使用请求和bs4从网页获取链接
我正在尝试从https://www.supremecommunity.com/season/spring-summer2020/droplists/
中获取最新投稿清单的链接如果右键单击“最新”并单击“检查”,则会看到以下内容:
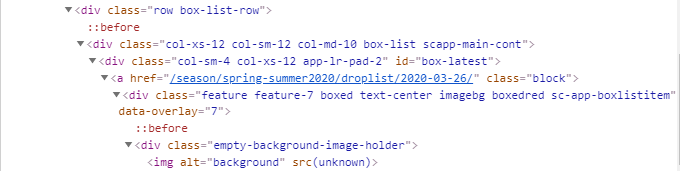
该链接每周都会更改,因此我正尝试从该页面中拉出它。
当我这样做
import requests
from bs4 import BeautifulSoup
url = "https://www.supremecommunity.com/season/spring-summer2020/droplists/"
r = requests.get(url)
soup = BeautifulSoup(r.text,"html.parser")
my_data = soup.find('div', attrs = {'id': 'box-latest'})
我得到:
div class="col-sm-4 col-xs-12 app-lr-pad-2" id="box-latest">
<a class="block" href="/season/spring-summer2020/droplist/2020-03-26/">
<div class="feature feature-7 boxed text-center imagebg boxedred sc-app-boxlistitem" data-overlay="7">
<div class="empty-background-image-holder">
<img alt="background" src=""/>
</div>
<h2 class="pos-vertical-center">Latest</h2>
</div>
</a>
</div>
我如何才能拔出"/season/spring-summer2020/droplist/2020-03-26/"部分?
1 个答案:
答案 0 :(得分:0)
import requests
from bs4 import BeautifulSoup
r = requests.get(
"https://www.supremecommunity.com/season/spring-summer2020/droplists/")
soup = BeautifulSoup(r.content, "html.parser")
print(soup.find("div", id="box-latest").contents[1].get("href"))
输出:
/season/spring-summer2020/droplist/2020-03-26/
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?