,也可能不是这种情况,每个组件可能是2%,但其中一个组件可能很大。我取得了一定成功的一件事是为cpu和磁盘计时,并根据观察数据给出一个不错的估计。知道某些检查点确实是点x,这使您有机会纠正环境因素(网络,磁盘活动,CPU负载)。然而,由于其依赖于观测数据,该解决方案本质上不是通用的。使用诸如rpm文件大小之类的辅助数据帮助我使我的进度条更准确,但它们绝不是防弹。
答案 7 :(得分:1)
统一平均值
最简单的方法是线性预测剩余时间:
t_rem := t_spent ( n - prog ) / prog
其中t_rem是预测的ETA,t_spent是自操作开始以来经过的时间,prog已完成的微量任务数量n 。要解释 - n可能是要处理的表中的行数或要复制的文件数。
这种方法没有参数,人们不必担心衰减指数的微调。由于所有样本对估计值的贡献相等,所以权衡很少适应不断变化的进度,而只是满足最近的样本应该比旧的样本更重,这导致我们
指数平滑率
其中标准技术是通过平均先前的点测量来估计进度率:
rate := 1 / (n * dt); { rate equals normalized progress per unit time }
if prog = 1 then { if first microtask just completed }
rate_est := rate; { initialize the estimate }
else
begin
weight := Exp( - dt / DECAY_T );
rate_est := rate_est * weight + rate * (1.0 - weight);
t_rem := (1.0 - prog / n) / rate_est;
end;
其中dt表示上次完成的微任务的持续时间,并且等于自上次进度更新以来经过的时间。请注意weight不是常数,必须根据观察到某个rate的时间长度进行调整,因为我们观察到某个速度的时间越长,之前测量的指数衰减就越高。常数DECAY_T表示样本的权重减少因子 e 的时间长度。 SPWorley 本人建议对 gooli 的提案进行类似修改,尽管他将其应用于错误的术语。等距测量的指数平均值为:
Avg_e(n) = Avg_e(n-1) * alpha + m_n * (1 - alpha)
但是,如果样本不是等距的,那么在典型的进度条中的情况就是如此?考虑到上面的alpha只是一个经验商,其真实值是:
alpha = Exp( - lambda * dt ),
其中lambda是指数窗口的参数,dt是自上一个样本以来的变化量,不需要时间,而是任何线性和附加参数。 alpha对于等距测量是恒定的,但随dt而变化。
标记此方法依赖于预定义的时间常量,并且不能及时扩展。换句话说,如果通过常数因子均匀地减慢完全相同的过程,则基于速率的滤波器将对信号变化成比例地更敏感,因为每个步骤weight将减小。但是,如果我们想要一个独立于时间尺度的平滑,我们应该考虑
缓慢的指数平滑
这基本上是因为weight增加了prog因为slowness := n * dt; { slowness is the amount of time per unity progress }
if prog = 1 then { if first microtask just completed }
slowness_est := slowness; { initialize the estimate }
else
begin
weight := Exp( - 1 / (n * DECAY_P ) );
slowness_est := slowness_est * weight + slowness * (1.0 - weight);
t_rem := (1.0 - prog / n) * slowness_est;
end;
的增加而增加的简化,因此速率的平滑是颠倒的:
DECAY_P无量纲常数display: none;表示两个样本之间的归一化进度差异,其中权重的比率为1到 e 。换句话说,此常量确定进度域中平滑窗口的宽度,而不是时域中的宽度。因此,该技术与时间尺度无关,并具有恒定的空间分辨率。
进一步的研究:自适应指数平滑
您现在可以尝试adaptive exponential smoothing的各种算法。只记得将其应用于慢度而不是评价。
答案 8 :(得分:0)
我总是希望这些东西可以告诉我一个范围。如果它说“这项任务最有可能在8分钟到30分钟之间完成”,那么我就知道应该采取什么样的休息方式。如果它在整个地方反弹,我很想观看它直到它安定下来,这是浪费时间。
答案 9 :(得分:0)
我已经尝试并简化了您的“简单”/“错误”/“确定”公式,它最适合我:
t / p - t
在Python中:
>>> done=0.3; duration=10; "time left: %i" % (duration / done - duration)
'time left: 23'
与(dur *(1-done)/ done)相比,保存了一个op。并且,在您描述的边缘情况下,可能忽略对话30分钟,在等待整晚后几乎不重要。
Comparing这个the one used by Transmission的简单方法,我发现它是up to 72% more accurate.
答案 10 :(得分:-4)
我没有出汗,它只是应用程序的一小部分。我告诉他们发生了什么,让他们去做别的事。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?