投掷硬币来获得随机位? 或者扔掉一个来获得1到6的随机整数? 或者从洗牌的卡片中取出卡片以获得1到52之间的数字? 。
。
。
或者它可以像我们一样思考,还是像我们一样拥有智慧?
显然,上述例子不能成为生成随机数据的方法。
那么软件库如何在给定范围内生成random个数字?
哪个更随机:人工或软件生成?
答案 0 :(得分:11)
(注意:我忽略了在你的问题中使用“编译器”一词,因为它实际上没有任何意义。相反,这通常是关于计算中的随机[和伪随机]数字。他们的用途。)
你永远不能拥有确定性过程的真随机数,这就是为什么计算机不适合生成它们(因为CPU只能以确定的方式翻转位)。大多数语言,框架和库都使用所谓的Pseudo-random number generators(PRNG)。那些采用种子,它是一种初始状态向量,可以是单个数字或数字数组,并从那里生成一系列看似随机的值。结果通常满足某些统计测量,但不是完全随机的,因为相同的种子将产生完全相同的序列。
最简单的PRNG之一就是所谓的Linear Congruential Generator(LCG)。它只有一个数字作为状态(最初是种子)。然后对于每个连续的返回值,公式如下所示:
LCG formula: x_(n+1)=a⋅x_n+b (modc ) http://hypftier.de/dump/SO-6593636-lcg.png
其中 a , b 和 c 是生成器的常量。 c 通常是2的幂,例如2 32 ,因为它易于实现(自动完成)和快速。但是,为 a 和 b 找到好的值很难。作为一个最简单的例子,当使用 a = 2且 b = 0时,您可以看到结果值永远不会是奇数。这限制了发电机可以非常严重地产生的值的范围。一般来说,LCG是一个非常古老的概念,长期被更好的发电机取代,所以不要使用它们,除非在极其有限的环境中(尽管通常嵌入式系统可以处理更好的发电机而没有问题) - MT19937或其对于那些根本不想担心伪随机数属性的人来说,WELL generators通常要好得多。
PRNG的一个主要应用是模拟。由于PRNG可以给出统计属性和的估计或保证,因此实验可以完全由于种子的性质而重复,因此它们在这里做得很好。想象一下,您正在发表论文,并希望其他人复制您的结果。使用硬件RNG(如下所示),除了包含您使用的每个随机数之外,您没有其他选择。对于可以轻松使用数十亿或更多数字的蒙特卡罗模拟,这是不太可行的。
然后有用于加密应用程序的随机数生成器,例如用于保护您的SSL连接。这里的例子是Windows'CryptGenRandom或Unix的/dev/urandom。那些通常也一个PRNG,但他们使用所谓的“熵池”进行播种,其中包含不可预测的值。这里的要点是产生不可预测的序列,即使相同的种子仍然会产生相同的序列。为了尽量减少攻击者猜测序列的影响,他们需要定期重新播种。熵池是从系统中的各个点收集的:事件,例如输入,网络活动等。有时它也被初始化,整个系统中的内存位置被假定为包含垃圾。但是,如果已经完成,必须注意确保熵池确实包含不可预测的内容。 Something that Debian got wrong in OpenSSL a few years ago.
您也可以直接使用熵池来获取随机数(例如Linux的/dev/random; FreeBSD使用与/dev/random相同的算法和/dev/urandom),但是你不要太过分了,一旦它空了,需要一段时间才能补充。这就是为什么上面提到的算法通常用于将小熵扩展到更大的体积。
然后是基于硬件的随机数发生器,它使用不可预测的自然过程,例如放射性衰减或电线中的电噪声。那些是需要许多“真正”随机数的最苛刻的应用程序,并且能够每秒产生几百MiB的随机性,通常(好吧,数据点是几年,但我怀疑它可以做多少现在更快。)
你可以通过编写一个程序来拍摄这样的东西,这个程序从带有镜头盖的网络摄像头开始(当时只有噪声,或者当没有实际输入时从音频输入)。对于一点点黑客行为来说这些都很好,但通常不会生成好的随机数,因为它们是有偏差的,即在比特流中为零,而不是以相同的频率表示(或者,更进一步,序列00,01,10和11不会以相同的频率生成...您也可以为更大的序列执行此操作。因此,实际硬件RNG的一部分用于确保结果值满足某些统计分布属性。
有些人actually throw dice to get random dice rolls甚至take this into overdrive。人类制造very bad random number generators。
答案 1 :(得分:3)
编译器在要求随机数方面绝对没有任何作用。编译器只生成你的代码,调用一些返回随机数的代码。现在调用随机数的“其他代码”可能是:
在情况(1)和(2)中,它主要是伪随机算法,你得到的数字并不是真正随机的。如果它是标准库(如cmath或math.h)的一部分,则无法确定结果值是伪随机的,因为标准仅指定定义而不是实现。
编辑:库是stdlib.h,它总是一个假随机数,正如乔伊和菲涅尔所指出的那样。阅读评论,了解他们的答案详情。我为这个错误道歉,我同意我应该知道比回答本能更好。
可以使用特殊库,这些库可能具有其他算法的特殊实现,例如Mersenne Twister算法。此外,它们可能只是可以生成随机数的硬件驱动程序。硬件随机数生成器返回一些“真实”的随机数http://en.wikipedia.org/wiki/Hardware_random_number_generator。
标准库中的随机数算法最终映射到OS上的系统调用。因此,在Linux上,您可能只是在阅读/dev/random或/dev/urandom(或者您也可能在自己的代码中执行相同的操作)。
另请注意,可以在不使用专用硬件或某些专用服务的情况下实现真正的随机性。 /dev/random和/dev/urandom提供随机数,对于所有意图和目的都可以认为是真实的。
编辑:一些特殊的库或您自己的代码甚至可能使用随机数的网络服务(其中许多提供真正的随机数)。
答案 2 :(得分:2)
您的计算机生成的这些数字不是“随机”的真实定义的“随机”。它们是伪随机的 - 有一种生成数字的算法。您可以在此处详细了解这些数字:http://en.wikipedia.org/wiki/Pseudorandom_number_generator
答案 3 :(得分:2)
Google随机数生成: http://en.wikipedia.org/wiki/Random_number_generation
惠斯特不是真正的随机我会选择一台计算机来随机生成一个随机数 人类是随机性的垃圾,因为它们以可预测的方式表现
答案 4 :(得分:1)
见Joeys的回答。还存在 hardware random generators ,它使用一些物理过程来生成nouse,并且可以插入到您的计算机中以用于“真正的”随机数生成(在数学意义上,“真实” “是多余的”)。
在Unix-like下,可以在/ dev / random和/ dev / urandom中查询此类设备。
有关在线示例,请参阅http://www.random.org/。
答案 5 :(得分:0)
这是特定于Linux的,但是对“真实”随机性有一些操作系统支持:/dev/random和/dev/urandom。你读这些就像普通文件一样。
random是从物理过程中收集到的真实随机性,例如硬件中的不规则延迟 - 当您阅读它时它已耗尽且加密安全。
urandom是一个无限的伪随机源,它源自random,几乎肯定比你的C库PRNG更高质量。
答案 6 :(得分:-3)
当然,人类更随机。编译器(实际上,由编译器编译的随机模块)仅使用一些伪随机(实际上不是随机的,可能的)算法来生成随机数。
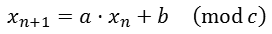{kind=link}