pyspark跳过了一些导入阶段,该阶段应处理新数据,并且不应跳过
我的核心pyspark代码在forloop中。
global_v = np.random.rand(feature_num, vec_dim)
global_v_bc = sc.broadcast(global_v)
for i in range(epoch):
s1 = train_rdd.repartition(500)\
.mapPartitions(lambda x:fit(x, global_v_bc))\
.reduceByKey(lambda x,y:[x[0]+y[0], x[1]+y[1], x[2]+y[2]])\
.map(lambda x:x[1])
s2 = s1.take(1)[0]
s1.unpersist()
logging.info("epoch {} train-loss:{}".format(i, s2[0]/s2[1]))
global_v_bc.destroy()
global_v_bc = sc.broadcast(s2[2]/s2[1])
这是一个简单的fm模型。它可以在每个分区中更新v并重新广播以进行下一个循环,但是在运行时跳过了许多阶段。
有人可以帮我吗?
这是Web UI内容:
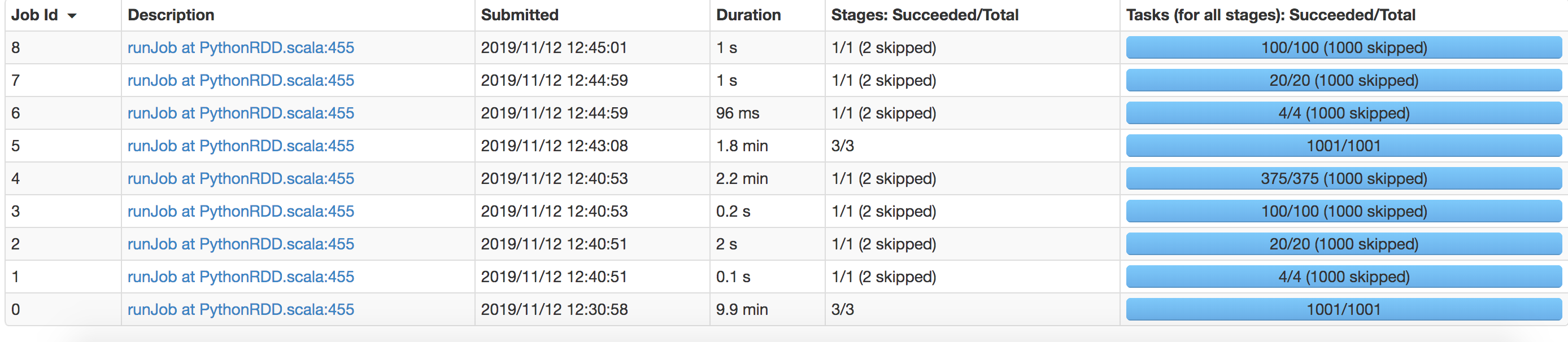

0 个答案:
没有答案
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?