消除结果集中的部分重复行
我有一个返回类似下面结果集的查询(实际上它更大,数千行):
A | B | C | D
-----|----|----|-----
1 NULL | d0 | d0 | NULL
2 NULL | d0 | d1 | NULL
3 NULL | d0 | d2 | a0
4 d0 | d1 | d1 | NULL
5 d0 | d2 | d2 | a0
其中两行被认为是重复的,1和2,因为A,B和D是相同的。为了消除这种情况,我可以使用SELECT DISTINCT A, B, D,但是我的结果集中没有C列。 C列是第3,4和5行的必要信息。
那么我如何从上面的结果集到此结果集(C4中出现的结果也可以是NULL而不是d1):
A | B | C | D
-----|----|------|-----
1 NULL | d0 | NULL | NULL
3 NULL | d0 | d2 | a0
4 d0 | d1 | d1 | NULL
5 d0 | d2 | d2 | a0
5 个答案:
答案 0 :(得分:5)
DECLARE @YourTable TABLE (
A VARCHAR(2)
, B VARCHAR(2)
, C VARCHAR(2)
, D VARCHAR(2))
INSERT INTO @YourTable VALUES (NULL, 'd0', 'd0', NULL)
INSERT INTO @YourTable VALUES (NULL, 'd0', 'd1', NULL)
INSERT INTO @YourTable VALUES (NULL, 'd0', 'd2', 'a0')
INSERT INTO @YourTable VALUES ('d0', 'd1', 'd1', NULL)
INSERT INTO @YourTable VALUES ('d0', 'd2', 'd2', 'a0')
SELECT A, B, C = MIN(C), D
FROM @YourTable
GROUP BY A, B, D
SELECT A, B, CASE WHEN MIN(C) = MAX(C) THEN MIN(C) ELSE NULL END, D
FROM @YourTable
GROUP BY A, B, D
SELECT A, B, CASE WHEN MIN(COALESCE(C, 'dx')) = MAX(COALESCE(C, 'dx')) THEN MIN(C) ELSE NULL END, D
FROM @YourTable
GROUP BY A, B, D
答案 1 :(得分:2)
使用Dense_Rank()按A,B和D分区 (感谢Lieven,对于临时表查询,我必须使用它来使演示保持一致;))
根据MSDN,
行的等级是一行加上有问题的行之前的不同等级的数量
按A, B, C进行分区,然后按A, B, C, D排序,将为A, B, D定义唯一性的第一个不同值提供1的等级。这就是1过滤的地方。
其中DenseRank = 1
结果如下
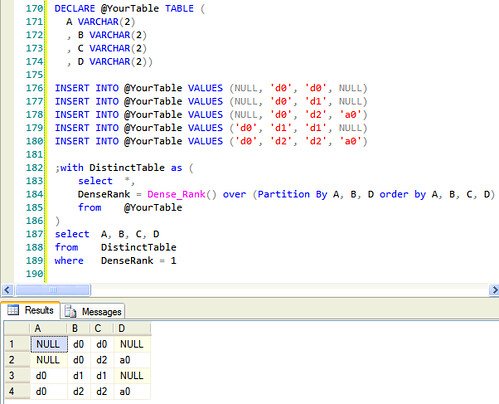
以下是代码:
DECLARE @YourTable TABLE (
A VARCHAR(2)
, B VARCHAR(2)
, C VARCHAR(2)
, D VARCHAR(2))
INSERT INTO @YourTable VALUES (NULL, 'd0', 'd0', NULL)
INSERT INTO @YourTable VALUES (NULL, 'd0', 'd1', NULL)
INSERT INTO @YourTable VALUES (NULL, 'd0', 'd2', 'a0')
INSERT INTO @YourTable VALUES ('d0', 'd1', 'd1', NULL)
INSERT INTO @YourTable VALUES ('d0', 'd2', 'd2', 'a0')
;with DistinctTable as (
select *,
DenseRank = Dense_Rank() over (Partition By A, B, D order by A, B, C, D)
from @YourTable
)
select A, B, C, D
from DistinctTable
where DenseRank = 1
答案 2 :(得分:0)
可能是子查询?
SELECT A,B,C,D FROM table1 WHERE EXISTS(SELECT DISTINCT A,B,D FROM table1);
答案 3 :(得分:0)
如果你在表格中有一个唯一的ID,那么我会选择这样的东西:
SELECT A,B,C,D FROM table WHERE id IN (SELECT DISTINCT A,B,D)
问题是你总是得到C的第一个值,而不是第一个有值的值。
答案 4 :(得分:0)
你在A和D中有NULL的事实对任何EXISTS都很重要。
C上的任何MIN / MAX解决方案可能都不会给你我想要的NULL。否则,使用MIN(C)和一个简单的分组。
您必须首先提取唯一键(A,B,D),然后使用它来确定再次提取行并确定如何处理C
DECLARE @TheTable TABLE (
A varchar(2) NULL,
B varchar(2) NULL,
C varchar(2) NULL,
D varchar(2) NULL
)
INSERT INTO @TheTable VALUES (NULL, 'd0', 'd0', NULL)
INSERT INTO @TheTable VALUES (NULL, 'd0', 'd1', NULL)
INSERT INTO @TheTable VALUES (NULL, 'd0', 'd2', 'a0')
INSERT INTO @TheTable VALUES ('d0', 'd1', 'd1', NULL)
INSERT INTO @TheTable VALUES ('d0', 'd2', 'd2', 'a0')
SELECT DISTINCT
T.A,
T.B,
CASE Number WHEN 1 THEN T.C ELSE NULL END,
T.D
FROM
(SELECT
COUNT(*) AS Number,
A, B, D
FROM
@TheTable
GROUP BY
A, B, D
) UQ
JOIN
@TheTable T ON ISNULL(T.A, '') = ISNULL(UQ.A, '') AND ISNULL(T.B, '') = ISNULL(UQ.B, '') AND ISNULL(T.D, '') = ISNULL(UQ.D, '')
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?